Die fortschreitende Digitalisierung und der stetig wachsende Datenbestand verlangen innovative Ansätze, um Wissen präzise und kontextbezogen auszuwerten. GraphRAG-Systeme – also Graph-basierte Retrieval-Augmented Generation Systeme – verbinden leistungsfähige große Sprachmodelle (LLMs) mit strukturierten Daten in Form von Wissensgraphen. Diese Kombination erlaubt eine erheblich verbesserte Antwortgenauigkeit und Kontextsensitivität, indem die Stärken beider Technologien genutzt werden. Entscheidend für den Erfolg eines GraphRAG-Systems ist dabei die richtige Wahl der Frameworks, Graphdatenbanken und Tools, die zusammen eine funktionale und skalierbare Architektur ermöglichen. Die Basis für jedes GraphRAG ist die Modellierung und Strukturierung der Daten, denn ohne sauberes und gut organisiertes Datenmaterial kann keine effiziente Suche oder Generierung stattfinden.
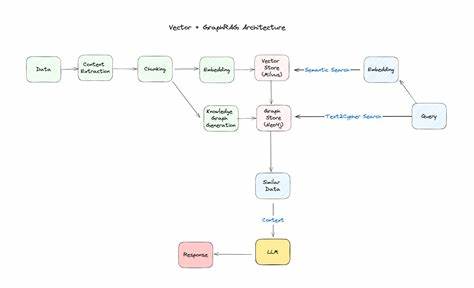
Hierbei spielen In-Memory-Datenstrukturen eine bedeutende Rolle, gerade wenn die Datenmenge überschaubar und dynamisch ist. Graphstrukturen eignen sich hervorragend für schnelle Traversierungen und Verarbeitung mehrschrittiger Zusammenhänge, während invertierte Indizes sich eher für Schlüsselwort- oder dokumentbasierte Abfragen anbieten. Die Wahl der Datenbank ist stark an den Anwendungsfall gebunden: Viele GraphRAG-Projekte profitieren von speziell für Echtzeit und graphbasierte Analysen optimierten In-Memory-Graphdatenbanken wie Memgraph. Memgraph hebt sich durch seine Fähigkeit hervor, komplexe Algorithmen wie Louvain und Leiden effizient auszuführen, und unterstützt so dynamische Systeme, die sich ständig ändernde Datenaktualisierungen benötigen. Daneben existieren Vektor-Datenbanken, die eine semantische Suche erlauben, also die Ähnlichkeit von eingebetteten Informationen erfassen.
Dienste wie Weaviate oder Pinecone bieten leistungsstarke Suchfunktionen auf Basis von Embeddings, die durch LLMs generiert werden. Sie eignen sich hervorragend zur Ergänzung von Graphdatenbanken, insbesondere wenn der Fokus auf semantische Suchanfragen liegt, die über bloße Schlüsselwortübereinstimmungen hinausgehen. Klassische relationale Datenbanken haben in diesem Kontext eine eher untergeordnete Rolle, da ihnen die Fähigkeit zu mehrstufiger Pfaddurchquerung und zum Erfassen der Vernetzungen zwischen Entitäten fehlt. Für die Indexierung und Textsuche großer Datensätze empfiehlt sich zudem der Einsatz von Suchmaschinen wie Elasticsearch, die sich im Zusammenspiel mit Graphdatenbanken als hybride Lösungen etablieren. Die Suche und Auswahl relevanter Informationen innerhalb eines GraphRAG-Systems lässt sich in zwei wesentliche Methoden unterteilen: Zum einen der Pivot-Search-Ansatz, der Schlüsselinformationen anhand ähnlicher Merkmale aus der Anfrage identifiziert.
Diese Suche kann als exakte Schlüsselwortsuche erfolgen, aber auch breiter durch Textsuche oder anhand von Embeddings im Vektorraum. Darüber hinaus gibt es raumbezogene Geo-Suchen, die bei standortgebundenen Anfragen zum Einsatz kommen. Zum anderen ist die Relevance Expansion ein zentraler Prozess, bei dem verwandte und verbundene Daten ergänzt werden, um das Kontextverständnis zu vertiefen. Techniken hierfür sind unter anderem Community-Detection-Algorithmen wie Louvain und Leiden, die Cluster in den Daten sichtbar machen. Zusätzlich spielt der PageRank-Algorithmus eine Rolle, der Knoten nach ihrer Bedeutung innerhalb des Netzwerks priorisiert und somit relevante Informationen priorisieren kann.
Die graphbasierte Traversierung erlaubt es, mehrstufige Verbindungen etwa durch eins- oder mehrfache Nachbarschaftssuchen auszuloten. Im Zusammenspiel bilden diese Such- und Erweiterungsmethoden die Grundlage für eine fundierte Kontextanreicherung der Nutzerabfragen. Memgraph als zentrale Komponente eines GraphRAG-Systems bietet auf Basis seiner In-Memory Technologie und effizienten Algorithmen genau das richtige Fundament. Der typische Workflow beginnt mit der Datenmodellierung, bei der Entitäten und deren Beziehungen als Schema im Graph abgebildet werden. In der Suche folgt zunächst eine Pivot-Suche auf Basis der Anfrage mittels Keyword-, Text- oder Vektorsuche.
Durch Relevance Expansion werden zusätzlich verbundene Datenelemente erschlossen. Dieses zusammengestellte Datenmaterial wird dann an das LLM übergeben, das daraus eine kontextuell fundierte Antwort erzeugt. Die Integration mit Frameworks wie LangChain oder LlamaIndex erleichtert dabei den nahtlosen Anschluss an die Sprachmodelle. Unternehmen aus verschiedensten Branchen profitieren bereits von diesem Ansatz. In der medizinischen Forschung etwa nutzt Cedars-Sinai Memgraph für Knowledge-Driven AutoML-Modelle bei Alzheimer, während Precina Health auf GraphRAG aufbaut, um das Management von Typ-2-Diabetes mit Echtzeitdaten signifikant zu verbessern.
Auch im Bereich von KI-Chatbots bewährt sich die Kombination aus Graphdatenbanken und LLMs, um Antworten effizienter und zielgerichteter zu gestalten. Für manche Anwendungen empfiehlt sich ein hybrides System, bei dem Graphdatenbanken, Vektor-Datenbanken und Suchmaschinen miteinander kombiniert werden. Dabei übernimmt die Graphdatenbank die Aufgabe der Beziehungserfassung und komplexen Reasoning-Prozesse. Die Vektor-Datenbank optimiert semantische Suchen, während Suchmaschinen wie Elasticsearch für effiziente Textindizierung und -suche sorgen. Diese hybride Architektur bietet ein äußerst flexibles und leistungsstarkes Fundament, das sich an verschiedene Use Cases, Datenvolumen und Echtzeitanforderungen anpassen lässt.