Die rasante Entwicklung Künstlicher Intelligenz (KI) hat zahlreiche Bereiche revolutioniert, unter anderem auch die chemische Wissenschaft. Große Sprachmodelle (LLMs, Large Language Models) wie GPT-4 zeigen beeindruckende Leistungen bei der Verarbeitung und Erzeugung natürlicher Sprache. In der Chemie werden sie zunehmend als Werkzeuge zur Unterstützung von Forscherinnen und Forschern eingesetzt, doch wie gut sind diese maschinellen Systeme tatsächlich im Vergleich zu menschlichen Chemikern? Welche Kompetenzen besitzen sie in Bezug auf chemisches Wissen und komplexe Problemlösungskompetenzen? In den letzten Jahren hat sich eine intensive Debatte darüber entwickelt, ob und inwieweit KI-Modelle relevante chemische Expertise besitzen und wie sie deren Arbeit ergänzen oder sogar übertreffen können. Aktuelle Forschungsarbeiten, insbesondere die von Adrian Mirza und Kollegen veröffentlichte Studie „A framework for evaluating the chemical knowledge and reasoning abilities of large language models against the expertise of chemists“ (2025), bieten eine klare Grundlage für die Vergleichsanalyse von LLMs und menschlichem Expertenwissen. Dabei zeigt sich, dass bestimmte KI-Systeme in vielen chemischen Fragestellungen sogar menschliche Experten übertreffen können, gleichzeitig aber auch wesentliche Einschränkungen aufweisen, die einen vorsichtigen Einsatz erfordern.
Die Entwicklung großer Sprachmodelle basiert auf der Verarbeitung riesiger Mengen an Textdaten, inklusive Fachliteratur, Lehrbüchern und wissenschaftlichen Veröffentlichungen. Dies ermöglicht den Modellen, eine beeindruckende Bandbreite an Wissen zu internalisieren und darauf zurückzugreifen. Anders als herkömmliche datenbasierte Modelle, die oft auf einzelne, klar definierte Eigenschaften oder Reaktionsvorhersagen spezialisiert sind, können LLMs komplexe Fragen in natürlicher Sprache beantworten, komplexe Sachverhalte erläutern und sogar neue Hypothesen generieren. Die von Mirza et al. entwickelte Benchmark namens ChemBench stellt dafür einen entscheidenden Schritt dar: Sie umfasst mehr als 2700 Fragen aus verschiedensten Gebieten der Chemie, von Grundlagenwissen bis zu komplexem naturwissenschaftlichen Denken und Intuition.
Eine der herausragenden Erkenntnisse aus der Studie ist, dass die besten aktuellen LLMs, beispielsweise das Modell „o1-preview“, im Durchschnitt sogar besser abschneiden als die besten befragten Chemiker. Diese Leistung erstreckt sich über diverse Themengebiete und Fragestellungen, von allgemeinen chemischen Konzepten über technische Chemie bis hin zu spezifischen Anwendungen. Allerdings offenbaren die Modelle auch deutliche Schwächen, insbesondere wenn es um Basiswissen geht, das exaktes Faktenwissen erfordert, sowie um komplexe Berechnungen und strukturelle Analysen, die chemisches Vorstellungsvermögen und räumliches Denken erfordern. Chemische Intuition, die häufig ein Produkt jahrelanger praktischer Erfahrung ist, konnten die KI-Modelle bislang kaum überzeugend nachahmen. Interessanterweise reagiert die Leistungsfähigkeit der Sprachmodelle stark auf die Art der gestellten Fragen.
Während sie bei Multiple-Choice-Aufgaben und standardisierten Prüfungsfragen meist gute bis sehr gute Ergebnisse erzielen, fällt die Performance bei offenen Fragen und in Szenarien, die mehrere logische Schritte und strukturierte chemische Visualisierungen erfordern, deutlich ab. Hier zeigt sich ein zentraler Unterschied zur menschlichen Expertise: Chemiker kombinieren ihre Wissensbasis mit kreativer Problemlösung und können molekulare Strukturen intuitiv erfassen, während Sprachmodelle oft auf statistische Korrelationen in den Trainingsdaten angewiesen sind. Zudem stehen große Sprachmodelle noch vor der Herausforderung, ihre Antworten sicher und zuverlässig zu validieren, da sie manchmal übermäßig selbstbewusste, aber falsche Antworten geben. Ein weiteres bemerkenswertes Ergebnis der Untersuchung ist die begrenzte Fähigkeit der Modelle, ihre eigene Unsicherheit angemessen zu reflektieren. Während ein kompetenter Chemiker meist intuitiv einschätzen kann, wann er eine zuverlässige Antwort liefern kann und wann nicht, fehlt vielen aktuellen Sprachmodellen dieses Bewusstsein.
In Anwendungen, in denen Sicherheit und Risikobewertung essenziell sind – etwa bei der Bewertung toxikologischer Risiken oder chemischer Sicherheit – kann dies problematisch sein. Die Forschung zeigt, dass verbalisierte Vertrauenswerte von Modellen oft schlecht kalibriert sind und somit nicht zuverlässig als Indikatoren für korrekte Antworten genutzt werden können. Diese Diskrepanz unterstreicht die Notwendigkeit eines typischen menschlichen Kontrollinstanz, wenn KI-Modelle im Alltag eingesetzt werden. Im Unterbereich der analytischen Chemie, etwa bei der Interpretation von Kernspinresonanzspektren (NMR), kämpfen die LLMs noch mit relativen Schwierigkeiten. Selbst hochskalierte Modelle erzielen hier nur eine Trefferquote von etwa 22 Prozent bei der korrekten Vorhersage von Spektrumssignalen.
Das liegt oft daran, dass komplexe molekulare Topologien und Symmetrieüberlegungen verlangt werden, die von den Modellen lediglich durch Textrepräsentationen wie SMILES kodiert werden, was nicht dasselbe ist wie ein visuelles oder dreidimensionales Verständnis. Im Gegensatz dazu können menschliche Chemiker molekulare Modelle visualisieren und dadurch genauere Schlüsse ziehen. Die Erkenntnisse werfen gleichzeitig auch Fragen an die Chemieausbildung und die Prüfungsformate auf. Klassische Multiple-Choice-Prüfungen oder reproduktives Auswendiglernen werden durch die Möglichkeit der Nutzung von KI zunehmend infrage gestellt. Während LLMs Probleme des traditionellen Wissenserwerbs sehr gut meistern, benötigen Studierende und Fachkräfte künftig mehr Kompetenzen im kritischen Denken, komplexen Experimentieren und in der Interpretation von Daten.
Die Ausbildung könnte sich somit von einem Fokus auf reine Faktenvermittlung hin zu einer stärkeren Förderung von Problemlösefähigkeit und Kreativität entwickeln, die durch KI-gestützte Assistenzsysteme ergänzt wird. Die Studie von Mirza und Team legt zudem offen, dass das volle Potenzial von LLMs erst dann ausgeschöpft werden kann, wenn sie mit spezialisierten, hochqualitativen chemischen Datenbanken verknüpft werden. Während die meisten Modelle hauptsächlich auf wissenschaftlichen Veröffentlichungen und allgemeinen Texten trainiert sind, benötigen sie Zugang zu spezialisierten Datenquellen wie PubChem oder Sicherheitsdatenbanken, um präzise Fakten zu liefern. Die Einbindung solcher Datenbanken in den KI-Workflow könnte auch dazu beitragen, die Zuverlässigkeit und Sicherheit der Antworten zu steigern und damit die Eignung der Modelle für kritische Anwendungen verbessern. Zukunftsweisend ist außerdem die Entwicklung sogenannter agentischer Systeme, bei denen LLMs mit externen Werkzeugen wie Web-Suchdiensten oder numerischen Taschenrechnern kombiniert werden.
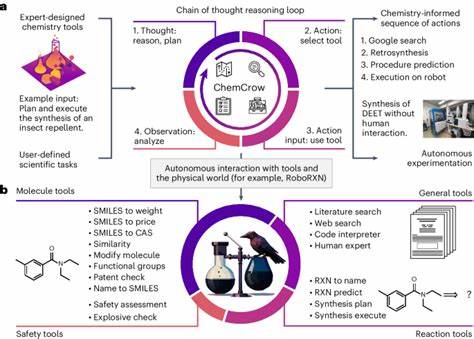
Diese Multi-Tool-gestützten Modelle, etwa PaperQA2, verbinden die Fähigkeit zu flexibler Informationsabfrage mit den generativen Stärken der Sprachmodelle. Dabei kann die Kombination komplexer kognitiver Fertigkeiten die Grenzen einzelner Modelle deutlich erweitern. Allerdings ist auch hier eine genaue Überprüfung notwendig, wie gut solche Systeme chemisches Wissen integrieren und anwenden können. Trotz der ökonomischen und zeitlichen Vorteile, die LLMs in der chemischen Forschung und Lehre bieten, bleiben ethische und sicherheitsrelevante Fragen zentral. Der potenzielle duale Nutzen der Technologie – zum Beispiel bei der Synthese gefährlicher oder toxischer Verbindungen – fordert eine verantwortungsvolle Entwicklung und Regulierung der Modelle.
Zugleich wächst die Nutzerbasis schnell und umfasst zunehmend auch Laien, Studierende und weniger erfahrene Personen, die sich auf die Leistungen der KI verlassen. Fehlende oder falsche Sicherheitsinformationen könnten gefährliche Folgen haben, wenn die Modelle falsche Einschätzungen treffen und diese ungeprüft übernommen werden. Die Veröffentlichung von Benchmarking-Frameworks wie ChemBench ermöglicht eine transparente und systematische Bewertung von KI-Systemen in der Chemie. Durch die offene Bereitstellung von Fragen, Antworten und Auswertungskriterien fördern sie die Vergleichbarkeit und Weiterentwicklung von Modellen. Darüber hinaus unterstreicht die Forschung die Bedeutung der Kooperation zwischen KI-Entwicklern, Chemikern und Bildungsexperten, um eine sinnvolle Integration von Maschinenintelligenz in wissenschaftliche Arbeitsprozesse zu gewährleisten.
Abschließend lässt sich festhalten, dass große Sprachmodelle mittlerweile beeindruckende Fähigkeiten im Bereich chemisches Wissen und logisches Denken aufweisen und in einzelnen Bereichen bereits menschliche Experten übertreffen können. Dennoch sind sie noch weit davon entfernt, das gesamte Spektrum menschlicher Expertise einschließlich Intuition, komplexer Visualisierung und kritischer Selbstreflexion zu ersetzen. Ihre Rolle als unterstützende „Co-Piloten“ für Chemiker scheint jedoch vielversprechend, insbesondere wenn sie mit spezialisierten Datenquellen kombiniert und in sichere, transparente Systeme eingebettet werden. Die Zukunft der Chemie könnte somit in der produktiven Symbiose von menschlichem Expertenwissen und maschineller Intelligenz liegen – eine spannende Herausforderung für Wissenschaft, Technologie und Gesellschaft.