React Server Components (RSC) wurden mit großem Enthusiasmus als revolutionäre Technologie in der React-Welt angekündigt. Sie versprechen eine neue Ära der Webentwicklung, in der Interaktivität und Performance auf eine Weise kombiniert werden, die bisher kaum möglich schien. Insbesondere die Möglichkeit, Komponenten auf dem Server zu rendern, ohne deren JavaScript an den Client zu senden, klang verlockend. Viele Entwickler, so auch ich, sahen darin das Potenzial, das gelernte Paradigma von Server-Side Rendering und clientseitiger Hydration grundlegend zu verändern. Doch in der praktischen Umsetzung zeigen sich die Grenzen dieses Ansatzes, die ich im Verlauf meiner Projekte hautnah erlebt habe.
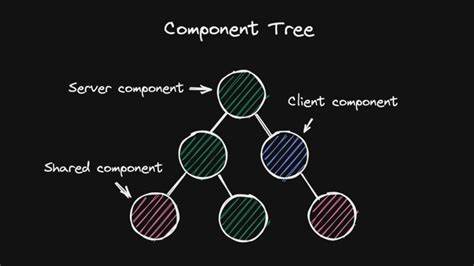
Mein Weg von der anfänglichen Begeisterung zur pragmatischen Kompromissfindung könnte anderen Entwicklern helfen, ein realistisches Bild von RSC zu gewinnen. React Server Components unterscheiden sich grundlegend von traditionellem Server-Side Rendering. Während SSR ganze Seiten auf dem Server rendert und sie dann im Browser wieder zum Leben erweckt, erlauben RSC eine feingranulare Mischung aus servergerenderten und clientseitig hydratisierten Komponenten. Dieses sogenannte Islands-Architecture-Konzept versetzt Entwickler in die Lage, genau zu steuern, welche Teile der Anwendung rein statisch auf dem Server ablaufen und welche interaktiv auf dem Client. Dieser elegante Ansatz reduziert die JavaScript-Menge, die an den Browser geschickt wird, verbessert die Startzeiten von Webseiten und schafft klare Trennung der Verantwortlichkeiten im Code.
Zudem ermöglicht RSC das asynchrone Laden von Daten direkt in den Server-Komponenten, was gegenüber älteren Methoden wie dem getServerSideProps-API von Next.js die Entwicklererfahrung deutlich verbessert. Anfangs sah meine Projekterfahrung mit React Server Components vielversprechend aus. Das Szenario, für das ich RSC auswählte, war prädestiniert: eine Website mit überwiegend statischem Inhalt, viel Markdown-Rendering und gute Voraussetzungen für serverseitiges Rendern. Ich hielt mich strikt an empfohlene Patterns, indem ich Client-Komponenten nur genau dort anlegte, wo Nutzerinteraktion nötig war, serverseitige Props an diese weitergab und React-Hooks gezielt in untergeordneten Komponenten platzierte.
Bis dahin betrachtete ich meinen Einsatz von RSC als voller Erfolg. Die Architektur war sauber und die Performance zu Beginn beeindruckend. Doch die Herausforderung kam unvermittelt mit der Implementierung einer nahtlosen unendlichen Scrollfunktion. Diese ist mittlerweile ein Standard-Feature in modernen Webanwendungen, aber sie offenbart fundamentale Schwächen des React Server Component-Ansatzes. Infinite Scrolling bedeutet, dass Daten nicht gebündelt auf einmal geladen werden, sondern stückweise beim Scrollen nachgeladen werden.
Dabei ist es wichtig, den Zustand der bereits geladenen Daten zu verwalten und nahtlos zu erweitern. Innerhalb von RSC stellte sich jedoch genau das als Problem dar. Zwei grundlegende Ansätze bestehend aus serverseitiger Datenbeschaffung und Client-seitigem Zustandsexport wurden geprüft. Die erste Methode basierte darauf, Seite für Seite über URLs zu navigieren, wobei jeder Schritt eine neue Server-Komponente mit aktualisierten Parametern lädt. Diese Lösung ist für paginationstypische Anwendungsfälle geeignet, bei denen ältere Daten verworfen werden können.
Für die unendliche Scrollfunktion aber bedeutete das, dass zum Abrufen der fünfzigsten Seite alle vorherigen 49 Seiten neu geladen werden müssten – eine massive und ineffiziente Belastung für Backend und Netzwerk. Das Konzept, für jedes Datenpaket einzeln den Server aufzurufen, erwies sich bei wachsendem Datenvolumen als praktischer Nutzenkiller, der den eigentlichen Performance-Gewinn durch RSC aufhob. Die zweite Prüfung bestand darin, Serverfunktionen mit Hilfe von Reacts aktuellem Hook useActionState im Client aufzurufen. Diese Technik erlaubt es, asynchron Daten vom Server zu holen und sie in einem zugänglichen Zustand zu speichern. Prinzipiell lassen sich so gestaffelte Datenabrufe über Scrollereignisse realisieren.
Allerdings zeigt sich das Verfahren spätestens bei komplexeren Datenflüssen als schwerfällig. Serveraktionen in RSC sind nicht für reine GET-Anfragen gedacht und laufen zudem seriell ab, was die Nutzerinteraktion blockieren kann. Zudem steigt die Implementierungskomplexität rapide, sobald gemeinsamer Zustand oder persistente Datenmodelle benötigt werden. Daten zu verwalten, die parallel oder in Echtzeit wachsen, ist mit dieser Möglichkeit kaum praktikabel, da der gesamte Datenzustand oftmals an den ersten Datenabruf gebunden bleibt. Die erlebten praktischen Einschränkungen führten zu einer zentralen Entscheidung: der Abstandnahme von RSC als primärer Datenverwaltungsschicht.
Stattdessen wandte ich mich bewährten State-Management-Lösungen wie @tanstack/react-query zu, die speziell für das Handling von asynchronen Datenabfragen und Client-Zustand ausgelegt sind. React Query bietet eine zentrale Instanz für die Verwaltung von Abfrageergebnissen und ermöglicht etwa eine optimistische UI-Aktualisierung, die auf die tatsächlichen Serverantworten reagiert. Es dient als Single Source of Truth und interagiert nahtlos mit anderen Komponenten, die vielfach auf dieselben Daten zugreifen. Anders als RSC liefert React Query ein robustes Client-State-Management und ermöglicht eine bessere Kontrolle auch in komplexen Anwendungsszenarien. Die Migration brachte jedoch deutliche Unterschiede im Entwicklungsparadigma mit sich.
Während RSC serverseitig arbeitet und auf der Basis von servergenerierten Props die Applikation aufbaut, ist React Query vollständig clientseitig. Die beiden Modelle sind bisher kaum integriert, und der Transfer von Zustandsänderungen zwischen Server- und Client-Logik stellt eine Herausforderung dar. Die Kombination erfordert daher einen hybriden Ansatz, bei dem RSC dort eingesetzt wird, wo es leistet, während Reaktivität und Datenmanagement auf dem Client betrieben werden. Diese Erkenntnisse führen zu einer klaren Position: React Server Components sind keine vollwertige Datenmanagementlösung. Sie eignen sich hervorragend für initiales Rendering, für statische Inhalte und Performance-optimierte Teile der Benutzeroberfläche ohne komplexe Interaktion.
Doch wenn es um dynamischen Zustand und fließende Datendialoge geht, stößt das Modell an seine Grenzen. Die Praxis lehrt, dass reale Anwendungen meist eine aufwendige Client-Seitige Stateverwaltung benötigen, so dass der reine RSC-Ansatz nicht ausreicht. Der Umgang mit komplexen Anforderungen bedeutet, über das RSC-Ökosystem hinauszugehen und zusätzliche Werkzeuge zu integrieren. Folglich sieht die Zukunft der Webentwicklung in einer Kombination aus React Server Components und bewährten Client-Pattern aus. RSC bringt wichtige Fortschritte, doch sie wird suboptimal, wenn man sie als Silver Bullet betrachtet.
Eine hybride Architektur, die Stärken beider Welten bündelt, dürften für die meisten Anwendungen der pragmatischste Weg sein. Diese Schlussfolgerung teilen auch andere Experten, darunter Evan You, der Entwickler von Vue.js. Er sieht in RSC spannende neue Muster, warnt aber vor den Komplexitäten und dem mentalen Overhead, der durch das Überschreiten von Verantwortlichkeitsgrenzen entsteht. Die Next.
js- und React-Teams haben versucht, die Entwicklererfahrung zu verfeinern und den theoretischen Nutzen nahezu „kostenlos“ erreichbar zu machen. Doch dieser Ansatz hat sich bisher als nicht umfassend erfolgreich erwiesen. Entwicklern wird geraten, RSC dort zu nutzen, wo sie brillieren: für Initial-Rendering, statische und performanzkritische UI-Komponenten. Die Notwendigkeit, bestehende Anwendungen oder zukünftige Features mit komplexem Zustand umzusetzen, erfordert den Einsatz unabhängiger Client-State-Management-Lösungen wie React Query. Auf diesem Weg gewährleistet man Flexibilität und Stabilität im Entwicklungsprozess.