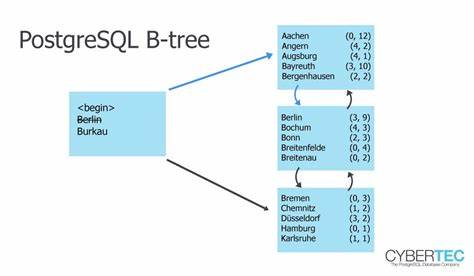
PostgreSQL gehört zu den beliebtesten Open-Source-Datenbanksystemen weltweit und wird wegen seiner Robustheit, Flexibilität und leistungsfähigen Indexierungsmechanismen geschätzt. Doch auch in solch einem ausgereiften System kann es Situationen geben, in denen ein scheinbar passender Index trotz aller Bemühungen nicht effektiv genutzt wird. Das führt zu inkonsistenten oder sogar äußerst langsamen Abfragezeiten, gerade bei sehr großen Tabellen mit mehreren hundert Millionen Zeilen. Warum ist das so und wie kann man diesem Problem sinnvoll begegnen? Im Folgenden beschäftigen wir uns mit den Ursachen, Herausforderungen und Lösungsansätzen rund um die Frage: Kann PostgreSQL diesen Index tatsächlich nutzen? Ein klassisches Problem im Produktionsalltag großer Datenbanken entsteht, wenn in WHERE-Klauseln Funktionen auf Indexspalten angewendet werden, die nicht als immutable (unveränderbar) klassifiziert sind. Ein Beispiel dafür ist die Verwendung von extract(hour FROM created_at), um gezielt Datensätze eines bestimmten Zeitraums herauszufiltern.
Obwohl ein Index auf col1, col2 und created_at existiert, nutzen viele Abfragen diesen Index nicht optimal. Das liegt daran, dass die Datenbank bei jedem Treffer überprüfen muss, ob Stunde und Minute im Zeitstempel mit den geforderten Werten übereinstimmen. Dies führt zu einem sogenannten Bitmap- oder Index-Scan, der viele Indexeinträge liest, aber letztlich aufwendige Heap-Filterungen im Speicher durchführt. Bei großen Tabellen summieren sich so die I/O-Kosten gewaltig. Die Schwierigkeit liegt darin, dass PostgreSQL die Funktionen, die auf eine Spalte angewendet werden (wie extract), für die Indexnutzung als nicht indexfähig einstuft, da diese Funktionen nicht immutable sind.
Eine Funktion gilt als immutable, wenn sie bei gleichen Eingabewerten stets das gleiche Ergebnis liefert – ohne Seiteneffekte oder vom Kontext abhängige Variablen. Im Falle von „extract“ auf einen Zeitstempel mit Zeitzonenbezug (timestamptz) kann das Ergebnis jedoch von der Datenbankkonfiguration abhängen, insbesondere von der eingestellten Zeitzone. Dies macht die Funktion offiziell als nicht immutable und verhindert die Indexbenutzung bei entsprechenden Ausdrucksindizes oder partiellen Indizes. Viele Entwickler sind versucht, das Problem durch das Anlegen partieller Indizes zu lösen, also Indexe, die nur für eine Teilmenge der Daten gelten, beispielsweise nur für Datensätze, deren Stunde 16 und Minute 15 ist. Das Problem hierbei ist, dass die WHERE-Bedingung für einen partiellen Index ebenfalls Funktionen enthalten muss, die immutable sind.
Da dies im Kontext von extract(hour FROM ...) nicht möglich ist, schlägt diese Strategie in der Praxis oft fehl oder ist nur unter sehr speziellen Voraussetzungen machbar. Ein bewährter Trick, der in der PostgreSQL-Community immer wieder diskutiert wird, ist die sogenannte „Query Rewrite“-Methode.
Dabei wird die Abfrage so umgeschrieben, dass sie einen Unterabfrage-Filter nutzt, der nur Spalten verwendet, die tatsächlich im Index enthalten sind, also ohne Funktionen auf Datumsspalten. Diese Unterabfrage selektiert präzise die Werte von col1, col2 und created_at heraus, die den Filterkriterien entsprechen, allerdings ohne die problematischen extract-Aufrufe. Die Hauptabfrage filtert dann mit einer IN-Klausel auf diese präzisen Werte. Diese Technik führt häufig dazu, dass PostgreSQL statt eines normalen Index-Scans einen Index-Only-Scan verwendet. Dabei liest die Datenbank ausschließlich aus dem Index, ohne die zugrunde liegenden Tabellenzeilen ansprechen zu müssen.
Das reduziert den I/O-Aufwand erheblich und beschleunigt Abfragen dramatisch. Die Effektivität dieser Methode lässt sich oft qualitativ und quantitativ mit EXPLAIN ANALYZE nachweisen: Die ursprüngliche Abfrage kann auf mehrere Minuten kommen, während die neu gestaltete Version in Millisekunden liefert. Ebenso kann man als Alternative die Verwendung von materialisierten Spalten oder zusätzlichen Spalten mit vorab berechneten Werten in der Tabelle erwägen, beispielsweise eigenständige Spalten für Stunde und Minute, die bei jeder INSERT- oder UPDATE-Operation automatisch gefüllt werden. Diese Spalten sind immutable und erlauben direkte Indexierung. Die Abfrage kann dann auf diese Felder zugreifen, wodurch die Indexnutzung wieder möglich wird.
Diese Technik hat aber den Nachteil erhöhter Speicher- und Wartungskosten und ist nur dann sinnvoll, wenn solche zeitbezogenen Abfragen sehr häufig sind. Ein weiterer Ansatz sind benutzerdefinierte immutable Funktionen, die intern extract aufrufen, aber von PostgreSQL als immutable eingestuft werden. Diese sogenannte „Trick-Funktion“ erlaubt die Erzeugung von Ausdrucksindizes, die dann für die Stunde oder Minute genutzt werden können. Dies funktioniert allerdings nur, wenn man absolute Sicherheit über die Umgebung hat, denn die Zeitzoneneinstellungen dürfen sich im Betrieb nicht verändern. Außerdem ist der Aufwand für Security Audits und Wartbarkeit hier höher.
Grundsätzlich ist es wichtig zu verstehen, dass der PostgreSQL-Queryplanner Entscheidungen über Indexnutzung und Join-Strategien auf Basis von statistischen Daten, Kostenmodellierung und Funktionsmodifikatoren trifft. Funktionen, die als nicht immutable gekennzeichnet sind, lassen keine Indexnutzung zu, da PostgreSQL nicht garantieren kann, dass deren Ergebnis konstant bleibt. Die Annahme, dass gute Indexe an sich automatisch und ständig zum Tragen kommen, ist damit nicht immer korrekt. Es bedarf einer genauen Planung, manuellem Tuning und oftmals auch Query-Rewrites oder Datenmodell-Anpassungen, um optimale Ergebnisse zu erreichen. Neben den funktionalen Einschränkungen kann aber auch die Breite der Tabelle eine Rolle spielen.
Wenn eine Tabelle sehr viele Spalten und entsprechend breite Zeilen hat, kann selbst ein Index-Scan ineffizient werden, da die Anzahl der Heap-Zugriffe hoch ist. Hier helfen Index-Only-Scans, bei denen nur die Indexseiten gelesen werden, da der Index alle benötigten Daten beinhaltet. Voraussetzung für Index-Only-Scans ist, dass die Tabelle regelmäßig mittels VACUUM gepflegt wird, da die Sichtbarkeit der Datensätze sonst nicht zuverlässig aus den Indexseiten abgeleitet werden kann. Diese Erkenntnisse zeigen, dass man neben der Erstellung von Indizes stets auch die Abfragen und das Datenmodell im Auge behalten sollte. Zum Beispiel kann statt einer komplexen WHERE-Bedingung mit mehreren Funktionsausdrücken eine Vortabellösung oder ein denormalisiertes Modell mit zusätzlichem Spalten verwendet werden, um die Performance sicherzustellen.
Auch das Monitoring des Queryplanners und das regelmäßige Nachziehen von Statistiken (ANALYZE) sind unbedingt zu empfehlen. Die Community hat in jüngster Zeit auch alternative Verfahren diskutiert, bei denen PostgreSQL in Kombination mit Extensions oder spezialisierten Index-Typen verwendet wird. Index-Typen wie BRIN (Block Range Index) können bei sehr großen Zeitstempel-basierten Tabellen hilfreich sein, da sie Datenbereiche zusammenfassen und selektive Abfragen performant unterstützen. Allerdings funktionieren diese Indexe nur bei passenden Workloads sehr gut. Abschließend bleibt festzuhalten, dass PostgreSQL grundsätzlich den vorhandenen Index nutzen kann, wenn die Abfragebedingungen und die Indexgestaltung miteinander harmonieren.
Die Herausforderung liegt oft darin, Funktionen richtig einzusetzen, Daten so zu modellieren, dass Mutable-Funktionen keine Blockaden erzeugen, und den Queryplanner durch geeignete Abfragemuster zu unterstützen. Wer diese Prinzipien versteht, kann in PostgreSQL enorm von seiner Indexierungsvielfalt profitieren, besonders bei komplexen Abfragen auf sehr großen Datensätzen. In manchen Fällen sind kleine Query-Rewrites oder die Ergänzung von Spalten zum Vorberechnen von Indextauglichen Ausdrücken das Mittel der Wahl, um aus einem bereits vorhandenen Index das Optimum herauszuholen. Die Diskussion um die Nutzung von extract in Kombination mit großen Tabellen und Indexen bleibt weiterhin aktuell. Neue PostgreSQL-Versionen könnten mit verbesserten Möglichkeiten implementiert werden, aber bis dahin sind pragmatische Ansätze wie Query-Rewrites oder das Vermeiden nicht immutable Funktionen in WHERE-Klauseln der pragmatische Weg zu zuverlässiger performant arbeitenden Datenbanken.
Wer das beherzigt, kann auch bei Stresstest-Szenarien und Millionen von Zeilen Abfragen performant ausführen und den Nutzen von Indizes voll ausschöpfen.