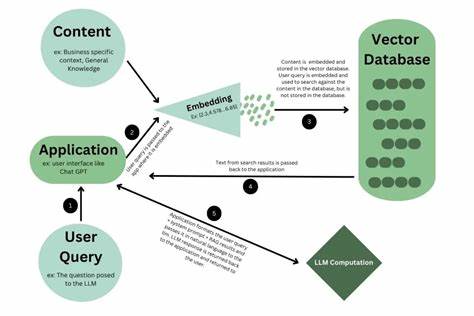
Moderne Sprachmodelle, oder Large Language Models (LLMs), haben die Art und Weise revolutioniert, wie Maschinen menschliche Sprache verstehen und verarbeiten. Eine der wichtigsten Technologien, die hinter dieser Entwicklung steht, sind sogenannte Embeddings. Diese spielen eine zentrale Rolle, damit Sprachmodelle komplexe Zusammenhänge in Texten erkennen und interpretieren können. Doch was genau sind Embeddings, wie funktionieren sie und warum sind sie so bedeutend für die Fortschritte in der Künstlichen Intelligenz? Dieser Leitfaden liefert eine visuelle und intuitive Erklärung, die selbst komplexe technische Sachverhalte verständlich macht. Embeddings sind nichts anderes als numerische Darstellungen von Wörtern, Sätzen oder ganzen Textabschnitten in Form von Vektoren innerhalb eines hochdimensionalen Raumes.
Die Idee dahinter ist, dass die Bedeutung von Sprache durch mathematische Strukturen kodiert wird, die von Computern leichter verarbeitet werden können. Anstatt Wörter als reine Buchstabenfolgen oder Symbole zu betrachten, transformiert das Modell sie in Punkte in einem geometrischen Raum. Dabei gilt: Ähnliche Begriffe oder Konzepte liegen näher beieinander als weniger verwandte. Dies erlaubt Sprachmodellen semantische Zusammenhänge zu erkennen, die über reine Oberflächenähnlichkeiten hinausgehen. Stellen Sie sich vor, sie zeichnen alle Wörter eines Textes als Punkte auf einer großen Landkarte.
Wörter wie "Auto", "Fahrzeug" und "Motor" würden nahe beieinander gruppiert sein, da sie ähnliche Bedeutungen tragen. Begriffe wie "Apfel" oder "Restaurant" würden hingegen weiter entfernt liegen. Diese Landkarte ist in Wahrheit ein mehrdimensionaler Raum, der so komplex ist, dass Menschen ihn nicht direkt visualisieren können. Embeddings sind der Schlüssel, um diese abstrakten Bedeutungen greifbar und für Maschinen interpretierbar zu machen. Die Erstellung von Embeddings erfolgt anhand von Trainingsdaten, die jeweils zahlreiche Textbeispiele enthalten.
Deep-Learning-Modelle lernen dabei, wie Wörter im Kontext auftreten und welche Beziehungen zwischen ihnen bestehen. Sie passen ihre internen Parameter an, bis ähnliche Konzepte in der Vektorlandschaft tatsächlich nahe zueinander angeordnet sind. Gleichzeitig wird sichergestellt, dass unähnliche Wörter entsprechend weit voneinander entfernt bleiben. Das ermöglicht, dass ein Modell auch bei noch nie gesehenen Kombinationen eine semantische Einordnung vornehmen kann. LLM-Embeddings sind heute in vielen Bereichen unverzichtbar.
Im Suchmaschinenranking helfen sie dabei, relevante Ergebnisse nicht nur durch exakte Übereinstimmung von Suchbegriffen, sondern auch durch inhaltliche Nähe zu ermitteln. Auch in Chatbots und virtuellen Assistenten sorgen sie für ein tieferes Verständnis der Benutzeranfragen. Darüber hinaus finden Embeddings Anwendung in der Textklassifikation, Sentiment-Analyse, maschinellen Übersetzung und vielen weiteren NLP-Aufgaben. Eine der großen Stärken von Embeddings ist ihre Übertragbarkeit. Ein einmal trainiertes Embedding-Modell kann für unterschiedlichste Aufgaben eingesetzt werden, ohne komplett neu trainiert werden zu müssen.
Es kann als universelle Repräsentation für Sprache dienen und erleichtert so den Transfer von Wissen zwischen Anwendungen. Gleichzeitig erlaubt diese Flexibilität, selbst in komplexen Domänen wie Medizin oder Recht schnell passende Lösungen zu finden. Um Embeddings zu visualisieren, nutzen Forscher Techniken wie t-SNE oder UMAP, die den hochdimensionalen Vektorraum auf wenige Dimensionen reduzieren, damit Menschen Muster erkennen können. Durch diese Abbildungen wird greifbar, wie Modelle sprachliche Bedeutung strukturieren und wie Sprachmodelle Verbindungen zwischen Begriffen herstellen. Trotz ihrer vielen Vorteile haben Embeddings auch ihre Herausforderungen.
Eine wichtige Frage ist, wie gut sie kulturelle Nuancen oder Ironie abbilden können, da viel Bedeutung auch vom Kontext und vom Hintergrund der Sprache abhängt. Auch die Qualität der Trainingsdaten spielt eine zentrale Rolle, da Vorurteile oder Verzerrungen auf Embeddings übergehen können. Daher arbeiten Experten stetig daran, diese Aspekte zu verbessern und transparente Modelle zu schaffen. Im Gesamtkontext moderner KI ist das Verständnis von Embeddings daher grundlegend. Sie ermöglichen es Maschinen, Sprache nicht nur als Aneinanderreihung von Wörtern zu sehen, sondern als vielschichtige, bedeutungstragende Struktur.
So wird der Weg geebnet, dass Maschinen immer besser in der Lage sind, menschliche Kommunikation nachzuvollziehen und darauf zu reagieren. Die Zukunft verspricht weitere spannende Entwicklungen. Durch kombinierte Ansätze etwa mit multimodalen Modellen, die sowohl Text als auch Bilder verarbeiten, werden Embeddings ihre Rolle als Schnittstelle zur Bedeutungsauswertung noch weiter ausbauen. Außerdem wird die Integration von Domänenwissen Embeddings noch spezifischer und leistungsfähiger machen. Für Entwickler, Unternehmen und Forschende bedeutet das, dass ein fundiertes Verständnis dieser Technologie einen entscheidenden Vorteil im Umgang mit KI-gestützten Sprachsystemen darstellt.
Wer Embeddings beherrscht, kann flexibel auf neue Anforderungen reagieren und innovative Anwendungen schaffen, die Nutzererfahrungen nachhaltig verbessern. Zusammengefasst sind LLM-Embeddings einerseits faszinierende mathematische Repräsentationen, andererseits das Herzstück intelligenter Sprachverarbeitung. Sie verbinden moderne Algorithmen mit menschlicher Sprache auf eine Weise, die die digitale Kommunikation grundlegend verändert hat und weiter revolutionieren wird. Wer die Prinzipien hinter Embeddings versteht, öffnet die Tür zu einer neuen Welt der Möglichkeiten in der Künstlichen Intelligenz und der automatisierten Sprachverarbeitung.








