Im modernen Softwareentwicklungsprozess sind automatisierte Tests unverzichtbar, um die Qualität und Stabilität von Anwendungen sicherzustellen. Besonders bei funktionalen Programmiersprachen wie Elm werden Property-Based Tests (PBT) immer beliebter, da sie es ermöglichen, generisch verschiedene Eingaben zu testen und so Fehlerquellen effizient aufzuspüren. Doch dabei ergeben sich Herausforderungen, wenn die automatisch generierten Testfälle nicht wirklich die interessanten oder kritischen Bereiche der Anwendung abdecken. Genau hier kommen Testverteilungen (Test Distributions) ins Spiel, ein Konzept, das Entwicklern im Elm-Ökosystem hilft, die Qualität und Aussagekraft ihrer Tests entscheidend zu verbessern. Property-Based Testing basiert auf der Idee, dass nicht einzelne fest definierte Testfälle ausgeführt werden, sondern stattdessen sogenannte Fuzzer dynamisch Testdaten generieren.
Das ist zwar mächtig, doch es besteht die Gefahr, dass die erzeugten Daten immer ähnliche Muster zeigen, zum Beispiel nur Werte in einem kleinen Mittelbereich, während Randfälle oder spezielle Varianten kaum oder gar nicht auftreten. So kann ein scheinbar umfangreicher Test vor allem triviale Fälle überprüfen, ohne dass kritische Edge Cases abgedeckt werden. Ein praktisches Beispiel verdeutlicht das Problem. Stellen Sie sich vor, Sie testen eine Queue-Implementierung in Elm. Operations wie Push und Pop werden mit gleicher Wahrscheinlichkeit ausgewählt, wodurch die Queue meistens sehr kurz bleibt.
Längere Queues, die in der Praxis jedoch häufiger Fehler verursachen können, werden kaum erzeugt und bleiben somit ungetestet. So entsteht der Eindruck, das System sei robust, obwohl potenzielle Probleme unerkannt bleiben. Um dieser Problematik auf den Grund zu gehen, hat Elm vor einiger Zeit das Modul Test.Distribution in seine Testbibliothek integriert. Es bietet die Möglichkeit, Generationen von Testdaten nicht nur zu produzieren, sondern auch zu klassifizieren, zu messen und sogar Vorgaben hinsichtlich ihrer Häufigkeit zu machen.
So erkennt man ganz gezielt, welche Kategorien von Testfällen oft genug geprüft werden und ob wichtige Szenarien zu selten oder gar nicht berücksichtigt sind. Mit einfachen Funktionen wie Fuzz.examples kann man sich zunächst Beispiele aus der Verteilung anzeigen lassen, was jedoch oft nicht ausreichend ist, da Zufallsgenerierungen nur teilweise die wahren Wahrscheinlichkeiten widerspiegeln. Etwaige Lücken kann man so nur schwer erkennen. Besser eignet sich Fuzz.
labelExamples, bei dem einzelne Kategorien mit Labels versehen werden, um exakt zu beobachten, ob und wie häufig sie auftreten. Beispielsweise kann man eine Kategorie "Randfälle" für besonders kleine oder große Werte definieren oder "besondere Merkmale" für Eingaben, die bestimmte Bedingungen erfüllen. Das Herzstück von Test.Distribution sind aber die Funktionen reportDistribution und expectDistribution. reportDistribution erlaubt es, während eines Testlaufs eine detaillierte Aufschlüsselung über die Verteilung von definierbaren Kategorien anzuzeigen.
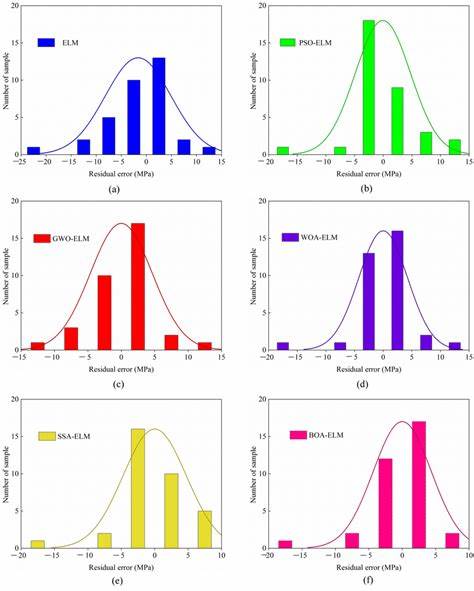
Diese werden pro Kategorie als Prozentanteil, absolute Häufigkeit und grafische Histogramme illustriert. So sieht man auf einen Blick, ob die gesamte Bandbreite der möglichen Testfälle ausreichend abgebildet wird oder ob vielleicht eine Klasse von Szenarien unzureichend vertreten ist. Noch wichtiger ist expectDistribution, wenn man eine formelle Garantie für die Abdeckung in Form von Mindesthäufigkeiten fordert. Mit dieser Funktion lässt sich festlegen, dass eine bestimmte Kategorie mindestens einen bestimmten Prozentsatz der Testdurchläufe erreichen muss, andernfalls schlägt der Test als nicht bestanden fehl. Das zwingt dazu, den eigenen Fuzzer so anzupassen, dass keine wichtigen Szenarien außen vor bleiben.
Ein Beispiel wären Randwerte, die in einem Bereich von 1 bis 20 mindestens vier Prozent aller Testwerte ausmachen müssen, um die Robustheit der Funktionen an diesen Grenzen sicherzustellen. Ein Nachteil bei der strengen Verteilungserwartung liegt in der potenziellen Verlängerung der Testlaufzeiten. Da Test.expectDistribution mit großer statistischer Sicherheit überprüft, ob die gewünschten Wahrscheinlichkeiten eingehalten werden, können deutlich mehr Werte generiert werden als bei einfachen 100 Testläufen üblich. Dies ist jedoch ein sinnvoller Kompromiss, wenn dadurch verdeckte Fehler vorhersehbar ausgeschaltet werden.
Praktisch lässt sich die Verteilung bei komplexeren Datentypen wie Queues sehr gut visualisieren und absichern. Dort kann man Kategorien etwa nach der Länge der Queue bilden: Leer, einzelne Elemente, mittlere Größen oder besonders große Queues. Dadurch wird garantiert, dass selbst seltene, aber komplexe Zustände geprüft werden. Solche differenzierten Klassifizierungen bringen echten Mehrwert und steigern die Aussagekraft der Tests beträchtlich. Die übergreifende Philosophie hinter dieser Vorgehensweise ist, Entwicklern intuitive Instrumente zu geben, um in ihrem Testportfolio die sogenannte "Testabdeckung" nicht nur quantitativ, sondern qualitativ zu betrachten.
John Hughes, einer der bedeutendsten Köpfe im Bereich Property-Based Testing, beschreibt in seinem vielbeachteten Vortrag, wie Entwickler durch Labels und Distributionen eine bewusste und wirkungsvolle Teststrategie etablieren können. Grundsätzlich ist die Arbeit mit Testverteilungen nicht nur für Elm relevant, sondern lässt sich in vielen Programmiersprachen übertragen, die auf Property-Based Testing setzen. Dennoch hat Elm mit seinem übersichtlichen und schlanken Setup eine besonders einfache und klar dokumentierte Lösung entwickelt, die dabei hilft, nicht nur funktionale, sondern auch statistisch fundierte Schlüsse aus Tests zu ziehen. Abschließend lässt sich festhalten, dass der gezielte Einsatz von Test.Distribution in Elm entscheidend dazu beiträgt, sinnvolle und abwechslungsreiche Testfälle zu generieren.
So vermeiden Entwickler, dass wichtige Randbereiche oder spezielle Anwendungsfälle übersehen werden. Durch diese Methode erhöht sich die Zuverlässigkeit der Software signifikant, indem Fehler früher entdeckt und verstanden werden. Zudem entsteht durch aussagekräftige Verteilungsberichte eine transparente Grundlage, um Teststrategien kontinuierlich zu verbessern und an reale Anforderungen anzupassen. Für Entwickler, die in Elm mit Property-Based Testing arbeiten, sind die Funktionen rund um Test.Distribution ein unverzichtbares Werkzeug, um Tests nicht nur auszuführen, sondern auch deren Qualität messbar zu machen.



![How to give a 20 minute talk [pdf]](/images/813455EF-4D67-432E-A237-84CFA5A45B09)



