Große Sprachmodelle (Large Language Models, LLMs) prägen heute zahlreiche innovative Anwendungen von Chatbots über Textgenerierung bis hin zu automatischem Übersetzen. Doch trotz ihrer beeindruckenden Fähigkeiten stellen die meist relativ langen Inferenzzeiten eine zentrale Herausforderung dar - insbesondere bei Anwendungen mit engen Feedbackschleifen, wo Wartezeiten von mehreren Sekunden die Nutzererfahrung erheblich verschlechtern. Die Frage, wie man die Inferenzgeschwindigkeit von LLMs effektiv steigern kann, gewinnt daher immer mehr an Relevanz. Insbesondere wenn es darum geht, kurze Antworttexte schnell und zuverlässig zu generieren, sind herkömmliche Latenzzeiten von mehreren Sekunden oft untragbar. Im Folgenden beleuchten wir verschiedene Ansätze, um die Geschwindigkeit von LLM-Inferenzprozessen signifikant zu verbessern, ohne dabei Qualitätseinbußen hinnehmen zu müssen.
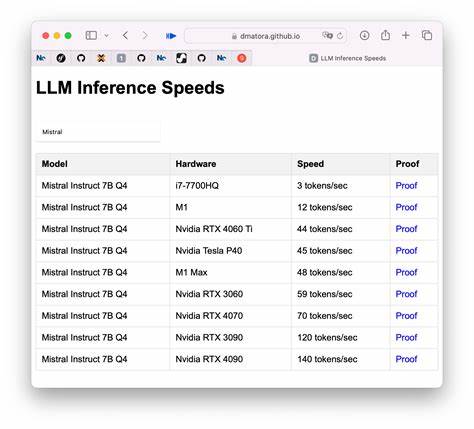
Dabei beziehen wir sowohl hardwareseitige als auch softwareseitige Optimierungen ebenso wie Modellstrategien und Infrastrukturüberlegungen ein. Die Grundlage für schnellere Inferenzzeiten bildet in den meisten Fällen die eingesetzte Hardware. Große Sprachmodelle sind äußerst rechenintensiv und profitieren speziell von GPUs, die für parallele Fließkomma-Berechnungen optimiert sind. Hochleistungs-GPUs moderner Generation weisen nicht nur eine deutlich höhere Anzahl an Rechenkernen auf, sondern verfügen zudem über speziell für KI-Anwendungen zugeschnittene Tensor-Cores. In der Praxis bedeutet dies, dass der Einsatz schneller und moderner GPU-Modelle wie beispielsweise der NVIDIA-Ampere- oder Hopper-Architekturen die Verarbeitung statischer Textanfragen auf wenigen hundert Token deutlich beschleunigen kann.
Allerdings ist der reine Hardware-Tausch nur ein Teil der Lösung: Nur wenn das Modell lokal gehostet wird und nicht über API-Aufrufe an externe Cloud-Dienste kommuniziert, können die Vorteile einer schnelleren GPU unmittelbar genutzt werden. Der selbst gehostete Betrieb großer Sprachmodelle erfordert zwar höhere Anfangsinvestitionen, dafür entfallen aber oft lästige Latenzen beim Netzwerktransfer und der Serialisierung von Eingaben und Antworten. Neben der Hardware spielt die zugrunde liegende Software eine maßgebliche Rolle bei der Performancesteigerung. Modelle, die auf Frameworks wie Hugging Face Transformers oder Ollama basieren, erlauben es, Inferenzpipelines zu optimieren. Beispielsweise kann die Verwendung von optimierten Berechnungsbibliotheken wie CUDA oder TensorRT die Rechenzeit drastisch reduzieren.
Diese Bibliotheken bieten Tensoroperationen, die speziell auf die GPU-Hardware abgestimmt sind, wodurch Operationen wie Matrixmultiplikationen effizienter ablaufen. Auch das Quantisieren von Modellen, also die Umwandlung von Gewichten von 32-Bit-Float in kleinere Datentypen wie 8-Bit-Integer, ist ein gängiger Ansatz, um den Speicherbedarf zu verringern und gleichzeitig die Geschwindigkeit zu erhöhen. Durch die geringere Präzision reduzieren sich neben Speicherbedarf auch die benötigten Rechenressourcen, was gerade bei repetitiven, kurzen Anfragen stark ins Gewicht fällt. Eine weitere Softwareoptimierung besteht darin, Modellarchitekturen anzupassen oder spezialisierte Varianten zu verwenden. Große Modelle wie GPT-3 oder GPT-4 sind besonders mächtig, aber auch sehr komplex.
Für viele praktische Anwendungsfälle, bei denen es nur um einfache Aufgaben wie das Umschreiben von kurzen Texten geht, reicht ein kleineres Modell mit angepasster Architektur oft völlig aus. Insbesondere sogenannte Distil-Modelle oder feinjustierte Modelle, die auf bestimmte Aufgaben zugeschnitten wurden, sind in der Lage, mit deutlich geringerem Ressourcenaufwand ähnlich gute Ergebnisse zu liefern. Dadurch verringert sich die Berechnungslast erheblich und die Antwortzeit wird reduziert. Diese Modelle können permanent lokal gehalten und schnell abgefragt werden, was gerade für Echtzeitanwendungen entscheidend ist. Die Art und Weise, wie die Eingabedaten vorverarbeitet und an das Modell übergeben werden, beeinflusst ebenfalls die Gesamtinferenzzeit.
Eine effiziente Tokenisierung und das Vermeiden unnötiger Datenkonvertierungen können wertvolle Millisekunden einsparen. Zudem kann eine gezielte Reduktion der Eingabemenge helfen – etwa durch Vorverarbeitungsschritte, die redundante Informationen filtern oder die Anfrage auf das Wesentliche beschränken. Da die Rechenzeit bei Transformer-Architekturen mit der Länge der Eingabe exponentiell wächst, ist eine schlanke Eingabe ein entscheidender Faktor für schnelle Inferenz. Auch die Infrastruktur und Anwendungsplattform sollten auf Latenzoptimierung ausgelegt sein. Die Wahl eines Hosting-Standorts in geografischer Nähe zum Nutzer verringert Netzwerkverzögerungen.
Ebenso kann die Implementierung von Asynchronität und Cachingstrategien die empfundenen Wartezeiten reduzieren. Beispielsweise kann häufig wiederkehrender Text zwischengespeichert und sofort zurückgeliefert werden, was die Nutzererfahrung verbessert. Für komplexere Anfragen, die dennoch schnell beantwortet werden müssen, ist eine intelligente Lastverteilung auf mehrere dedizierte GPU-Server ebenfalls hilfreich. So wird vermieden, dass einzelne Maschinen zum Flaschenhals werden und die Antwortzeiten sich verschlechtern. Nicht zuletzt spielen auch neue technologische Entwicklungen wie sparsames Attention-Mechanisms, Linformer-Ansätze oder andere algorithmische Verbesserungen eine Rolle, die das grundsätzliche Rechenproblem von Sprachmodellen effizienter gestalten.
Während sich diese Innovationen noch in der Verbreitung befinden, lohnt es sich für Entwickler jedoch, experimentell verschiedene Varianten auszutesten, um jene Modelle zu finden, die in puncto Geschwindigkeit und Ergebnisqualität optimiert sind. Zusammenfassend lässt sich sagen, dass die Beschleunigung der Inferenzzeit großer Sprachmodelle ein ganzheitlicher Prozess ist. Sowohl leistungsfähige Hardware wie moderne GPUs als auch optimierte Softwareframeworks, angepasste Modellarchitekturen und schlanke Eingabeverarbeitung sind entscheidend. Ein weiterer Erfolgsfaktor liegt im lokalen Hosting und der Infrastrukturgestaltung. Durch die Kombination all dieser Hebel können Entwickler reale Inferenzzeiten von zehn Sekunden auf unter zwei Sekunden reduzieren – ein enormer Gewinn für die Nutzererfahrung.
Insbesondere bei Anwendungen mit kurzen Textantworten, wie dem Umschreiben von Sätzen, lohnt sich der Aufwand dieser Performanceoptimierung dringend. Dadurch können innovative Projekte schneller reagieren, flüssiger funktionieren und letztlich eine deutlich bessere Akzeptanz bei Endnutzern erzielen. Die Optimierung der LLM-Inferenzgeschwindigkeit bleibt ein spannendes Feld, das mit fortschreitender Technik stetig an Bedeutung gewinnt.






![Zephyr Abstract Syntax Definition Language [pdf]](/images/732CA191-C263-4B90-89D3-21DCF489E28D)

