Die rasante Entwicklung von Künstlicher Intelligenz und Maschinellem Lernen hat neuronale Netzwerke zu einem unverzichtbaren Werkzeug in zahlreichen Anwendungen gemacht. Ob in der medizinischen Bilderkennung, autonomen Fahrzeugen oder Spracherkennung – die Präzision der Inferenz, also der Berechnung der Ausgaben eines trainierten Modells, ist essenziell für die Anwendbarkeit und Zuverlässigkeit der Systeme. Eine fundamentale Voraussetzung dabei ist, dass bei gleichbleibendem Modell und identischen Eingabedaten stets konsistente und reproduzierbare Ergebnisse erzielt werden. Doch jüngste Forschungen aus dem Jahr 2023 offenbaren, dass dies nicht selbstverständlich ist. Unerwartete numerische Abweichungen treten auf, die nicht nur zwischen verschiedenen Hardwareplattformen, sondern teilweise sogar innerhalb derselben Plattform und bei wiederholter Ausführung auftreten können.
Diese Phänomene werfen grundlegende Fragen zur Stabilität und Sicherheit von neuronalen Netzen auf und werfen ein neues Licht auf Inferenzframeworks und deren Hardwareabhängigkeiten. Im Kern dieser Problematik steht die Tatsache, dass maschinelles Lernen und speziell neuronale Netzwerke zunehmend komplexe Berechnungen in umfangreichen, tiefen Architekturen durchführen. Dabei werden Hardware-spezifische Optimierungen genutzt, um die Geschwindigkeit und Effizienz der Berechnungen zu maximieren. So setzen moderne ML-Frameworks oftmals SIMD-Instruktionen auf CPUs ein und wählen auf GPUs zur Laufzeit dynamisch unterschiedliche Convolution-Algorithmen aus. Diese Optimierungen sind attraktiv, weil sie die Ausführungszeiten deutlich reduzieren können.
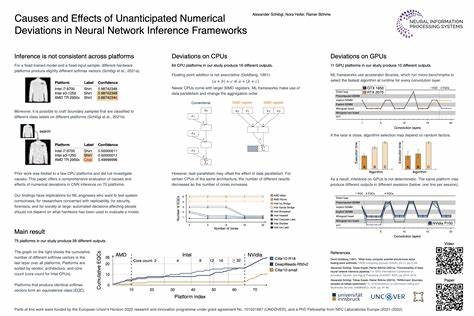
Allerdings führen sie unter Umständen zu kleinen numerischen Abweichungen, die sich in den Inferenz-Ergebnissen manifestieren. In der Studie, die im Rahmen der NeurIPS 2023 vorgestellt wurde, wurde untersucht, wie sich diese Faktoren auf die Konsistenz neuronaler Netze auswirken. Insgesamt wurden 75 verschiedene Hardwareplattformen analysiert. Dabei zeigte sich, dass hauptsächlich die Unterschiede in der Anwendung von SIMD-Instruktionen auf CPUs und die algorithmische Auswahl auf GPUs die Ursache der numerischen Ungenauigkeiten sind. Diese Abweichungen können auf den ersten Blick als marginal erscheinen, doch neuronale Netze reagieren oft empfindlich auf small-scale Veränderungen.
Bereits minimale Unterschiede in den Zwischenergebnissen können sich entlang der Schichten in tiefen Netzwerken verstärken und langfristig zu spürbaren Variationen in der finalen Ausgabe führen. Die Konsequenzen sind vielfältig und reichen von vermindertem Vertrauen in die Modellstabilität bis hin zu realen Sicherheitsbedrohungen. In sicherheitskritischen Anwendungen wie der medizinischen Diagnostik oder autonomen Fahrassistenzsystemen können solche Abweichungen Fehlentscheidungen verursachen, die potenziell schwerwiegende Folgen haben. Ein weiterer Aspekt ist die erschwerte Reproduzierbarkeit wissenschaftlicher Arbeiten im Bereich des maschinellen Lernens. Reproduzierbarkeit ist eine Grundvoraussetzung für validen wissenschaftlichen Fortschritt.
Wenn Inferenzresultate selbst bei identischen Parametern und Plattformen nicht deterministisch sind, wird es schwierig, Forschungsergebnisse exakt zu vergleichen oder auf ihnen aufzubauen. Dies kann auch die Ursachenanalyse und Fehlerbehebung in produktiven Systemen verkomplizieren, da Abweichungen nicht ohne Weiteres reproduziert werden können, um der Quelle auf den Grund zu gehen. Die Forscher verknüpfen darüber hinaus die Ursachen der numerischen Abweichungen mit bestimmten Eigenschaften der Modelle selbst. Besonders die Struktur der Convolutional Neural Networks (CNNs), die häufig in Bildverarbeitung und anderen Domänen verwendet werden, spielt eine Rolle. CNNs sind besonders anfällig, weil ihre Berechnung durch das Zusammenspiel vieler kleiner Filter und komplexer Matrixoperationen erfolgt, die durch unterschiedliche Hardwareoptimierungen unterschiedlich implementiert werden können.
Kleinste Abweichungen in der Berechnung dieser Filteroperationen können sich im Ergebnis auswirken und somit die Stabilität der gesamten Inferenz beeinflussen. Angesichts dieser Herausforderungen stellt sich die Frage nach möglichen Gegenmaßnahmen oder Strategien zur Minderung der numerischen Abweichungen. Die Forscher diskutieren verschiedene Ansätze, zum Beispiel die Vereinheitlichung der verwendeten Algorithmen über verschiedene Plattformen hinweg oder den bewussten Verzicht auf aggressive Optimierungen in sicherheitskritischen Anwendungen zugunsten stabilerer, wenn auch möglicherweise langsameren, Berechnungen. Eine weitere potenzielle Maßnahme ist die Entwicklung neuer Frameworks, die numerische Stabilität explizit priorisieren und überprüfbare Determinismus-Mechanismen integrieren. Ein wichtiger Schritt ist auch die Transparenz und Offenlegung der durchgeführten Optimierungen in den ML-Frameworks.
Oft sind Details über Algorithmusauswahl und Hardwareeinsätze nicht offen zugänglich oder schwer nachvollziehbar, was die Ursachenforschung erschwert. Die Veröffentlichung des Forschungscodes durch das Team der Studie ist hier ein positives Signal, das andere Entwickler ermutigt, eigene Plattformen systematisch zu prüfen und aufzubereiten. Auf diese Weise kann eine umfassendere Wissensbasis entstehen, die hilfreiche Benchmarks und Richtlinien für den Umgang mit numerischen Abweichungen erstellt. Wer die Implikationen gesamt betrachtet, erkennt, dass die Herausforderung nicht allein technischer Natur ist, sondern auch ethische und regulatorische Fragen tangiert. Gerade in Bereichen, in denen KI-Entscheidungen Menschen direkt betreffen, muss Klarheit über die Zuverlässigkeit und Vorhersagbarkeit der Systeme herrschen.
Unerwartete numerische Abweichungen können das Vertrauen von Anwendern, Ärzten, Fahrern oder anderen Nutzern nachhaltig unterminieren. Zudem machen sie die Implementierung von fehlerresistenten Prüfungsschritten und Validierungsprozessen notwendig, um Fehler frühzeitig zu erkennen und zu vermeiden. Die Forschung rund um neuronale Netzwerke und deren Inferenz stellt sich somit in den kommenden Jahren einer doppelten Aufgabe: Einerseits müssen Modelle und Algorithmen immer komplexer und leistungsfähiger werden, um anspruchsvollere Aufgaben zu bewältigen. Andererseits ist die Sicherstellung von Stabilität, Reproduzierbarkeit und Sicherheit essentiell, um die Akzeptanz und den verantwortungsbewussten Einsatz von KI-Systemen zu gewährleisten. Die Erkenntnisse aus der Untersuchung der unvorhergesehenen numerischen Abweichungen sind ein wichtiger Beitrag auf diesem Weg und zeigen den Handlungsbedarf für Entwickler, Forscher und Anwender gleichermaßen auf.
Abschließend lässt sich zusammenfassen, dass unvorhergesehene numerische Abweichungen in neuronalen Netzwerken eine unterschätzte, aber zugleich hochrelevante Herausforderung darstellen, die weitreichende Auswirkungen auf die Praxis und Forschung maschinellen Lernens hat. Die Rolle von Hardware-spezifischen Optimierungen, die in modernen ML-Frameworks eine zentrale Stellung einnehmen, wurde im Kontext der Inferenzdeterminismus erstmals umfassend beleuchtet. Dies eröffnet neue Wege für gezielte Optimierungsstrategien, technische Innovationen und eine kritischere Betrachtung der zugrunde liegenden Infrastruktur. Für zukünftige Entwicklungen ist es unerlässlich, dass sowohl Entwicklerteams als auch verantwortliche Institutionen diese Dimension der KI-Performance mitbedenken und entsprechend adressieren, um vertrauenswürdige und stabile Anwendungen zu realisieren.