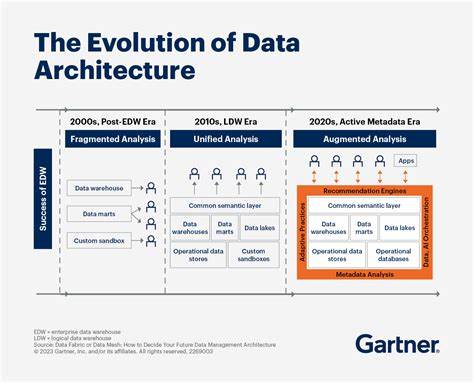
Die Art und Weise, wie Datenbanken strukturiert und betrieben werden, hat sich in den vergangenen Jahrzehnten grundlegend gewandelt. Diese Entwicklung ist eng verbunden mit dem rasanten Wachstum der Datenmengen, neuen Anforderungen im Bereich der Datenverarbeitung sowie technischen Innovationen, die traditionelle Konzepte zunehmend in Frage stellen. Die heutige Datenlandschaft ist geprägt von einem Zusammenspiel unterschiedlichster Technologien, die darauf abzielen, Daten effizienter, flexibler und zugleich leistungsfähiger zu verwalten. Schon in den 1980er und frühen 1990er Jahren dominierten relationale Datenbanksysteme (RDBMS) wie Oracle und IBM DB2 sowohl das operative Geschäft als auch die analytische Auswertung. Diese Systeme bearbeiteten Online-Transaktionsverarbeitung (OLTP) während der Geschäftszeiten und wechselten außerhalb dieser Zeiten zu Online-Analytischer Verarbeitung (OLAP) für die Berichterstellung.
Das einfache Prinzip dahinter beruhte auf verschiedenen Speicherformaten: OLTP-Systeme setzten auf zeilenorientierte Speicherung, um schnelle Schreib- und Lesezugriffe einzelner Datensätze zu ermöglichen, während OLAP-Systeme durch spaltenorientierten Speicher optimiert waren, um große Datenmengen effizient zu aggregieren und zu analysieren. Mit dem exponentiellen Anstieg der Datenmengen und der damit verbundenen Komplexität stießen traditionelle relationale Datenbanken jedoch bald an ihre Grenzen. Die Bedürfnisse von Unternehmen, insbesondere solcher mit internetbasierten Geschäftsmodellen, verlangten nach skalierbaren, flexiblen und hochverfügbaren Lösungen. Dies führte zur Geburtsstunde der NoSQL-Bewegung, die sich von der starren und strengen ACID-Konformität der relationalen Systeme lossagte und stattdessen auf verteilte Architekturen, eventual consistency und schemalose Datenmodelle setzte. Technologien wie MongoDB, Cassandra oder DynamoDB prägten diese Ära, in der Kosteneffizienz und horizontale Skalierbarkeit im Vordergrund standen.
Die Konsequenz war eine fundamentale Veränderung des Datenverständnisses. NoSQL ermöglichte die Speicherung von unstrukturierten, semi-strukturierten oder heterogenen Daten und eröffnete damit neue Anwendungen im Bereich Big Data und Echtzeitanalysen. Tools wie Apache Hadoop, MapReduce und später Apache Spark revolutionierten die analytische Datenverarbeitung, indem sie verteilte Berechnungen auf kostengünstiger Commodity-Hardware ermöglichen und so teure proprietäre Data-Warehouses herausfordern konnten. Parallel zu diesen Entwicklungen gewann der Begriff HTAP – Hybrid Transactional/Analytical Processing – an Bedeutung. HTAP-Systeme versprachen die Kombination von OLTP und OLAP in einem einzigen Datenbanksystem und damit die Eliminierung von ETL-Prozessen sowie die Möglichkeit, Echtzeit-Analysen direkt auf operativen Daten durchzuführen.
Unternehmen wie SingleStore oder TiDB versuchten, diese Vision durch Architekturen mit gemischtem Speicheransatz – In-Memory-Row-Stores kombiniert mit diskbasierten Spalten-Engines – umzusetzen. Trotz technischer Innovationen blieben diese All-in-One-Lösungen in der breiten Praxis oft hinter den Erwartungen zurück. Gründe waren unter anderem die Komplexität im Betrieb, Skalierbarkeitsprobleme, hohe Cloud-Kosten und organisatorische Trennung der Verantwortlichkeiten in Unternehmen. Vor diesem Hintergrund gewann die Write-Ahead Log-Technologie (WAL) an Bedeutung. Ursprünglich zur Wiederherstellung von Datenbanken gedacht, ermöglicht die WAL eine zeitlich geordnete Aufzeichnung aller Änderungen an der Datenbank.
Dieser Ablauf ist besonders geeignet für Change Data Capture (CDC) und bildet damit eine Brücke zwischen operativen Systemen und analytischen Plattformen. Mit Tools wie Debezium lassen sich Datenbankänderungen nahezu in Echtzeit an Streaming-Plattformen wie Apache Kafka oder Azure Event Hubs übermitteln. Dadurch wird eine hohe Datenfrische bei analytischen Anwendungen erreicht, ohne die Performance der operativen Systeme zu beeinträchtigen. Die Einführung von Data Lakehouses stellt einen weiteren bedeutenden Meilenstein in der Entwicklung dar. Diese Architektur verbindet die Skalierbarkeit und Kosteneffizienz von Data Lakes mit den verwaltungs- und sicherheitsrelevanten Funktionen traditioneller Data Warehouses.
Dabei spielen offene Tabellensysteme wie Apache Iceberg, Delta Lake von Databricks und Apache Hudi eine zentrale Rolle. Sie bieten wichtige Features wie ACID-Transaktionen, Schema- und Partitionsevolution sowie zeitliche Abfragen (Time Travel). Insbesondere Apache Iceberg hat sich als Industriestandard etabliert und wird von großen Cloud-Anbietern unterstützt. Ein wesentlicher Bestandteil moderner analytischer Ökosysteme ist Apache Arrow. Dieses spaltenorientierte In-Memory-Datenformat erlaubt eine hohe Verarbeitungsgeschwindigkeit und erleichtert die Zusammenarbeit verschiedener Systeme und Engines.
Technologien wie Spark, DuckDB und Google BigQuery nutzen Arrow, um die Performance bei analytischen Abfragen deutlich zu steigern. Moderne Datenlandschaften zeichnen sich zudem durch eine zunehmende Entkopplung der einzelnen Komponenten aus – ein Prozess, der als die „Große Entkopplung“ bezeichnet wird. Anstatt monolithischer Plattformen setzen Unternehmen inzwischen vermehrt auf modular gestaltete, spezialisierte Systeme. Das hat nicht zuletzt die Akzeptanz und Verbreitung von spezialisierten Abfrage-Engines gefördert. So hat beispielsweise DuckDB im Bereich kleiner bis mittelgroßer analytischer Workloads an Bedeutung gewonnen, während Polars mit seiner effizienten DataFrame-Verarbeitung bei Data Engineering-Prozessen punktet.
Für Echtzeitanalysen sind Engines wie StarRocks und ClickHouse führend, die auf hohe Concurrent-Belastungen und exzellente Kompressionsraten optimiert sind. Trino wiederum hat sich im Umfeld von föderierten Abfragen über verschiedene Datenquellen etabliert. Von zentraler Bedeutung sind in diesem Kontext auch einige wichtige Akteure der Branche. Databricks steht weiterhin für die führende Lakehouse-Plattform, hat jedoch zunehmend Herausforderungen zu bewältigen, da nicht alle Workloads von der Komplexität von Apache Spark profitieren. Snowflake revolutionierte mit seiner Cloud-Architektur die Trennung von Speicher und Berechnung, kämpft jedoch mit limitierten Möglichkeiten bei transaktionalen Workloads.
PostgreSQL hat sich als bevorzugtes relationales System neuer operativer Anwendungen etabliert. Dank Erweiterungen für Geodaten, Zeitreihenanalysen und AI-Workloads wächst es beständig über seine traditionellen Grenzen hinaus. Unternehmen wie Neon und Crunchy Data treiben die Entwicklung von serverlosen und analytisch erweiterten PostgreSQL-Diensten voran. Die Schwierigkeiten der HTAP-Umsetzung spiegeln sich in jüngsten Marktbewegungen wider. Sowohl Databricks als auch Snowflake haben namhafte PostgreSQL-orientierte Unternehmen übernommen, um ihre datenbankbasierten Fähigkeiten zu stärken.
Diese Strategien deuten darauf hin, dass eine Bereitstellung echter HTAP-Funktionalitäten eher in der Zusammensetzung spezialisierter Komponenten als in monolithischen Systemen gesehen wird. ClickHouse nimmt in diesem Ökosystem eine besondere Stellung ein. Der Anbieter setzt konsequent auf analytische Exzellenz und verzichtet bewusst auf transaktionale Funktionen. Dies zahlt sich aus: Durch fokussierte Optimierungen in den Bereichen Kompression, Abfragestruktur und Hardware-Nutzung erzielt ClickHouse beeindruckende Performancevorteile gegenüber Wettbewerbern. Die Integration in Streaming-Plattformen und Lakehouse-Formate unterstreicht außerdem den Trend hin zu spezialisierter und kompositorischer Architektur.
Neben diesen technologischen Entwicklungen spielt auch die Cloud-Infrastruktur eine wesentliche Rolle. Microsoft Azure etwa folgt häufig dem Markttrend durch Integration erprobter Technologien in seine Dienste. Mit Azure Data Lake Storage, Azure Synapse Analytics, Stream Analytics und Fabric bietet Azure eine Reihe von Komponenten, die bewährte Konzepte aufgreifen. Dennoch hinken diese Lösungen in Sachen Performance und Innovationskraft oft hinter den marktführenden Plattformen her. Für moderne Organisationen wie die FFMVIC-Systeme ergeben sich aus diesen Entwicklungen ganz konkrete Empfehlungen.
Bewährte relationale Datenbanken, speziell Azure SQL und PostgreSQL, sollten weiterhin für operative Systeme genutzt werden. Data Lakehouses stellen die bevorzugte Architektur für unstrukturierte und große Datenmengen dar, wobei Apache Iceberg als offenes Tabellensystem eingesetzt werden sollte. Zur Modernisierung von Datenpipelines eignen sich Azure Functions mit stark typisierten Sprachen wie C# oder TypeScript für einfache Aufgaben, während Python und insbesondere Polars für komplexere DataFrame-Operationen empfohlen werden. Nur für sehr große und verteilte Berechnungen empfiehlt sich der Einsatz von Apache Spark/Databricks. Das Einrichten von CDC-Mechanismen zur nahezu verzögerungsfreien Datenübertragung zwischen operativen Systemen und Data Lakehouses ist essenziell.