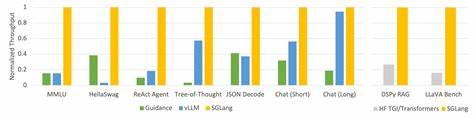
Die Welt der großen Sprachmodelle (Large Language Models, LLMs) erlebt derzeit einen rasanten Wandel. Die steigenden Anforderungen an Geschwindigkeit und Skalierbarkeit bei der Inferenz von LLMs fordern neue, leistungsfähige Systeme, die sowohl kleine als auch große Modelle effizient bedienen können. Ein bedeutender Fortschritt in diesem Bereich ist Tokasaurus, ein Inferenz-Server, der speziell für hochdurchsatzintensive Workloads entwickelt wurde und eine bis zu dreifach höhere Performance als etablierte Engines wie SGLang und vLLM erreicht. Tokasaurus ist das Ergebnis intensiver Forschung im Scaling Intelligence Lab der Stanford University. Ziel war es, die bestehende Softwarelandschaft durch ein System zu ergänzen, das durch besondere Optimierungen in CPU-Verwaltung, dynamische Erkennung von gemeinsam genutzten Präfixen und vielseitige Parallelisierungstechniken sowohl kleine als auch große Modelle auf modernsten GPUs optimal auslastet.
Ein entscheidender Faktor bei kleinen LLMs ist die Minimierung des CPU-Overheads. Traditionelle Engines haben oft mit Engpässen zu kämpfen, weil die CPU bei Aufgaben wie Tokenisierung, KV-Cache-Verwaltung und Postprocessing mit ihrem Pensum an Operationen nicht Schritt hält, was zu GPU-Stalls führt und die Durchsatzrate einschränkt. Tokasaurus begegnet diesem Problem mit einem adaptiven, asynchronen Manager, der die Eingangs-Queue des Modells überwacht und bei drohender Unterversorgung optional laufende Routineaufgaben prioritätsbasiert aussetzt. So läuft die GPU immer optimal ausgelastet, während die CPU-Leistungsreserven gezielt geschont werden. Ein weiteres Alleinstellungsmerkmal ist die dynamische Erkennung von gemeinsam genutzten Präfixen in den Eingabesequenzen.
In vielen Anwendungsszenarien, etwa beim Bearbeiten langer Dokumente oder beim vielfachen Sampling identischer Prompt-Bestandteile, treten immer wieder dieselben Anfangsparts der Sequenzen auf. Indem Tokasaurus diese Präfixe mit einem effizienten, gierigen Tiefensuch-Algorithmus vor jedem Forward-Pass identifiziert, kann die Berechnung der Aufmerksamkeitsschichten für diese gemeinsamen Teile deutlich optimiert werden. Dieses Verfahren, bekannt unter dem Konzept „Hydragen“, reduziert den Rechenaufwand insbesondere bei kleineren Modellen und verbessert dadurch die gesamte Verarbeitungsgeschwindigkeit signifikant. Bei großen LLMs ist die Herausforderung eine andere: Die Modelle sind oftmals so umfangreich, dass eine Ausführung auf einer einzelnen GPU entweder wegen Speicherbeschränkungen oder Kommunikationsengpässen nicht effizient möglich ist. Tokasaurus setzt hier auf eine Kombination aus Pipeline-Parallelismus und asynchronem Tensor-Parallelismus, um mehrere GPUs bestmöglich auszunutzen.
Pipeline-Parallelismus eignet sich vor allem für Umgebungen ohne schnelle NVLink-Verbindungen zwischen GPUs, wie etwa die NVIDIA L40S. Hier werden Eingabebatches in Mikro-Batches zerlegt, die nacheinander in den verschiedenen Pipeline-Stufen abgearbeitet werden. Tokasaurus optimiert diesen Prozess stark, sodass es in Benchmarks mit dem Llama-3.1-70B Modell auf acht L40S GPUs eine dreifach höhere Durchsatzleistung im Vergleich zu vLLM und SGLang erzielt. Für Hochleistungsumgebungen mit NVLink-fähigen GPUs wie den NVIDIA B200, H100 oder A100 kommt der Async Tensor Parallelismus zur Anwendung.
Dabei überlappt Tokasaurus die GPU-zu-GPU Kommunikation mit der eigentlichen Berechnung, was die Wartezeiten signifikant reduziert und so die gesamte Verarbeitung beschleunigt. Interessanterweise führt dieses Verfahren jedoch zu einem erhöhten CPU-Overhead und zeigt seine Vorteile erst bei sehr großen Batchgrößen, beispielsweise bei über 6000 Tokens. Um hier flexibel zu bleiben, hält Tokasaurus sowohl torch-kompilierte Versionen der Modelle mit als auch ohne aktivierten Async-TP bereit, sodass bei Bedarf automatisch gewechselt wird. Neben diesen technischen Innovationen zeichnet sich Tokasaurus auch durch seine Benutzerfreundlichkeit aus. Das System ist in reinem Python implementiert, was die Weiterentwicklung und individuelle Anpassung deutlich erleichtert.
Darüber hinaus steht der Code auf GitHub offen zur Verfügung und das Paket kann einfach über PyPI installiert werden. Aktuell unterstützt Tokasaurus Modelle aus der Llama-3- und Qwen-2-Familie und ermöglicht eine beliebige Kombination aus Daten-, Tensor- und Pipeline-Parallelismus innerhalb eines einzelnen Knotens. Die hohe Praxisrelevanz von Tokasaurus belegt sich auch in realen Benchmark-Szenarien: Für gängige Datensätze wie ShareGPT und GSM8K übertrifft es die Performance von vLLM und SGLang deutlich. Im speziellen Large Language Monkeys Benchmark, bei dem viele Antworten auf komplexe Mathematikprobleme generiert werden, erreicht Tokasaurus sogar mehr als doppelt so hohen Durchsatz wie die Konkurrenz. Mit Blick auf die Zukunft verspricht Tokasaurus für die KI-Community ein kraftvolles Werkzeug zur Bewältigung wachsender Datenmengen und komplexerer Fragestellungen.
Die Kombination aus adaptiven CPU-Management, dynamischer Präfix-Nutzung und intelligenter Parallelisierung ist ein Schritt hin zu noch effizienteren LLM-Inferenz-Services, die sowohl in Forschung als auch Industrie vielfältige Einsatzmöglichkeiten eröffnen. Darüber hinaus verdeutlicht das Projekt den Trend, dass reine LLM-Einbindung nicht mehr genügt – parallel zur Modellinnovation gewinnt die Infrastruktur-Optimierung zunehmend an Bedeutung, um die Leistung sinnvoll nutzbar zu machen. Tokasaurus steht für diese neue Generation von Engines, die nicht nur theoretische Kapazitäten ausloten, sondern praktische Herausforderungen im Alltag meistern und somit die Brücke zwischen theoretischem Potenzial und realer Anwendung schlagen. Für Entwickler, Forscher und Unternehmen, die auf der Suche nach einem leistungsstarken, flexiblen und zukunftssicheren Server für LLM-Inferenz sind, stellt Tokasaurus eine äußerst attraktive Alternative dar. Die durchdachte Architektur ermöglicht es, verschiedenste Hardwarekonfigurationen bestmöglich zu nutzen und sorgt so für signifikante Kosteneinsparungen und beschleunigte Entwicklungszyklen.
Abschließend lässt sich sagen, dass Tokasaurus nicht nur durch seine Geschwindigkeit besticht, sondern auch durch seine vielseitigen Optimierungen, die sich sowohl bei kleinen als auch großen Modellen auszahlen. In Zeiten, in denen die Verarbeitung von großen Textmengen und komplexen Aufgaben immer wichtiger wird, markiert diese Engine einen Meilenstein in der LLM-Inferenz und trägt wesentlich zur weiteren Verbreitung und Effizienzsteigerung moderner Sprachmodelle bei.