Die Entwicklung und Optimierung von Large Language Models (LLMs) erfordert effiziente Mechanismen, um die Aufmerksamkeitsschichten performant zu berechnen. SGLang, eine moderne Serving Engine für LLMs, hat mit der Version 0.4.6 Flash Attention als Standard-Backend eingeführt. Dieses Backend spielt eine entscheidende Rolle bei der Beschleunigung der Modellvorhersage und der Nutzung von GPU-Ressourcen.
Die Integration von Flash Attention mit einem ausgeklügelten KV Cache System liefert signifikante Performancevorteile, sowohl bei der Stapelverarbeitung als auch bei der inkrementellen Dekodierung. Im Kern dieser Innovation stehen eine tiefgreifende Architektur und ein intelligentes Speicher-Management, die viele der üblichen Engpässe beheben. Flash Attention selbst ist ein IO-bewusstes Algorithmusdesign, das darauf abzielt, den Datentransfer zwischen GPU-Hochgeschwindigkeitsspeicher und dem On-Chip SRAM durch intelligente Blockierung und Tiling-Mechanismen zu minimieren. Diese Strategie optimiert nicht nur die Speicherauslastung, sondern verringert auch den Energieverbrauch und steigert die Ausführungsgeschwindigkeit der Attention-Funktion, welche häufig der Flaschenhals bei der Inferenz großer Sprachmodelle ist. Flash Attention findet breite Anwendung sowohl im Training als auch im Inferencing von LLMs und ist mittlerweile in zahlreichen modernen Serving-Engines etabliert.
SGLang folgt einer modularen Architektur, die in Server-Komponenten, Scheduler und Modell-Komponenten unterteilt ist. Während die Server-Komponenten den Eingang und Ausgang von Anfragen steuern und der Scheduler die effiziente Batchbildung realisiert, konzentriert sich der Modell-Teil auf das Vorwärtspassen der Modelle. Hierbei ist der Aufruf der Attention-Backend-Methoden zentral, da sie die rechenintensiven Transformations- und Gewichtungsoperationen verwalten, die die Kontextbezüge in der Modellantwort liefern. Ein Schlüsselkonzept innerhalb der Attention-Backend-Implementierung in SGLang ist die Behandlung von verschiedenen Forward-Modi, insbesondere EXTEND und DECODE. Im EXTEND-Modus erweitert das Modell den Kontext mit neuen Tokens, während im DECODE-Modus eine schrittweise Vorhersage tokenweise erfolgt.
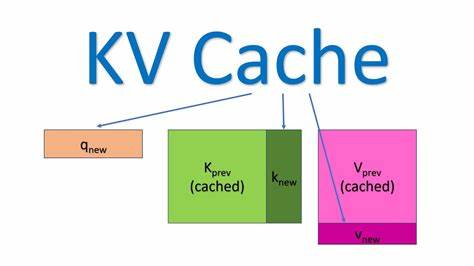
Das Flash Attention Backend ist so konzipiert, dass es diese beiden Modi nahtlos unterstützt und dabei die hohen Anforderungen an Leistung und Skalierbarkeit erfüllt. Das zentrale Element für effiziente Attention ist der KV Cache. In SGLang ist der KV Cache als mehrstufiges Speicherverwaltungssystem ausgelegt. Die erste Ebene, der req_to_token Pool, ordnet Anfragen ihre jeweiligen Token-Indizes im Cache zu. Dieses Mapping ermöglicht eine präzise Zuordnung von Anfragen zu den gespeicherten Key- und Value-Repräsentationen.
Die zweite Ebene, token_to_kv_pool, verwaltet die tatsächlichen Daten der KV Caches über alle Layer hinweg. Es handelt sich hierbei um ein tensorbasiertes Speicherlayout, das den Zugriff auf Schlüssel- und Wertvektoren für jede Attention-Head Position effizient handhabt. Der Umgang mit KV Cache ist in Flash Attention besonders relevant, da durch die Paged KV Cache Technik mehrere Tokens und ihre Repräsentationen gruppiert und adressiert werden. Die Funktion flash_attn_with_kvcache nimmt als Eingabe neben den Query-Tensoren auch die kompletten Seiten-Cache-Tabellen entgegen, wodurch aufwändige manuelle Zusammenstellungen überflüssig werden. Die Verwendung und Aktualisierung dieses Caches erfolgt dynamisch im Rahmen der Forward-Pass-Methoden, wodurch LLMs schnell und mit minimalem Speicher-Overhead dekodiert werden können.
Die praktische Implementierung umfasst die Initialisierung spezieller Metadaten in der Klasse FlashAttentionMetadata, welche in jedem Durchlauf der Modellvorhersage erneut verwendet werden. Dazu zählen unter anderem die Sequenzlängen, kumulative Sequenzlängen und die Seiten-Cache-Tabellen. Das sorgfältige Vorbereiten dieser Werte ist essenziell, da sie für die korrekte Portionierung der Daten über Batches und Layer hinweg sorgen und damit die Grundlage für eine effiziente CUDA-Kernel-Ausführung bilden. Neben der einfachen Forward-Verarbeitung kommt in SGLang das sogenannte CUDA Graph Feature zum Einsatz. Diese Technik ermöglicht es, mehrere GPU-Operationen als zusammenhängenden Graphen aufzunehmen und diesen als eine Einheit wiederholt auszuführen.
Das reduziert unerwünschte CPU-Overheads beim Kernel-Start und beschleunigt damit deutlich die Modellinferenz, vor allem bei kleinen und häufigen Rechenoperationen, wie sie in der Attention-Berechnung auftreten. Die Implementierung von CUDA Graph unterstützt in SGLang eine vorab definierte Batchgröße, für die feste Speicherbereiche im GPU-Speicher reserviert sind. In Methoden wie init_cuda_graph_state werden diese Speicherpuffer während des Serverstarts angelegt, um spätere Speicherreservierungen zu vermeiden. Die Metadaten für diese Prozesse werden in spezialisierten Datenspeichern wie decode_cuda_graph_metadata verwaltet, um den schnellen und sicheren Zugriff bei der Wiedergabe des CUDA Graphs zu gewährleisten. Die Abstimmung zwischen KV Cache und CUDA Graph ist eine technische Herausforderung, da die gespeicherten Caches während des Wiederholens des CUDA Graphs stets aktuell gehalten werden müssen.
SGLang löst dieses Problem durch separate Initialisierungsschritte für die Erfassung und Wiedergabe der Metadaten, die flexibel an den jeweiligen Forward-Modus angepasst werden. Somit können sowohl die klassische Stapel-Erweiterung als auch die Token-für-Token-Decodierung optimal ausgeführt werden. Die Basisimplementierung des Flash Attention Backends in SGLang wurde bereits erfolgreich in der Praxis getestet und liefert bei Benchmarks hervorragende Durchsatzwerte. Im Vergleich zu anderen Backends wie FlashInfer oder Triton zeigt Flash Attention besonders bei wachsender Kontextlänge seine Stärken und ist daher bestens für großskalige Anwendungen geeignet. Ein tieferes Verständnis der zugrundeliegenden Komponenten ist für Entwickler entscheidend, die eine eigene Backend-Implementierung oder Anpassungen vornehmen möchten.
Die klare Trennung der Metadaten-Verwaltung, die Nutzung praxiserprobter API-Aufrufe von Flash Attention und das strukturierte Management des KV Cache bilden die Basis für nachhaltige Performanceverbesserungen in Serverumgebungen. Darüber hinaus öffnet die offene Architektur von SGLang mit ihren klar definierten Interfaces und gut dokumentierten Checkout-Punkten die Tür für weiterführende Optimierungen. Die zukünftigen Erweiterungen umfassen unter anderem spekulatives Decoding, Multilayer-Attention Variationen, die Integration von Llama 4 Modellen sowie Unterstützung für multimodale Eingaben. Damit bleibt SGLang ein Innovationsmotor im Bereich LLM-Serving-Engines. Für Entwickler, die sich in die Materie einarbeiten möchten, empfiehlt es sich, neben dem Studium der Flash Attention Kernbibliotheken auch die KV Cache Management Strategien zu verstehen, da sie das Rückgrat der Aufmerksamkeitsberechnung bilden.
Der Umgang mit CUDA Graphen ist zudem ein zentrales Thema, um die Latenzen minimieren und die Gesamtsystemleistung zu steigern. Die Rolle der Open Source Community darf an dieser Stelle nicht unterschätzt werden. SGLang ist ein lebendiges Beispiel dafür, wie kollektive Intelligenz, kontinuierliche Verbesserung und transparente Prozesse zu state-of-the-art Lösungen beitragen können. Dabei ist die Hürde zum Einstieg in Projekte wie SGLang niedriger als oft angenommen, da auch kleinere Beiträge wie Dokumentation und Bugfixes die Entwicklung unterstützen und wertgeschätzt werden. Abschließend lässt sich sagen, dass die Implementierung des Flash Attention Backends in SGLang nicht nur die Effizienz moderner LLM-Serving-Engines maßgeblich vorantreibt, sondern auch neue Möglichkeiten für individuell skalierbare und anpassbare Systeme eröffnet.
Der gezielte Einsatz von KV Cache Management und CUDA Graph Integration liefert eine robuste Grundlage, auf der zukünftige Innovationen im Bereich der KI-Modelle aufbauen können.