In den letzten Jahren hat die Nutzung von künstlicher Intelligenz (KI) und speziell von großen Sprachmodellen wie ChatGPT die Art und Weise revolutioniert, wie Menschen online Informationen suchen und konsumieren. Anstelle der herkömmlichen Suchmaschinen wie Google greifen immer mehr Nutzer direkt auf KI-gestützte Tools zu, um schnelle und präzise Antworten auf ihre Fragen zu erhalten. Diese Veränderung hat eine ganz neue Dynamik für Webseitenbetreiber und Content-Ersteller geschaffen, deren Inhalte von Web-Scraping Bots genutzt werden, die von diesen KI-Diensten betrieben werden. Dabei stellt sich eine fundamentale Frage: Wie lässt sich der immense Traffic, der durch diese KI-Bots generiert wird, überhaupt monetarisieren? Die Antwort ist komplex und weist auf tiefgreifende Herausforderungen hin, die die digitale Wirtschaft vor neue Prüfsteine stellen. Der Begriff Web-Scraping bezeichnet das automatisierte Auslesen von Webinhalten durch sogenannte Bots.
Ursprünglich wurden diese Bots vor allem von Suchmaschinen eingesetzt, um Webseiten zu indexieren und so die Suchergebnisse relevant und aktuell zu halten. Doch im Kontext von KI hat sich das Einsatzfeld dieser Bots erweitert. Moderne KI-Dienste, die auf natürliche Sprachverarbeitung spezialisiert sind, schicken ihre eigenen Scraping-Bots aus, um ganze Webseiten auszulesen und Inhalte in ihre Datenbanken zu übernehmen. Ihre Aufgabe ist es, Informationen zusammenzufassen und Nutzern in Form von Antworten oder Zusammenfassungen bereitzustellen – oft ohne dass diese Nutzer die Originalquelle des Contents besuchen. Das führt zwar zu einem enormen Anstieg des Traffics auf den betroffenen Webseiten, doch die Monetarisierung gestaltet sich weitaus schwieriger als bei herkömmlichen Besuchern.
Viele Webseiten finanzieren sich über Werbeanzeigen, die von echten menschlichen Nutzern gesehen und angeklickt werden. KI-Bots hingegen erzeugen zwar Traffic, konsumieren dabei aber keine Werbung. Das bedeutet, dass die Vermarkter dieser Webseiten trotz steigender Zugriffszahlen kaum zusätzliche Werbeeinnahmen verzeichnen können. Für Nachrichtenportale und andere informationsbasierte Anbieter ist dies besonders kritisch, zumal immer mehr Bots die herkömmlichen Zugriffsmuster verändern und die klassische Klickrate auf Anzeigen reduzieren. Darüber hinaus lehnen viele KI-Unternehmen das Zahlen für den Content ab, den ihre Bots aus dem Web sammeln.
Sie argumentieren, dass das Auslesen und Aggregieren von Inhalten unter „Fair Use“ oder vergleichbaren Rechtsgründen zulässig sei. Für Webseitenbetreiber bedeutet dies, dass sie ihr geistiges Eigentum kostenfrei zur Verfügung stellen müssen, während die KI-Anbieter daraus wirtschaftlichen Nutzen ziehen. Dies wird auch dadurch erschwert, dass viele Bots sogenannte „intelligente Agenten“ bedienen, die im Auftrag von Nutzern komplexe Aufgaben erledigen und dabei mehrere Quellen durchsuchen. Diese Bots sind oft schwer als solche zu identifizieren und umgehen herkömmliche Schutzmechanismen wie das Robots.txt-Protokoll, das Webseiten für Suchmaschinen-Bots definiert, welche Inhalte deren Crawling gestatten oder verweigern.
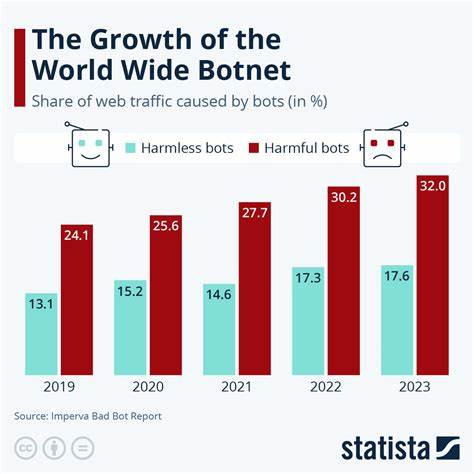
Die Dramaturgie dieses Wandels ist besonders in Zahlen greifbar. Eine Studie eines Start-ups, das auf das Monitoring von Web-Scraping spezialisiert ist, zeigt, dass der Traffic von Retrieval-Bots zwischen dem vierten Quartal 2024 und dem ersten Quartal 2025 um 49 Prozent gestiegen ist. Noch dramatischer ist das Wachstum bei Bots, die darauf spezialisiert sind, Daten für das Training von KI-Modellen zu extrahieren – hier wuchs der Traffic sogar 2,5-fach schneller. Neben der schieren Menge an Datenanfragen führt dies auch zu erheblichen Mehrkosten für Hosting-Anbieter und Webseitenbetreiber, da der erhöhte Datenverkehr den Bandbreitenverbrauch und die Serverlast enorm ansteigen lässt. Die unmittelbaren Folgen daraus sind vielfältig.
Kleinere Webseiten, die nur begrenzte Ressourcen zur Verfügung haben, geraten schnell an ihre technischen und finanziellen Grenzen. Sie tragen die Kosten für die Bereitstellung der Inhalte, profitieren jedoch nur marginal oder gar nicht vom daraus resultierenden Traffic. Bei größeren Nachrichtenorganisationen entstehen Verhandlungen mit KI-Anbietern, um Lizenzvereinbarungen durchzusetzen. Einige Medienunternehmen haben bereits erfolgreich Deals mit Firmen wie OpenAI und Perplexity abgeschlossen – ein Schritt, der von vielen als wegweisend angesehen wird. Dennoch steht die Branche noch am Anfang dieser Entwicklung, und es bleibt unklar, in welchem Umfang sich solche Modelle durchsetzen und ob sie skalierbar sind.
Vor diesem Hintergrund müssen Webseitenbetreiber strategisch umdenken. Die klassische Ausrichtung auf menschliche Nutzer und deren Interaktion mit Werbung genügt bald nicht mehr. Stattdessen gilt es, die Anforderungen und Charakteristika von KI-Bots zu verstehen und die Webseiten entsprechend anzupassen. Das bedeutet unter anderem, KI-gerechte Inhalte bereitzustellen, die maschinenlesbar, strukturiert und für automatische Verarbeitung optimiert sind. Gleichzeitig könnten alternative Monetarisierungsmodelle notwendig werden, wie beispielsweise APIs, über die Bots gegen Gebühr Zugriff auf Inhalte erhalten.
Auch der Einsatz von Paywalls oder speziellen Lizenzmodellen für KI-gestützte Nutzung ist eine Möglichkeit – wobei hier die Balance zwischen Zugänglichkeit und Schutz des geistigen Eigentums schwierig zu finden ist. Technische Gegenmaßnahmen wie Bot-Blocker oder das Ignorieren von Bots mittels Robots.txt stoßen angesichts der immer intelligenteren KI-Agenten zunehmend an ihre Grenzen. Viele Bots umgehen solche Regeln entweder bewusst oder sind rechtlich nicht verpflichtet, sie zu beachten, da sie als „User Agents“ im Auftrag von echten Nutzern agieren. Dies erschwert eine eindeutige Identifikation und Regulierung.
Einige Experten schlagen daher vor, dass der Standard für Robots.txt erweitert und präziser gestaltet werden sollte – etwa durch zusätzliche Angaben zur Art des Bots, dessen Aufgabenbereich und Nutzungsbedingungen inklusive etwaiger Gebühren. Diese Idee, so vielversprechend sie klingt, scheitert aktuell aber noch an der praktischen Umsetzung und der geringen Rechtsverbindlichkeit solcher Standards. Der gesellschaftliche Diskurs um diese Entwicklung ist ebenfalls kontrovers. Während Content-Ersteller vehement die Zahlung für die Nutzung ihrer Werke fordern, sieht ein Teil der Öffentlichkeit Web-Scraping als legitime Nutzung oder sogar als Cool-Down-Maßnahme gegen Clickbait und schlechte Inhalte.
Künstliche Intelligenz erlaubt es, Informationen schneller und oft klarer zusammenzufassen, was für Nutzer durchaus positive Aspekte haben kann. Allerdings besteht die Gefahr, dass die ursprünglichen Inhalte entwertet werden und langfristig weniger qualitativ hochwertiger Content produziert wird, wenn die Monetarisierung ausbleibt. Außerdem entstehen durch den umfangreichen Einsatz von Web-Scraping-Bots auch technische und ethische Fragen. Die starke Belastung der Server kann bei kleineren Seiten zu Ausfällen und Leistungseinbußen führen, was wiederum die Nutzererfahrung beeinträchtigt. Das unkontrollierte Sammeln von Inhalten kann außerdem Datenschutzrisiken bergen, wenn sensible oder personenbezogene Daten ohne Erlaubnis extrahiert werden.
Auf rechtlicher Ebene gibt es noch keine einheitlichen Regelungen, die den Umgang mit KI-gestütztem Scraping umfassend beantworten. Zukunftsweisend könnte eine öffentlich-private Zusammenarbeit sein, die technische Standards, rechtliche Rahmenbedingungen und wirtschaftliche Modelle kombiniert. Gesetzgeber könnten klare Mindestanforderungen für die Identifikation und Behandlung von KI-Bots festlegen und für eine bessere Transparenz und Fairness sorgen. Gleichzeitig sind Innovationen im Bereich des Content-Managements nötig, die es Content-Anbietern erlauben, genau zu steuern, wie und unter welchen Bedingungen deren Daten von KI-Systemen genutzt werden dürfen. Trotz der vielen Herausforderungen birgt die Entwicklung auch Chancen.
Webseiten, die frühzeitig auf die Bedürfnisse von KI-Systemen eingehen und ihre Inhalte entsprechend aufbereiten, können sich als bevorzugte Quellen etablieren. Neue Geschäftsmodelle, die über klassische Werbung hinausgehen, könnten nachhaltige Einnahmequellen erschließen. Darüber hinaus könnten verbesserte Analysetools helfen, KI-Traffic besser zu verstehen und differenzierte Angebote für verschiedene Nutzergruppen zu entwickeln. So könnten sich die Rollen im digitalen Ökosystem neu definieren und an die Anforderungen einer KI-geprägten Zukunft anpassen. Insgesamt steht das Internet an einem Scheideweg.
Der traditionelle, menschzentrierte Zugang wird zunehmend durch KI-Vermittlung ergänzt oder sogar ersetzt. Für Webseitenbetreiber bedeutet dies, dass sie flexibel reagieren und ihre Strategien an die veränderten Rahmenbedingungen anpassen müssen. Nur wer die Balance findet zwischen offenem, zugänglichem Content und einem tragfähigen Monetarisierungsansatz für KI-gesteuerten Traffic wird in der sich schnell wandelnden digitalen Welt bestehen können.