In der heutigen vernetzten Welt gewinnt die Datenverfügbarkeit und -konsistenz zunehmend an Bedeutung. Egal, ob es darum geht, verschiedene Unternehmenssysteme miteinander zu verbinden, eine Suchindexierung aktuell zu halten oder Benutzerprofile in externen Anwendungen synchron zu halten – die Herausforderung bleibt die gleiche: Wie können Daten zuverlässig und effizient zwischen mehreren Datenquellen und Zielen synchronisiert werden? Synchronisation bedeutet im Kern, dass verschiedene Datenbestände exakt denselben Zustand widerspiegeln, sodass sämtliche Änderungen im Quellsystem korrekt und konsistent im Zielsystem abgebildet werden. Auf den ersten Blick mag dies einfach erscheinen, wird in der Praxis jedoch oft unterschätzt und führt zu komplexen Problemen und inkonsistenten Datenzuständen. Die wesentliche Ursache liegt darin, dass viele Projekte replizierende Systeme ohne das notwendige Bewusstsein implementieren und dabei inkrementelle Lösungen ad-hoc entwickeln, die im Produktionsumfeld nicht stabil oder konsistent arbeiten. Bei Unternehmen, die aus verschiedenen Gründen auf Datenintegration angewiesen sind, zeigt sich häufig, dass die beteiligten Systeme heterogen sind und unterschiedliche Mechanismen zur Veränderung und Speicherung von Daten besitzen.
Das erschwert die Verwaltung von Datenänderungen enorm, denn es fehlt oft an einer globalen, einheitlichen Reihenfolge und Kontrolle der Ereignisse. Hinzu kommt die Unsicherheit durch mögliche Fehlerquellen wie Netzwerkprobleme, Transaktionsabbrüche oder asynchrone Verarbeitung, die den Zustand der Daten in Zielsystemen unvorhersehbar beeinflussen können. Ein naheliegender Lösungsansatz ist das klassische ETL-Verfahren (Extract, Transform, Load). Dabei wird die Zielsystem-Datenbank in regelmäßigen Abständen komplett oder teilweise neu aufgebaut, indem die Daten aus der Quelle extrahiert, transformiert und anschließend neu geladen werden. Dieser Prozess hat gegenüber inkrementellen Verfahren den Vorteil, dass er verhältnismäßig einfach zu implementieren ist und Fehler durch einen kompletten Neuaufbau korrigiert werden können.
Allerdings liegt darin auch ein großer Nachteil: Diese Methode ist oft sehr langsam und erzeugt eine schlechte Datenkonsistenz, da das Zielsystem während des Aufbaus veraltet oder inkonsistent sein kann. Insbesondere bei großen Datenmengen und bei Anforderungen für Echtzeitsynchronisierung ist der ETL-Ansatz nicht zufriedenstellend. Mehr Dynamik und Aktualität erfordern daher inkrementelle Replikationsverfahren, die nur geänderte Daten übertragen und sofort auf Änderungen reagieren. Die gängigste aber auch problematischste Herangehensweise ist das sogenannte „Waiting for Changes“-Prinzip, bei dem Event-Listener oder Hooks direkt im Quellsystem implementiert werden, um auf Datenänderungen zu reagieren und die Änderungen ins Ziel zu übertragen. Prinzipiell klingt diese Idee logisch, doch sie weist erhebliche Schwächen auf.
Zum einen entstehen Inkonsistenzen, wenn nicht alle relevanten Änderungspfade erkannt werden oder wenn Änderungen außerhalb der regulären Verarbeitungsvorgänge durchgeführt werden, also etwa über direkte Datenbankzugriffe, welche die Hooks umgehen. Zum anderen können ontologische Unterschiede der Datenmodelle von Quelle und Ziel dazu führen, dass manche Informationen nicht eins zu eins abgebildet werden können. Transaktionsabbrüche und Rollbacks im Quellsystem können einen weiteren Fehlerbereich eröffnen, da eventuelle Nebenwirkungen der Hooks bereits ausgeführt wurden, obwohl die zugrundeliegende Transaktion nicht abgeschlossen wurde. Folge davon sind inkonsistente Zustände im Ziel, die schwer zu bereinigen sind. Ein zusätzlicher Stolperstein ergibt sich aus der Verarbeitung asynchroner Ereignisse, die möglicherweise zeitlich oder inhaltlich nicht in der Herkunftsreihenfolge bearbeitet werden.
Dies ist fatal, da viele Datenänderungen nicht vertauschbar sind und Reihenfolgeänderungen zu falschen Datenständen führen können. Traditionelle Event-Listener-Lösungen ohne umfassendes Zustands-Management sind daher anfällig für verlorene oder doppelte Updates. Der Umgang mit Alt-Daten verstärkt die Problematik: Da Event-Listener erst ab einem bestimmten Zeitpunkt die Änderungen protokollieren, benötigt man eine separate Methode, um bestehende Daten zu initialisieren und danach zu konsolidieren. Dies führt oft zu staubigen, schwer wartbaren Speziallösungen mit Stringenzverlust. Daher ist ein Umdenken bei Replikationssystemen erforderlich, um Konsistenz und Zuverlässigkeit sicherzustellen.
Die Grundlage für eine professionelle Synchronisation ist die Definition einer klaren, nachvollziehbaren und überprüfbaren Synchronisationslogik. Ein Konzept, das sich bewährt hat, ist der Ansatz des „Diff und Patch“. Hierbei wird der Zustand eines Datensatzes im Ziel systematisch mit dem des Quellensystems verglichen. Differenzen werden als „Diff“ identifiziert, während der „Patch“ beschreibt, welche konkreten Schritte im Ziel notwendig sind, um die Diskrepanzen auszugleichen und somit den Zielstatus an den Quellstatus anzugleichen. Dieser Vorgang muss idempotent sein, also beliebig oft wiederholbar, ohne Nebenwirkungen zu verursachen.
Auf diese Weise können Fehler und Unterbrechungen sicher kompensiert werden: Fällt die Synchronisation zeitweise aus, kann sie jederzeit erneut ausgeführt werden, bis der Zielzustand mit dem Quellzustand übereinstimmt. Die Umsetzung eines diff/patch-Mechanismus erlaubt außerdem eine einfache Integration von Alt-Daten und neuen Änderungen mit demselben Codepfad, was die Wartbarkeit und Zuverlässigkeit deutlich erhöht. Ein Beispiel aus der Praxis verdeutlicht den Unterschied. Angenommen, die Quelle enthält ein Benutzerkonto mit Standort „London“ und Freunden „Bob“, „Carol“ und „Dave“. Das Zielsystem hingegen zeigt denselben Benutzernamen, aber mit Standort „Berlin“ und als Freunde „Bob“, „Dave“ und „Eve“.
Der Diff würde erkennen, dass der Standort anders ist, „Carol“ in der Freundesliste fehlt und „Eve“ entfernt werden muss. Der Patch könnte entsprechend lauten: Standort auf „London“ setzen, „Carol“ hinzufügen, „Eve“ entfernen. In der Umsetzung kann dies unterschiedlich aussehen, je nach Datenmodell – etwa als vollständiges Austausch-Dokument in einem Dokumentstore oder als gezielte SQL-Updates in einer relationalen Datenbank. Neben einer klaren Diff- und Patch-Logik ist es wichtig, einen effizienten Mechanismus zu haben, um stets nur die Datensätze zu synchronisieren, die tatsächlich Änderungen erfahren haben. Andernfalls würde man wie beim ETL-Ansatz alle Daten durchlaufen, was ineffizient und langsam ist.
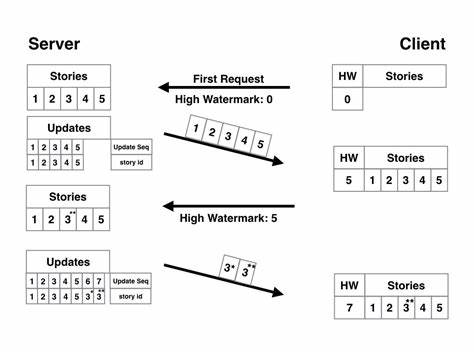
Zwei verbreitete Methoden zur Änderungsidentifikation sind die Nutzung von Änderungsmarkierungen und Ereignisprotokollen. Die Änderungsmarkierung implementiert eine Art Zähler oder Flag an jedem Datensatz, der bei einer Änderung erhöht und nach erfolgreicher Synchronisation zurückgesetzt wird. Das stellt sicher, dass auch während der Synchronisationsausführung eingehende Änderungen erkannt und später nachverfolgt werden. Bei paralleler oder mehrfacher Verarbeitung derselben Datensätze ist darauf zu achten, dass nur eine Synchronisationsoperation gleichzeitig läuft, um Konflikte zu vermeiden. Die zweite Variante basiert auf einem Ereignisprotokoll, in das bei jeder Änderung ein Event geschrieben wird.
Ein separater Konsument verarbeitet die Events nacheinander und führt für jeden betroffenen Datensatz die Synchronisation durch. Diese Methode ist dem Event-Sourcing ähnlich und erfordert, dass das Protokoll zuverlässig alle Änderungen protokolliert und Events erst entfernt werden, wenn die Synchronisation abgeschlossen bestätigt wurde. Es ist nicht zwingend notwendig, dass das Event-Protokoll eine globale Reihenfolge einhält, da diese oft gar nicht darstellbar ist – die Reihenfolge dient vielmehr als Signal, welche Datensätze bearbeitet werden sollen. Für beide Methoden gilt, dass eine idempotente Synchronisationsfunktion die Folgeprobleme von mehrfachen oder verspäteten Updates beherrscht und so eine zuverlässige Synchronisation garantiert. Bei der Auswahl zwischen Änderungsmarkierungen und Event-Protokollen sollten Faktoren wie Infrastruktur, Volumen der Änderungen und Konsistenzanforderungen berücksichtigt werden.
Moderne verteilte Datenbanken wie Apache CouchDB unterstützen solche Konzepte bereits nativ. CouchDB verfügt über eingebaute Replikationsmechanismen und eine nahezu perfekte Infrastruktur zur Ereignisprotokollierung über den _changes-Feed. So kann eine Synchronisation einfach angestoßen und verwaltet werden. Die konsistente Verwaltung von Revisionsnummern und Dokumentinstanzen erzeugt eine formal verifizierbare Grundlage, auf der Differenzen identifiziert und ausgebessert werden können. Außerdem bietet CouchDB die Möglichkeit, verteilte Systeme zu bedienen, die einzelsträngig unzuverlässig oder offline arbeiten.








