In der Welt der Künstlichen Intelligenz und der großen Sprachmodelle (Large Language Models, LLMs) rücken Effizienz und optimale Ressourcennutzung immer mehr in den Mittelpunkt. Unternehmen und Entwickler stehen vor der Herausforderung, für unterschiedliche Aufgaben stets das am besten geeignete Sprachmodell einzusetzen – sei es aus Gründen der Geschwindigkeit, Kosten oder in puncto Genauigkeit. NVIDIA hat mit dem LLM Router eine wegweisende Open-Source-Lösung entwickelt, die genau diese Herausforderungen adressiert. Diese Technologie ermöglicht intelligentes Prompt-Routing in Multi-LLM-Deployments und rundet so die Nutzung von Sprachmodellen effizienter und flexibler ab. Der Kern der Problematik liegt in der Vielfalt der Anwendungsfälle und der dementsprechend variierenden Anforderungen an Sprachmodelle.
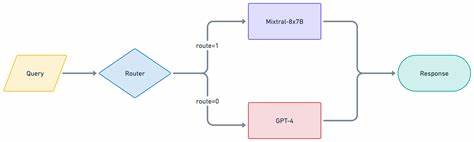
Während ein großes, hochpräzises Modell bei komplexen Textgenerierungsaufgaben zwar exzellente Resultate liefert, ist es gleichzeitig kostspieliger und in der Antwortzeit langsamer als kleinere Modelle. Andererseits bieten kleinere oder spezialisierte Modelle häufig schnellere Antwortzeiten und geringere Kosten, sind jedoch nicht immer für alle Aufgaben prädestiniert. Hier tritt der LLM Router in Erscheinung – er entscheidet eigenständig, welcher Prompt an welches Modell weitergereicht wird, basierend auf der jeweiligen Aufgabe und Komplexität. Die Architekturlösung von NVIDIA gliedert sich im Wesentlichen in drei Komponenten. Zunächst gibt es den Router Controller, der als eine Art Proxy fungiert.
Dieser nimmt eingehende Anfragen im OpenAI-API-Format entgegen und steuert das Routing der Prompts in Richtung des passenden Modells. Der Controller ist in Rust implementiert, was eine hohe Performance bei minimaler Latenz gewährleistet. Im Zentrum steht außerdem der Router Server, der mithilfe vortrainierter Klassifizierungsmodelle die Nutzeranfrage interpretiert und klassifiziert. Dabei unterscheidet er verschiedenste Aufgaben wie Codegenerierung, offene Frage-Antwort-Systeme (Open QA), Textumformulierungen oder kreative Aufgaben. Die Routingentscheidungen basieren auf einem flexiblen Politik- und Klassifikationssystem, das entweder durch Task- oder Komplexitäts-Router Polyen geleitet wird.
Die dritte Komponente bilden die downstream LLMs, also die großen Sprachmodelle selbst, die dann die eigentliche Verarbeitung und Textgenerierung übernehmen. Die Flexibilität des LLM Routers spiegelt sich stark in seiner Konfigurierbarkeit wider. Entwickler können nicht nur auf Standard-Policies zurückgreifen, sondern eigene Klassifizierungsmodelle trainieren und in den Routingprozess integrieren. So lässt sich beispielsweise ein speziell auf Supportanfragen zugeschnittener Router realisieren oder ein Modell zur Analyse von Bankkundeninteraktionen einbinden. Die Vielzahl der unterstützten LLMs ist ein weiterer Pluspunkt.
NVIDIA setzt in ihrem Blueprint auf eigene Modelle wie meta/llama-3.1-70b-instruct oder mistralai/mixtral-8x22b-instruct, harmoniert aber auch mit Drittanbieter-APIs und lokal gehosteten Modellen. Diese Offenheit garantiert Entwicklerfreiheit und vielseitige Einsatzmöglichkeiten. Besonders beeindruckend ist die nahtlose Kompatibilität mit der OpenAI API. Die Integration in bestehende Systeme gestaltet sich einfach, was die Akzeptanz und Nutzung der Lösung in der Entwicklergemeinde deutlich fördert.
Anwender müssen lediglich geringfügige Metadaten im Anfragekörper angeben, um Routing-Politiken und Strategien auszuwählen. Die Möglichkeit, zwischen automatischem Klassifizieren durch den Router und manueller Override-Funktion zu wählen, schafft zusätzlich Spielräume für maßgeschneiderte Einsätze. Ein entscheidender Gesichtspunkt bei der Entwicklung war die Performance-Optimierung. Die Implementierung in Rust sowie die Nutzung von NVIDIA Triton Inference Server sorgen für eine zügige Klassifikation und Weiterleitung der Anfragen. Gerade in produktiven Umgebungen mit hohen Anfragevolumina ist dies ein nicht zu unterschätzender Vorteil.
So lässt sich das System skalieren und an individuelle Anforderungen anpassen, ohne signifikante Verzögerungen in der Benutzerinteraktion zu riskieren. Was die Anwenderfreundlichkeit angeht, bietet der LLM Router eine durchdachte Dokumentation und ein Jupyter-Notebook zum schnellen Einstieg. Für den Betrieb wird ein moderner Linux-Server mit CUDA-kompatibler GPU vorausgesetzt. Die Nutzung von Docker und Docker Compose erleichtert zudem die Installation und den Betrieb in containerisierten Umgebungen. Interessant für MLOps-Teams ist auch die automatische Erfassung von Metriken, welche sich über Prometheus an Dashboards wie Grafana anbinden lassen.
Damit sind Monitoring und Performanceüberwachung aus einer Hand gewährleistet. Der Sicherheitsaspekt wurde ebenso berücksichtigt, wenn auch der Blueprint selbst eher als Referenzlösung mit Baukastencharakter gilt. Nutzer sind angehalten, eigene Security-Konzepte zu implementieren, um API-Schlüssel sicher zu verwalten und Zugriffsrechte zu steuern. Logdaten enthalten unter Umständen sensible Informationen wie Eingabeaufforderungen und generierte Antworten, weshalb im produktiven Betrieb Empfehlungen für verschärfte Logging- und Audit-Strategien bestehen. Der Nutzen für Entwickler, die mit KI-Systemen arbeiten, liegt auf der Hand.
Der LLM Router erlaubt eine intelligente und dynamische Arbeitsverteilung auf verschiedene Sprachmodelle, was Kosten senkt und die Antwortqualität erhöht. Für Unternehmen bedeutet das eine erhöhte Skalierbarkeit der KI-Dienste bei gleichzeitiger Erhaltung der gewünschten Leistungseigenschaften. Zudem unterstützt das System aktive Modellstrategie-Entwicklungen durch leicht anpassbare Richtlinien und bietet damit eine Basis für Innovation. Zusammenfassend lässt sich sagen, dass NVIDIA mit dem LLM Router ein modernes Werkzeug bereitstellt, das den Umgang mit multiplen großen Sprachmodellen in der praktischen Anwendung revolutionieren kann. Seine offene Architektur, die einfache Integration in bestehende Ecosysteme und die hohe Performance machen ihn zu einem wertvollen Instrument insbesondere für Entwickler und Teams, die auf Effizienz und Qualität in der Nutzung großer Sprachmodelle Wert legen.
Die Förderung von Community-Beiträgen und die Erweiterbarkeit des Systems bieten darüber hinaus spannende Perspektiven für die Zukunft der KI- Infrastruktur. Wer sich mit der Zukunft von Sprach-KI und deren produktivem Einsatz beschäftigt, sollte den LLM Router auf jeden Fall genauer in Augenschein nehmen.