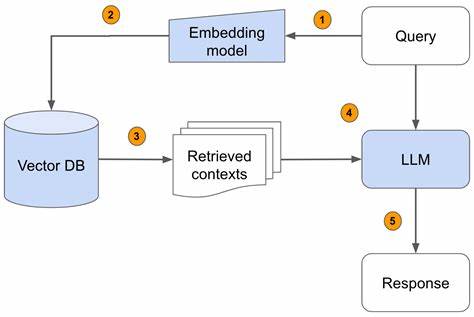
In einer Welt, die von einer enormen Flut an Informationen geprägt ist, gewinnt die Fähigkeit, relevante Daten schnell und präzise zu recherchieren, immer mehr an Bedeutung. Klassische Suchmaschinen und manuelle Recherchen stoßen oft an ihre Grenzen, vor allem wenn es darum geht, komplexe Fragestellungen tiefgründig zu analysieren und strukturiert aufzubereiten. An dieser Stelle setzt Datasleuth an – ein modernes, modular aufgebautes Forschungsframework, das auf leistungsstarken sogenannten Large Language Models (LLM) basiert und mit TypeScript implementiert ist. Datasleuth erlaubt es, natürliche Sprachabfragen automatisch in strukturierte, verifizierte und interpretierbare Daten umzuwandeln und damit den Forschungsprozess erheblich zu beschleunigen und zu verbessern. Die Grundidee hinter Datasleuth ist es, intelligente Forschungs-Pipelines zu konstruieren, die aus mehreren Phasen bestehen: Planung, Websuche, Inhaltsextraktion, Faktenprüfung, Analyse und zusammenfassende Aufbereitung.
Dabei greift das System auf diverse LLMs verschiedener Anbieter zurück, um die einzelnen Arbeitsschritte effizient durchzuführen und noch dazu anpassbar daran zu arbeiten. So entsteht ein flexibles Ökosystem, das je nach Bedarf vom einfachen Sammeln bis hin zum komplexen, mehrstufigen Forschungsvorgang synthetische, valide Ergebnisse generiert. Im Kern macht Datasleuth die Informationsbeschaffung zu einem automatisierten und zugleich adaptiven Prozess. Nutzer können eine Fragestellung in natürlicher Sprache eingeben – etwa „Aktuelle Fortschritte in der Quantencomputing-Forschung“ – und erhalten am Ende eine strukturierte Übersicht mit einer Kurzfassung, den wesentlichen Erkenntnissen, dazugehörigen Quellenverweisen und analytischen Auswertungen. Der Clou liegt darin, dass während der Recherche mehrere Schritte intelligent verknüpft werden, um die besten und vertrauenswürdigsten Daten zu filtern, zu überprüfen und zu interpretieren.
Datasleuth bietet eine Vielzahl von Funktionen, die sowohl für einzelne Nutzer als auch für Unternehmen interessant sind. Eine der Schlüsselkomponenten ist die automatische Planung mittels KI-gestützter Strategien, welche vor Beginn der Recherche einen zielführenden Plan entwickelt, um das Thema aus unterschiedlichen Perspektiven effizient zu bearbeiten. Die anschließende Websuche agiert flexibel mit diversen Suchanbietern, einschließlich Google und Bing, wodurch verschiedenartige Informationsquellen erschlossen werden können. Der Fokus auf umfangreiche Inhaltsextraktion erlaubt es, aus Webseiten-Inhalten, Artikeln oder wissenschaftlichen Berichten relevante Datenpunkte herauszufiltern. Besonders erwähnenswert ist die optionale Faktenprüfung, die mithilfe von KI-Algorithmen die Zuverlässigkeit gefundener Aussagen bewertet und gegebenenfalls Gegenbeweise hinzuzieht.
Dies reduziert die Gefahr, Fehlinformationen weiterzuverbreiten und stärkt die Vertrauenswürdigkeit der Resultate. Darüber hinaus ermöglicht eine integrierte Analysefunktion die Tiefenbewertung ermittelter Informationen anhand definierter Schwerpunkte wie technischer Details oder ökonomischer Relevanz. Am Ende steht eine klar verständliche Zusammenfassung, die alle wichtigen Erkenntnisse prägnant und übersichtlich darstellt. Für Entwickler ist Datasleuth aufgrund seiner modularen Architektur äußerst attraktiv: Die einzelnen Pipeline-Schritte sind separat konfigurierbar und lassen sich leicht an individuelle Anforderungen anpassen oder um eigene Funktionalitäten erweitern. Die Integration in bestehende Anwendungen wird durch die Unterstützung verschiedener LLM-Anbieter und durch eine breite API abgerundet.
Dabei ist die Technologie so ausgelegt, dass parallele Forschungsmodule gleichzeitig ablaufen und sogar unterschiedliche Aspekte oder Quellen miteinander kombiniert werden können – ein großer Vorteil bei umfassenden Rechercheprojekten. Ein weiterer Pluspunkt ist die Möglichkeit der Agenten-Orchestrierung. Dabei steuert eine KI-Agenten-Instanz dynamisch, welche Forschungsschritte als nächstes ausgeführt werden, abhängig von den bisherigen Ergebnissen und definierten Zielsetzungen. Diese adaptive Forschung spart Zeit und Ressourcen, denn unnötige Schritte werden vermieden und das System kann sich auf vielversprechende Spuren konzentrieren. Die Grenzen der maschinellen Forschung werden so deutlich verschoben, da komplexe, iterative Abläufe automatisiert und überwacht werden.
Nicht zuletzt glänzt Datasleuth durch eine umfangreiche Fehlerbehandlung. Verschiedene Fehlerarten, wie Konfigurationsprobleme, Validierungsfehler, Kommunikationsprobleme mit LLMs oder Suchanbietern sowie Zeitüberschreitungen werden differenziert behandelt. Dies bietet Entwicklern wertvolle Hinweise zur Behebung und sorgt für robuste, produktive Anwendungen. Die Einsatzgebiete von Datasleuth sind enorm vielfältig. Im akademischen Umfeld ermöglichen die automatisierten Pipelines eine tiefgreifende Literaturrecherche mit faktenbasierter Auswertung, was die Vorbereitung von Forschungsarbeiten oder Reviews massiv erleichtert.
Unternehmen profitieren von Marktforschungsreports, die Trends und Chancen differenziert analysieren, ohne Dutzende von Stunden manueller Suche und Auswertung. Medien und Journalisten können komplexe Themen schneller aufarbeiten und mit zuverlässigen Quellen belegen. Und letztlich bietet das Tool auch Entwickler-Communities eine flexible Basistechnologie, um eigene datengetriebene Anwendungen zu realisieren. Datasleuth ist zwar noch in einem frühen Entwicklungsstadium, zeigt jedoch bereits heute das Potenzial, die Forschungslandschaft zu verändern. Die intuitive Schnittstelle, kombiniert mit der Kraft moderner LLMs und einer klaren Ausrichtung auf strukturierte, geprüfte Ergebnisse, macht es zu einem starken Partner für datengetriebene Entscheidungs- und Erkenntnisprozesse.
Angesichts der rasant wachsenden Datenmengen und der steigenden Komplexität von Fragen ist die Automatisierung und intelligente Steuerung von Recherchevorgängen ein logischer und notwendiger Schritt. Datasleuth geht dabei weit über einfache Suchmaschinen hinaus, indem es die gesamte Forschungsreise abbildet – von der Planung über die Datensammlung bis hin zur verlässlichen Synthese. Die nahtlose Integration mit führenden KI-Anbietern via Vercel AI SDK gestattet es, die Leistung kommerzieller LLMs wie OpenAI oder Anthropic flexibel zu nutzen und letzten Endes maßgeschneiderte Lösungen für individuelle Forschungsanforderungen zu schaffen. So bleibt die Technologie zukunftssicher, da sie sich mit den Fortschritten im Bereich der KI und maschinellen Sprachverarbeitung kontinuierlich weiterentwickelt. Für alle, die sich mit großer Themenvielfalt beschäftigen und strukturiert wertvolle Informationen extrahieren möchten, ist Datasleuth eine zukunftsweisende Technologie.