Win32-Ressourcen sind ein wesentlicher Bestandteil der Windows-Programmierung. Sie ermöglichen es, verschiedene Daten wie Symbole, Menüs, Dialoge oder andere benutzerdefinierte Elemente in ausführbaren Dateien zu speichern. Doch was passiert, wenn der Name einer Ressource akzentuierte Zeichen enthält? Warum hat Windows, insbesondere die Funktion FindResource im Win32-API, Schwierigkeiten, solche Ressourcen zu finden? Um diese Frage zu beantworten, lohnt sich ein Blick auf die Funktionsweise von Windows und den zugrunde liegenden Spezifikationen. Im Kern basieren Win32-Ressourcen auf einem Portable Executable (PE)-Format, das Dateien und deren Struktur definiert. Innerhalb dieses Formats sind Ressourcen durch Namen oder Identifikatoren gekennzeichnet.
Gemäß der PE-Spezifikation sollen die Ressourcen „in aufsteigender Reihenfolge“ sortiert sein – allerdings bleiben Details zur Sortierung unklar. Es ist festgehalten, dass die Sortierung „case-sensitive“ erfolgt, also Groß- und Kleinbuchstaben unterscheiden werden. Was aber bedeutet das im Kontext von akzentuierten Zeichen? Windows benutzt für die Suche nach Ressourcen die Funktion FindResource, die festlegt, wie Ressourcenname verglichen werden. Die Dokumentation verspricht eine Groß-/Kleinschreibungs-unabhängige Suche, weshalb man annehmen könnte, dass Namen wie „MyIcon“ oder „myicon“ gleich behandelt werden. Doch tatsächlich gelingt das Auffinden nur dann zuverlässig, wenn keine akzentuierten oder Sonderzeichen auftauchen.
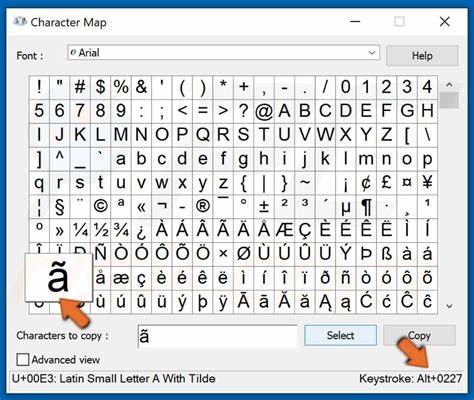
Bei Namen mit Zeichen wie „Ö“ oder „ö“ werden diese Tür und Tor für Fehler geöffnet. Eine der Hauptursachen für die Verwirrung liegt in der Art und Weise, wie Windows Ressourcennamen intern in Großbuchstaben umwandelt. Die Resource Compiler (RC) konvertieren Ressourcennamen vor der Speicherung in Großbuchstaben mithilfe der Funktion _wcsupr, die auf der Standard-C-Locale basiert. Diese einfache Transformation konvertiert nur die lateinischen Standardbuchstaben a–z in A–Z und ignoriert diakritische Zeichen. Die Umwandlung beim Suchen durch FindResource hingegen orientiert sich an der Systemsprache und verwendet den systemweiten Großbuchstabensatz.
In einer deutschen Windows-Umgebung werden „ö“ und „Ö“ als Klein- und Großbuchstabenpaar behandelt und daher beim Suchen korrekt umgewandelt – in anderen Regionen kann dies jedoch anders aussehen. Die Folge ist, dass ein Name, der mit dem Resource Compiler bearbeitet wurde, nicht so einfach mit dem Suchstring in einer anderen Sprachumgebung übereinstimmt. Gerade bei Ressourcen, die Namen mit Akzenten oder Sonderzeichen enthalten, entstehen so Inkonsistenzen und letztlich das Problem, dass die Ressource nicht gefunden wird. Hinzu kommt, dass die Ressourcennamen zwar theoretisch beliebige Unicode-Zeichen enthalten können, die FindResource-Funktion in der Praxis jedoch bei der Behandlung von solchen Zeichen limitiert bleibt. Das Parsen und Vergleichen erfolgt byteweise anhand der numerischen Werte der einzelnen Zeichen, was bei mehrsprachigen Zeichensätzen mit Akzenten besondere Schwierigkeiten hervorruft.
Unterschiedliche Sortierlogiken und Collation-Regeln je nach Sprache sorgen für noch mehr Komplexität, was die scheinbar einfache Aufgabe der Groß-/Kleinschreibungs-unabhängigen Suche erheblich erschwert. Diese technischen Eigenheiten führen dazu, dass Entwickler bei Win32-Ressourcen mit Namen, die akzentuierte Buchstaben enthalten, oft vor Problemen stehen: Die Ressource wird nicht gefunden, selbst wenn der korrekte Name verwendet wird. Das liegt nicht an Flüchtigkeitsfehlern, sondern am inhärenten Verhalten von FindResource und Resource Compiler. Ein weiterer Faktor ist, dass viele Programmierer aus historischen Gründen hauptsächlich ASCII-Zeichen für Ressourcennamen verwenden, um genau diesen Problemen aus dem Weg zu gehen. ASCII-Zeichen sind im Vergleich zu Unicode-Zeichen einheitlich organisiert, die Großschreibung funktioniert erwartungsgemäß, und die Suche liefert konsistente Ergebnisse.
Da die Mehrheit aller Ressourcen unproblematisch mit ASCII-Namen funktioniert, ist auch die Dokumentation oft ungenau oder weist nicht explizit auf diese Beschränkungen hin. Diskussionen innerhalb der Entwickler-Community zeigen auch den Wunsch nach einer verbesserten Unterstützung für akzentuierte Zeichen. Vorschläge reichen von der Einführung eines neuen Verhaltens des Resource Compilers, der akzentuierte Zeichen unberührt lässt und zusätzlich eine Großbuchstaben-Version speichert, bis hin zu einer FindResource-Funktion, die zuerst eine exakte Übereinstimmung sucht und bei Fehlschlag auf eine fallbasierte Suche zurückgreift. Dennoch sind solche Änderungen nicht einfach umzusetzen, weil sie die Abwärtskompatibilität zu bestehenden Programmen und Ressourcen gefährden könnten. Ein grundsätzlicher Lösungsansatz für Entwickler lautet daher: Verzichten Sie auf die Verwendung von ressourceninternen Namen mit Akzentzeichen.
Nutzen Sie stattdessen einfache, ASCII-kompatible Namen oder nummerische Ressourcen-IDs. So umgehen Sie die Komplexität bei der Groß-/Kleinschreibung und der Lokalisierung, und Ihre Ressourcen werden unabhängig von Sprache und Systemkonfiguration zuverlässig gefunden. Zusammenfassend lässt sich sagen, dass Windows beim Umgang mit Win32-Ressourcen mit akzentuierten Zeichen in den Namen auf interne Limitierungen stößt, die tief in der Verarbeitung von Strings und dem Zusammenspiel von Compiler und API-Funktion verwurzelt sind. Die Diskrepanz zwischen der Art und Weise, wie Ressourcennamen konvertiert und durchsucht werden, sorgt für inkonsistente Ergebnisse. Gerade weil der PE-Spezifikation keine klaren Regeln für die Sortierung und Groß-/Kleinschreibung von Unicode-Zeichen vorliegen, bleibt das Verhalten oftmals unvorhersehbar.