Die Stream-Verarbeitung hat sich in den letzten Jahren als eine der wichtigsten Technologien im Bereich der Datenverarbeitung etabliert. Während Batch-Verarbeitung lange Zeit dominierte und vor allem für die Verarbeitung großer statischer Datenmengen genutzt wurde, nimmt die Echtzeitverarbeitung mittels Streaming immer mehr an Bedeutung zu. Unternehmen aller Größenordnungen benötigen heute Lösungen, die kontinuierliche Datenströme in Echtzeit analysieren und verarbeiten können, um sofortige Entscheidungen zu ermöglichen und Wettbewerbsvorteile zu erzielen. Doch trotz ihres enormen Potenzials ist Stream-Verarbeitung eine technisch komplexe Disziplin, die weit über die Herausforderungen traditioneller Batch-Prozesse hinausgeht. Die Entstehung komplexer Systeme, die Entwicklung von Algorithmen zur Gewährleistung von Konsistenz und Performance sowie die Integration in vielfältige Datenökosysteme machen den Aufbau und Betrieb von Stream-Prozessoren zu einer anspruchsvollen Aufgabe.
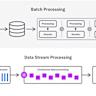
Der grundlegende Unterschied zwischen Batch- und Stream-Verarbeitung liegt in der Natur der Daten und der Art und Weise, wie diese verarbeitet werden. Während Batch-Prozesse sich auf statische Datenmengen beschränken, welche einmalig oder periodisch verarbeitet werden, handelt es sich bei der Stream-Verarbeitung um einen kontinuierlichen Datenfluss, der fortlaufend analysiert und transformiert wird. Dieses permanente Eintreffen neuer Daten stellt besondere Anforderungen an die Systeme. Beispielsweise müssen Streaming-Joins nicht nur auf gegenwärtige Daten angewandt werden, sondern auch auf zukünftige Anfragen reagieren und entsprechende Datenstrukturen dynamisch anpassen. Das Resultat ist ein höherer Komplexitätsgrad, der tiefgreifende technische Expertise und Ressourcen erfordert.
Ein weiteres zentrales Problem der Stream-Verarbeitung ist die enge Verzahnung mit anderen Datenprodukten. Im Gegensatz zu Datenbanken oder Batch-Systemen fungiert ein Stream-Prozessor selten als alleinstehende Endlösung. Er ist vielmehr Teil eines Ökosystems, in dem Daten kontinuierlich empfangen, transformiert und an nachgelagerte Systeme wie relationale Datenbanken oder Data Warehouses weitergeleitet werden. Ohne entsprechende Datenendpunkte, die das Ergebnis der Stream-Verarbeitung indexieren oder durchsuchen können, ist ein Stream-Prozessor kaum nutzbar. Die Abhängigkeit von verschiedenen Systemen führt zu einer hohen Fehleranfälligkeit, denn selbst kleinste Probleme in einer Datenquelle oder einem Zielsystem können sich unmittelbar auf die gesamte Datenpipeline auswirken.
Historisch wurde versucht, die Komplexität der Stream-Verarbeitung durch den modularen Aufbau in viele spezialisierte Komponenten zu reduzieren. Bekannte Beispiele sind Middleware wie Apache Kafka für die logbasierte Nachrichtenspeicherung, Zookeeper für die Systemkoordination oder verschiedene Serialisierungsformate wie Avro und Protocol Buffers. Diese Architektur gestattet zwar eine flexiblere und skalierbare Umsetzung von Streaming-Systemen, bringt jedoch eine Vielzahl unterschiedlicher Technologien mit verschiedenen Schnittstellen und Konfigurationserfordernissen mit sich. Für Anwender und Entwickler bedeutet dies einen erheblichen Mehraufwand beim Betrieb, da umfangreiches Wissen über die einzelnen Bestandteile notwendig ist, um die Datenfluss-Pipelines zuverlässig, performant und sicher zu gestalten. Im Kern sind aktuelle Stream-Verarbeitungsplattformen leistungsfähig und robust, ihre Nutzung erfordert jedoch oft tiefgehendes technisches Know-how.
Die Bedienbarkeit bleibt für viele Anwender eine Hürde, wodurch Stream-Verarbeitung trotz ihrer Relevanz noch nicht die ihr gebührende Verbreitung gefunden hat. Der Spagat zwischen der Leistungsfähigkeit auf der einen Seite und Benutzerfreundlichkeit auf der anderen Seite markiert derzeit eine der größten Herausforderungen der Branche. Die Zukunft der Stream-Verarbeitung deutet jedoch auf eine neue Generation von Systemen hin, die genau diese Herausforderung adressieren. Analog zur Entwicklung im Bereich der Datenbanken, bei der komplexe und teure Lösungen wie Oracle durch nutzerfreundliche Open-Source-Alternativen wie PostgreSQL ergänzt wurden, entstehen neue Stream-Prozessoren, die intern komplexe Technologien verwenden, diese aber für Anwender abstrahieren und vereinfachen. Der Fokus dieser Systeme liegt darauf, Komplexität zu einer Option zu machen und nicht zur Anforderung.
Das bedeutet, dass die meisten Anwender sofort nutzbare Systeme erhalten, die ohne umfangreiche Konfiguration funktionieren, während Experten bei Bedarf tiefgreifende Kontrolle und Anpassungsmöglichkeiten erhalten. Diese modernen Stream-Prozessoren basieren auf innovativen Algorithmen, die starke End-to-End-Garantien bieten. Dazu gehören beispielsweise differential dataflow-Modelle oder hochentwickelte Replikationstechniken, die es erlauben, Daten konsistent und synchron über verschiedene Systeme zu verteilen. Eine besondere Rolle spielt dabei die vollständige Unterstützung von Transaktionen in der Stream-Verarbeitung. Während älteren Systemen oft die atomare Abbildung von Datenbanktransaktionen in den Streaming-Schichten fehlt, sodass komplexe Operationen in der Quelle fragmentiert in den Zielspeichern erscheinen, gewährleisten moderne Systeme die atomare Durchführung auch über die gesamte Pipeline hinweg.
Dadurch werden Konsistenzprobleme und fehlinterpretierte Daten verhindert. Ein weiterer Baustein der Zukunft ist die enge Integration aller Systemkomponenten. Statt vieler getrennter Teile arbeiten Transformation, Replikation und Speicherung als koordinierte Einheit zusammen. So können sich Systeme automatisch an neue Anforderungen anpassen, beispielsweise wenn neue Tabellen oder Datenströme hinzukommen. Außerdem werden oft eine Vielzahl nicht-funktionaler Eigenschaften wie Parallelisierung, Fehlerbehandlung und Schemaänderungen vollständig vom System übernommen, ohne dass der Anwender eingreifen muss.
Die Benutzeroberflächen sind dabei so gestaltet, dass sie ein einfaches Management aller Streaming-Prozesse ermöglichen – von der Datenaufnahme, über die Transformation, bis hin zum Abspeichern der Ergebnisse in Datenbanken oder Analysetools. Die Vereinfachung der Bedienung wird die Stream-Verarbeitung für viele Einsatzgebiete zugänglicher machen. Anwendungsbereiche aus der Datenanalyse, dem Monitoring oder der Echtzeitsteuerung werden von dieser Entwicklung profitieren. Die Fähigkeit, komplexe Abfragen oder Vorberechnungen in nahezu Echtzeit auf Inkremementalansichten auszuführen, wird Bausteine wie ETL-Prozesse, datengetriebene Frontends und Analysemodelle grundlegend verbessern. Die zunehmende Automatisierung und Vereinfachung werden zudem die Kosten für Dateninfrastrukturen senken und die Effizienz der Entwickler steigern, indem sie mehr Zeit für die Entwicklung von Geschäftsfunktionen und weniger für technische Infrastruktur aufwenden müssen.
Das Potenzial dieser neuen Generation von Stream-Prozessoren kann mit der revolutionären Entwicklung im Data-Warehouse-Bereich verglichen werden, bei der Anbieter wie Snowflake einen Durchbruch in Skalierbarkeit und Benutzerfreundlichkeit erzielten. Gleiches ist bei Stream-Verarbeitung möglich: Die mächtigen Echtzeitfunktionalitäten, die anfangs technisch schwer zugänglich waren, werden dank optimierter Architekturen und integrierter End-to-End-Lösungen nutzerfreundlich und robust. Das verwandelt die Art und Weise, wie moderne Datenökosysteme aufgebaut sind und wie Unternehmen datengetriebene Entscheidungen treffen. Zusammenfassend lässt sich festhalten, dass die Stream-Verarbeitung an einem Wendepunkt steht. Traditionelle Herausforderungen wie Komplexität, Stabilität und Benutzerfreundlichkeit werden durch innovative Konzepte und technologische Fortschritte überwunden.
Die Zukunft gehört holistischen Streaming-Systemen, die enorme Leistungsfähigkeit mit einfacher Bedienung verbinden. Für Unternehmen resultiert daraus eine neue Dimension der Echtzeitdatenverarbeitung, die nicht nur die bestehende Infrastruktur ergänzt, sondern sie grundlegend transformiert. Die kontinuierliche Weiterentwicklung dieser Technologie wird maßgeblich dazu beitragen, dass Echtzeitdaten allgegenwärtig und für jedermann nutzbar werden – unabhängig von der Größe des Unternehmens oder dem technischen Know-how der Anwender.