Das Logging nimmt in der Softwareentwicklung eine essenzielle Rolle ein, insbesondere für die Fehlersuche, Performance-Überwachung und das Monitoring von Anwendungen. In der Programmiersprache Go hat sich mit der Einführung von slog, dem neuen Logging-Paket in der Standardbibliothek, ein leistungsfähiges Werkzeug etabliert, das Flexibilität und Effizienz miteinander verbindet. Dieses Paket bietet Entwicklern die Möglichkeit, strukturiert zu loggen, was die spätere Auswertung und Analyse vereinfacht. Im Folgenden werden einige clevere Tricks erläutert, die dabei helfen, slog.Logger produktiv und übersichtlich in Go-Projekten einzusetzen und damit den Umgang mit Logs deutlich zu verbessern.
Ein essenzieller Punkt beim Logging mit Go ist die Konsistenz der Attribute. Es ist verlockend, in kleineren Projekten Attribute wie Nutzerkennung, Fehlertexte oder Zeitstempel spontan zu benennen. Bei größeren Teams kann dies jedoch zu Uneinheitlichkeiten führen, die das Auswerten der Logdaten erheblich erschweren. Aus diesem Grund empfiehlt es sich, eine dedizierte Paketstruktur für alle Logging-bezogenen Attribute anzulegen. Dadurch erhält das gesamte Team eine einheitliche Sicht auf verfügbare Attribute, was insbesondere bei der Einrichtung von Dashboards und Log-Queries einen großen Vorteil darstellt.
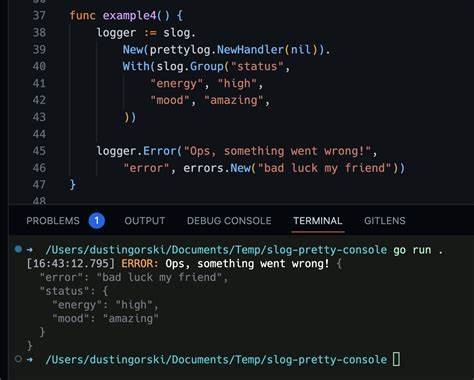
Einheitliche Bezeichnungen wie "user_id" statt verschiedener Varianten sorgen für saubere, durchsuchbare Logs. Zudem wird die Basis geschaffen, um komplexere Log-Attribute und Fehlerstrukturen auf einfache Weise zu gestalten. Ein besonders eleganter Ansatz besteht darin, Fehlerlogeinträge mit zusätzlichen Attributen zu kombinieren. In der Praxis bedeutet das, dass Fehler nicht nur als einfache Textnachricht sondern als strukturierte Logs mit allen relevanten Kontextinformationen ausgegeben werden. Hierfür kann man einen eigenen Fehler-Typ definieren, der neben der eigentlichen Fehlermeldung auch Attribute speichert, wie beispielsweise eine Nutzer-ID oder spezifische Fehlercodes.
Beim Logging wird dann nicht nur die Fehlermeldung geschrieben, sondern eine Gruppe von Attributen, die beispielsweise den Fehlerkontext und weitere Hinweise enthalten. Das hat mehrere Vorteile: Zum einen bleiben alle wichtigen Details in der Meldung vorhanden, zum anderen lassen sich relevante Informationen wie Nutzer-IDs oder fehlerverursachende Kontexte direkt als eigene Felder in Monitoring-Systemen wie Kibana oder Grafana auswerten. Durch diese Kombination entsteht eine klare Trennung zwischen der menschlich lesbaren Fehlerbeschreibung und den maschinenlesbaren Attributen. Das fördert nicht nur eine effizientere Fehlersuche, sondern verbessert auch die Qualität der Logs und erleichtert das Erstellen von aussagekräftigen Alarmierungen und Statistiken. In der Entwicklungsroutine kann so ein Fehler mit Kontext nutzer- oder prozessorientiert an das Log übergeben werden, ohne komplizierte manuelle String-Manipulationen oder aufwendige Wrapper.
Ein weiterer wichtiger Aspekt ist der Umgang mit Logger-Instanzen über verschiedene Teile eines größeren Go-Projekts hinweg. Es ist häufig unangenehm, Logger-Objekte überall über die Funktionsaufrufe hinweg zu reichen, insbesondere wenn in vielen Bereichen geloggt werden soll. Ein cleverer Workaround kann darin bestehen, eine globale Handler-Instanz als zentrale Logging-Schnittstelle anzulegen. Zunächst wird ein Platzhalter-Handler definiert, der alle Logeinträge puffert, solange der eigentliche Handler noch nicht zur Verfügung steht. Sobald beim Programmstart der finale Handler mit konkretem Ziel (beispielsweise eine Datei oder stdout im JSON-Format) bereitgestellt wird, werden sämtliche gepufferten Logs abgearbeitet und die globale Handler-Variable gesetzt.
Die Vorteile dieser Lösung sind vielfältig. Logs entstehen unmittelbar und können an beliebigen Stellen ohne Logger-Passing erzeugt werden, auch bevor der endgültige Handler definiert wird. Funktionen und Libraries, die einen Logger benötigen, können ihre Instanz mit kontextbezogenen Attributen versehen, beispielsweise eine Instrumentenkennung oder Versionsangabe. Dadurch entsteht eine flexible und gleichzeitig übersichtliche Logging-Infrastruktur, die mit minimalem Code-Aufwand sowohl einfache als auch komplexe Anforderungen erfüllt. Mit dieser Methode können Entwickler Libraries oder Services erstellen, die von Beginn an sinnvoll und differenziert loggen, ohne aufwändige Initialisierung an jeder Stelle zu benötigen.
Das erhöht nicht nur die Wartbarkeit des Codes, sondern verbessert auch die Transparenz in der Laufzeitumgebung. Vor allem in modernen Microservices-Architekturen, bei denen Logs oft zentral aggregiert und analysiert werden, schlägt sich eine derartige standardisierte Logging-Strategie durch bessere Diagnosemöglichkeiten und geringeren Aufwand nieder. Trotz der starken Leistungsfähigkeit von slog lohnt es sich, das Paket Logging im Projekt klar und modular zu konzipieren. Durch kurze und prägnante Wrapper-Funktionen für alle wesentlichen Attribute entsteht eine übersichtliche Schnittstelle für das gesamte Team. Außerdem reduziert sich die Fehlerrate bei Tippfehlern oder inkonsistenter Benennung von Logging-Feldern erheblich.
Eine bewährte Praxis ist es, beispielsweise Funktionen wie Error(err error) oder UserID(id int) anzubieten, die jeweils genau definierte Attribute zurückgeben. Dadurch wird das Logging nicht nur standardisiert, sondern durch die Einbettung direkt in die Fehler und Datenmodelle auch intuitiver. Für Entwickler, die gewohnte Logging-Libs wie logrus oder zap kennen, stellt slog eine zeitsparende und zukunftssichere Alternative dar. Die einfache Integration in das Standardpaket senkt die Einstiegshürde erheblich. Durch die vorgestellten Tricks vermittelt das Paket nicht nur Basiskomfort, sondern eröffnet durch User-defined Attributes, gruppierte Fehlerlogs und flexible Handler-Zuweisung viele Möglichkeiten für professionelles Log-Management.
Auch wenn man nicht alle Funktionen sofort benötigt, lohnt sich die Investition in eine strukturierte Logging-Architektur frühzeitig. Spätere Erweiterungen etwa um verteiltes Tracing, kontextsensitive Logs oder automatisches Monitoring lassen sich so problemlos integrieren. Die Denkweise, Logs primär als strukturierte Daten zu betrachten und Attribute konsequent zu verwalten, macht langfristig einen gewaltigen Unterschied in Qualität, Performance und Nutzbarkeit. Zusammenfassend lässt sich sagen, dass Go's ehrliches, einfaches und dennoch mächtiges Logging-Paket mit cleveren Ansätzen wie dedizierten Attributpaketen, kombinierten Fehlerlogs und global gesteuerten Handlern eine hervorragende Basis schafft. Ein sauber organisiertes Logging-Konzept erhöht die Produktivität, minimiert Fehlerquellen und liefert wertvolle Einblicke in das Laufzeitverhalten moderner Anwendungen.
Entwickler und Teams, die diese Methoden konsequent umsetzen, sichern sich damit ein effizientes Werkzeug für den Dauerbetrieb und das Monitoring anspruchsvoller Go-Programme.




![An Overview of LinkedIn’s AI-Powered Accelerate Campaigns [Infographic]](/images/CE04CB32-21ED-4F7E-840B-6492049E562C)