Die rasante Zunahme räumlicher Daten durch Technologien wie Satellitenbilder, Drohnen und mobile Sensoren stellt die Geoinformationssysteme (GIS) vor immer größere Herausforderungen. Die Speicherung, Verwaltung und Analyse dieser umfassenden und komplexen Datenmengen benötigt leistungsfähige Datenbanksysteme, die nicht nur skalierbar sind, sondern auch effiziente räumliche Abfragen unterstützen. In diesem Kontext gewinnen Hive-ähnliche räumliche Datenbanken für GIS-Workloads erheblich an Bedeutung und bieten eine zukunftsfähige Lösung für die Verarbeitung von Geodaten im großen Maßstab. Hive, ursprünglich als Data-Warehouse-System von Facebook entwickelt, basiert auf Hadoop und ermöglicht die Verarbeitung großer Datenmengen mithilfe von SQL-ähnlichen Abfragen auf verteilten Datenspeichersystemen. Über die Jahre wurde Hive kontinuierlich erweitert und angepasst, um den steigenden Anforderungen modernster Anwendungsfälle gerecht zu werden.
Wenn man von Hive-ähnlichen räumlichen Datenbanken spricht, meint man Systeme, die die Vorteile von Hive mit speziellen räumlichen Datenmodellen und Indexierungsmechanismen kombinieren, um geografische Informationen effizient abzufragen. GIS-Anwendungen weisen einzigartige Anforderungen auf, da räumliche Daten eine Vielzahl von Formen annehmen können: Punkte, Linien, Polygonflächen oder komplexe geometrische Strukturen. Die spatialen Funktionen umfassen die Bestimmung von Entfernungen, Überlappungen, Nachbarschaften oder räumlichen Joins zwischen Datensätzen. Traditionelle relationale Datenbanken stoßen bei solchen umfangreichen und heterogenen Datenmengen oft an ihre Grenzen, insbesondere wenn es darum geht, Daten über große geografische Bereiche schnell und in Echtzeit zu analysieren. Hive-ähnliche räumliche Datenbanksysteme setzen daher auf verteilte Rechenarchitekturen, die es erlauben, Daten auf hunderten oder tausenden von Serverknoten zu speichern und parallel zu verarbeiten.
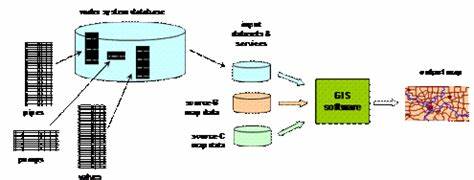
Diese Skalierbarkeit ist essenziell, um massive Mengen geo-lokalisierter Daten aus unterschiedlichen Quellen effizient zu verarbeiten. Gleichzeitig sind diese Systeme oft mit spezialisierten räumlichen Indexierungsverfahren ausgestattet, wie etwa R-Bäumen, Quadtrees oder Geohashing, die dafür sorgen, dass räumliche Abfragen im Datensatz lokalisiert und performant ausgeführt werden können. Darüber hinaus unterstützen moderne Hive-ähnliche Systeme für GIS-Workloads gängige räumliche SQL-Erweiterungen, die eine intuitivere und mächtigere Abfragesprache für Entwickler und Analysten bieten. Funktionen zur Verarbeitung von Geometrien, Spatial Joins, Pufferzonen oder zur Berechnung von Schnittmengen sind damit direkt abfragbar. Diese Integration erleichtert es Unternehmen und Behörden, komplexe räumliche Analysen durchzuführen, ohne aufwändige und fehleranfällige manuelle Auswertungen durchführen zu müssen.
Ein weiterer Vorteil der Hive-ähnlichen Plattformen liegt in ihrer Kompatibilität mit Big-Data-Ökosystemen. Sie lassen sich problemlos mit Tools wie Apache Spark, Presto, oder anderen Hadoop-kompatiblen Technologien kombinieren, wodurch Datenpipelines für GIS-Workloads effizient gestaltet werden können. Durch solche ganzheitlichen Lösungsansätze können umfangreiche Geodaten nicht nur gespeichert, sondern in Echtzeit analysiert und visualisiert werden, was besonders bei Anwendungen wie Verkehrsmanagement, Katastrophenschutz oder Unternehmensstandortanalyse entscheidend ist. Im Bereich der Umweltüberwachung und natürlichen Ressourcen schließen Hive-ähnliche räumliche Datenbanken eine wichtige Lücke. Die Verarbeitung von Satellitendaten zur Erkennung von Veränderungen in der Landnutzung oder zur Analyse von Vegetationsmustern erfordert robuste Speichersysteme kombiniert mit schnellen Abfragen über möglicherweise mehrere Jahre oder Jahrzehnte hinweg.
Hive-ähnliche Architekturen bieten die notwendige Datenverarbeitungskapazität, um solche komplexen Zeitreihen- und räumlichen Analysen effizient durchzuführen. Nicht zuletzt ist auch die Zugänglichkeit dieser Technologien hervorzuheben. Dank Open-Source-Projekten haben viele Unternehmen und Institutionen Zugang zu Hive-ähnlichen Datenbanksystemen, die flexibel angepasst und in bestehende Infrastrukturen integriert werden können. Diese Offenheit fördert Innovationen in der GIS-Community und ermöglicht es, individuelle Anforderungen von Behörden, Industrie und Forschung passgenau zu adressieren. Die Zukunft von Hive-ähnlichen räumlichen Datenbanken im Kontext von GIS sieht vielversprechend aus.