In der heutigen datengetriebenen Welt sind effiziente und flexible Datenpipelines unerlässlich, um wertvolle Erkenntnisse aus großen Datenmengen zu gewinnen. Unternehmen, Entwickler und Data Scientists benötigen Lösungen, die nicht nur leistungsfähig, sondern auch einfach zu implementieren und vielseitig einsetzbar sind. Hier tritt AnkaFlow als eine revolutionäre Plattform in Erscheinung, die sowohl SQL- als auch Python-basierte Datenpipelines ermöglicht und diese sowohl lokal in Python-Umgebungen als auch vollständig im Browser ausführen kann. Diese einzigartige Kombination erhöht die Flexibilität und Nutzerfreundlichkeit erheblich und macht AnkaFlow zu einem wichtigen Werkzeug im Bereich ETL (Extract, Transform, Load) und Datenverarbeitung. AnkaFlow ist ein auf YAML basierendes Pipeline-Framework, das sich durch seine klare Struktur und Anpassungsfähigkeit auszeichnet.
Es ermöglicht die Definition von Pipelines in leicht verständlichen YAML-Dateien, die anschließend auf Basis von DuckDB SQL-Abfragen ausgeführt werden können. Dabei bietet die Plattform die Möglichkeit, Python-Code mit einzubinden, um komplexere Transformationen oder spezielle Operationen durchzuführen. Das Besondere an AnkaFlow ist die Kompatibilität mit modernen Browser-Technologien mithilfe von Pyodide, einer WebAssembly-Version von Python. Dadurch können Datenpipelines komplett im Browser, etwa in JupyterLite oder über GitHub Pages, ohne eine lokale Python-Installation laufen. Diese Eigenschaft eröffnet neue Möglichkeiten für kollaborative Entwicklungsumgebungen, das Teilen von Datenentwicklungen sowie den Einsatz in Unternehmensumgebungen, in denen lokale Installation oft eine Hürde darstellt.
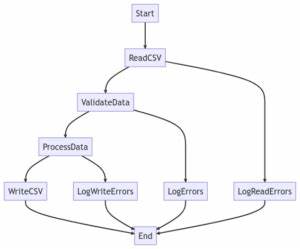
Zu den herausragenden Merkmalen von AnkaFlow gehört die breite Unterstützung verschiedener Datenquellen und Speicherformate. So können unter anderem Parquet-Dateien, REST-APIs, Google BigQuery und ClickHouse (für Serveranwendungen) als Quellen und Senken verwendet werden. Diese Vielfalt an unterstützten Ressourcen macht AnkaFlow sehr flexibel und kompatibel mit vielen modernen Data-Stack-Architekturen. Die Strukturierung von Datenpipelines in AnkaFlow erfolgt über sogenannte Stages, die als Kernkomponente dienen. Jede Stage wird in der YAML-Datei festgelegt und kann eine von drei Arten sein: Tap, Transform oder Sink.
Taps sind Datenextraktionsphasen, in denen Daten aus verschiedenen Quellen zusammengeführt werden. Transforms enthalten SQL- oder Python-Skripte zur Datenverarbeitung und -anreicherung. Sinks sind die Endpunkte, in die verarbeitete Daten geschrieben werden, sei es zurück in eine Datei, Datenbank oder einen anderen externen Dienst. Praktisch bedeutet das für Anwender, dass sie komplexe Abläufe mit wenigen Zeilen YAML-Code definieren und so eine transparente, nachvollziehbare Pipeline-Struktur erhalten. Entwickelt wurde AnkaFlow vor allem mit Blick auf Data Engineers, ML-Teams und SaaS-Entwickler, die flexible und skalierbare ETL-Prozesse benötigen, ohne sich auf schwergewichtige Server-Infrastrukturen oder komplexe Konfigurationsaufwände verlassen zu müssen.
Das zeigt sich auch in der Installation und Nutzung. Die Software kann einfach über Python-Pip-Pakete installiert werden, etwa mit dem Befehl „pip install ankaflow[server]“ für die Server-Variante oder „pip install -e .[dev,server]“ für Entwicklungszwecke. Das Handling im Alltag ist dank der Python-API qualitativ hochwertig gestaltet. Nutzer starten ihre Pipelines mit wenigen Codezeilen, laden die YAML-Konfiguration ein, definieren die Verbindungsparameter für Datenquellen und -senken und führen den gesamten Ablauf aus.
Neben der technischen Innovation zeichnet sich AnkaFlow durch eine benutzerfreundliche Dokumentation und eine lebendige Community aus. Die offizielle Webseite und das GitHub-Repository bieten umfassende Guides, ein Live-Demo und Beispielkonfigurationen, die den Einstieg erleichtern. Darüber hinaus profitieren Nutzer von der aktiven Weiterentwicklung und der Zahl der verfügbaren Features, darunter neu hinzugekommene LLM-Tap-Quellen, die besonders für KI- und Machine-Learning-Szenarien interessant sind. Ein weiterer Vorteil von AnkaFlow ist die Unterstützung von DuckDB, einer in-Process-Analytik-Datenbank, welche hohe Performance für SQL-Abfragen ohne serverseitigen Overhead liefert. DuckDB ist aufgrund seiner Embed-Fähigkeit und seines Speicherformats eine ideale Wahl für Anwendungsfälle, die sowohl lokal als auch in Browserumgebungen ausgeführt werden müssen.
Die Kombination von DuckDB mit dem YAML-gesteuerten Pipeline-Framework von AnkaFlow ermöglicht damit eine Aufgabe schnell erledigte, leicht übertragbare und plattformunabhängige Datenbearbeitung. Die Möglichkeit, ETL-Prozesse ohne zusätzliche Infrastruktur direkt im Browser zu entwickeln und auszuführen, senkt die Einstiegshürden für neue Projektteilnehmer und erleichtert das Prototyping mit echten Daten. Gerade in Zeiten, in denen Remote-Arbeit und agile Datenentwicklung immer wichtiger werden, präsentiert sich AnkaFlow als zukunftsweisendes Toolset, das Arbeitsabläufe optimiert und Entwickler produktiver macht. Unternehmen, die auf schnelle Iterationen, flexible Testszenarien und minimalen Installationsaufwand setzen, finden in AnkaFlow einen passenden Partner. Die klare Trennung und Strukturierung durch Stages und die Unterstützung zahlreicher Datenformate fördert zudem die Wartbarkeit und Erweiterbarkeit von Pipelines, was gerade in langfristigen Projekten einen großen Mehrwert darstellt.
Wer mit größeren Datenmengen arbeitet und dabei auf Effizienz und Wiederverwendbarkeit der Datenpipelines Wert legt, kann von AnkaFlow stark profitieren. Die Integration von Python ermöglicht darüber hinaus die Verarbeitung und Analyse auch über die klassischen SQL-Fähigkeiten hinaus, etwa durch Verwendung von Bibliotheken für maschinelles Lernen, Datenvisualisierung oder komplexe Berechnungen. Somit können Data Scientists und Entwickler ihre gesamte Datenpipeline in einer Umgebung konsolidieren, ohne zwischen verschiedenen Tools wechseln zu müssen. Zusammenfassend lässt sich sagen, dass AnkaFlow durch seine Kombination aus Einfachheit, Leistungsfähigkeit und Plattformunabhängigkeit einen entscheidenden Schritt hin zu moderner Datenpipeline-Entwicklung darstellt. Durch die Fähigkeit, Pipelines sowohl serverseitig als auch nativ im Browser auszuführen, eröffnet es neue Anwendungsbereiche, reduziert Komplexität und fördert die Zusammenarbeit verschiedener Teams.
Die breite Unterstützung von Datenquellen und das flexible Design machen es gleichermaßen für kleine Projekte, agile Prototypen und große Unternehmenslösungen attraktiv. Anwender, die sich mit der Automatisierung von ETL-Prozessen, schnellen Datenanalysen und agiler Entwicklung befassen, sollten AnkaFlow daher sorgfältig in Betracht ziehen. Die Open-Source-Verfügbarkeit sowie aktive Weiterentwicklung sichern zudem die Langfristigkeit und Innovationskraft des Tools. Gerade für diejenigen, die nach einer modernen Lösung suchen, um SQL- und Python-Datenpipelines effizient und unkompliziert zu bauen, bietet AnkaFlow eine erstklassige Option, die neue Maßstäbe setzt und die Arbeit mit Daten erheblich erleichtert.








