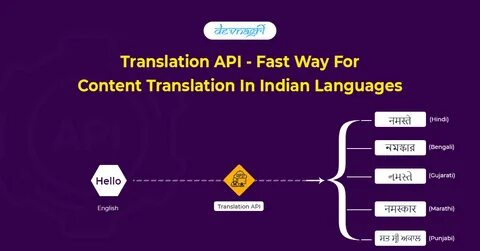
Die digitale Welt wächst unaufhörlich und mit ihr steigt die Nachfrage nach vielseitiger, präziser und vor allem mehrsprachiger Kommunikation. Indien, mit seiner enormen sprachlichen Diversität, stellt eine besondere Herausforderung dar. Über 22 offiziell anerkannte Sprachen und hunderte Dialekte prägen das Land, doch bisher blieben viele dieser Sprachen im digitalen Raum unzureichend vertreten. Hier setzt Sarvam-Translate an, ein innovatives, offenes KI-Übersetzungsmodell, das die Übersetzung von Inhalten über 22 indische Sprachen hinweg revolutioniert. Durch seine Vielseitigkeit, Genauigkeit und Offenheit schafft Sarvam-Translate neue Möglichkeiten für die Sprachzugänglichkeit und digitale Inklusion in Indien und darüber hinaus.
Im Kern handelt es sich bei Sarvam-Translate um ein fein abgestimmtes Modell, das auf Gemma3-4B-IT basiert und speziell für die Herausforderungen der indischen Sprachlandschaft optimiert wurde. Dieses System unterstützt sowohl die Übersetzung einzelner Sätze als auch ganzer Absätze und strukturierten Text in komplexen Formaten, darunter wissenschaftliche Dokumente, LaTeX-Dateien, HTML-Webinhalte, chemische Formeln sowie Programmiercode. Die Fähigkeit, die Struktur und Syntax solcher Dokumente beizubehalten und gleichzeitig eine hochwertige Übersetzung zu gewährleisten, hebt Sarvam-Translate deutlich von anderen großen Sprachmodellen ab. Ein besonderes Augenmerk liegt auf der Unterstützung von strukturiertem Text. Häufig gehen bei Übersetzungen wichtige Formatierungen verloren, insbesondere bei wissenschaftlichen Inhalten wie mathematischen Formeln oder chemischen Gleichungen.
Sarvam-Translate stellt sicher, dass beispielsweise LaTeX-Codierungen bei der Übersetzung erhalten bleiben, ohne Syntaxfehler zu verursachen. Auch beim Übersetzen von HTML-Seiten bewahrt das Modell sämtliche Tags und Strukturen, übersetzt zielgerichtet nur den sichtbaren Text und hält dabei Formatierungen wie Fett- oder Kursivschrift präzise bei. Darüber hinaus glänzt Sarvam-Translate durch seine Sensibilität gegenüber kulturellen Nuancen. Indische Sprachen sind geprägt von Idiomen, Sprichwörtern und kulturellen Redewendungen, die bei wörtlicher Übersetzung oftmals ihren Sinn verlieren. Das Modell kann jedoch idiomatische Ausdrücke adaptieren und naturalistische sowie kontextgetreue Übersetzungen liefern, so dass etwa englische Phrase „behind the eight ball“ sinngemäß in Telugu oder anderen Sprachen korrekt wiedergegeben wird.
Dies macht Texte nicht nur verständlicher, sondern bewahrt auch den ursprünglichen Ton und die kulturelle Relevanz. Sarvam-Translate zeigt sich darüber hinaus robust bei der Übersetzung moderner Kommunikationsformen wie Social-Media-Posts, die häufig Emojis, Slang und unkonventionelle Sprachelemente enthalten. Selbst hier gelingt es dem Modell, den Kontext wertschätzend zu übertragen und zugleich Stil und Stimmung zu erhalten, was zur besseren Digitalpartizipation indischer Sprecher beiträgt. Neben der sprachlichen Vielfalt berücksichtigt das Modell auch den Umgang mit eingebetteten Fremdsprachen. Dokumente, die Textpassagen in traditionellen Sprachen wie Chinesisch oder Englisch enthalten, werden so verarbeitet, dass diese Segmente nicht unvermittelt übersetzt, sondern exakt erhalten bleiben.
Dies stärkt die Genauigkeit bei rechtlichen, historischen oder wissenschaftlichen Texten, deren Terminologie regional oder international festgelegt ist. Ein weiteres Highlight von Sarvam-Translate ist seine Leistung im juristischen Bereich. Der Übersetzungsprozess erfährt hier eine besonders hohe Genauigkeit in Fachterminologie und Satzstruktur, was insbesondere bei umfangreichen Gesetzes- oder Gerichtsdokumenten von entscheidender Bedeutung ist. Die Modellübersetzung bleibt hierbei fest im Rahmen der rechtlichen Ausdrucksweise und bewahrt die intendierte Bedeutung auch in komplexen Satzkonstruktionen. Technisch basiert das Modell auf einer zweistufigen Feinabstimmung mit der LoRA-Technik, die das Training effizient und performativ gestaltet.
Durch Verwendung großer diverser Datensätze, sowohl aus bereits existierenden offenen Übersetzungsdaten als auch neu kuratierten, konnte die Sprachabdeckung sowohl für gut dokumentierte als auch weniger verbreitete Sprachen verbessert werden. Zudem kommt Post-Training-Quantisierung zum Einsatz, die eine effiziente Nutzung von Hardware sicherstellt und schnelle Übersetzungszeiten ermöglicht. Trotz dieser Fortschritte weist Sarvam-Translate noch einige Herausforderungen auf. Für Sprachen mit geringerer Datenbasis wie Bodo, Dogri oder Santali variiert die Übersetzungsqualität stärker, was auf begrenzte Ressourcen und komplexe Sprachmerkmale zurückzuführen ist. Auch sehr umfangreiche LaTeX- oder HTML-Dokumente können zu Strukturschwächen führen, weshalb das Aufteilen in kleinere Segmente empfohlen wird.
Gelegentliche transliterierte oder gemischte Segmente zeigen die Notwendigkeit weiterer Optimierung in Niedrigressourcen-Kontexten. Sarvam-Translate steht dank seiner offenen Gewichtsveröffentlichung auf der Plattform Hugging Face allen Entwicklern und Forschern zur Verfügung. Diese Offenheit fördert die Weiterentwicklung im Bereich der indischen Sprachmodelle, ermöglicht individuelle Anpassungen und unterstützt die Schaffung eines souveränen KI-Ökosystems, das speziell auf die Bedürfnisse Indiens zugeschnitten ist. Das Modell ist Teil einer größeren Vision, indische Sprachen im digitalen Raum gleichwertig zu etablieren und deren Präsenz in Bildung, Verwaltung, Medien und alltäglicher Kommunikation zu stärken. Die Anwendungen reichen von Übersetzung von Webinhalten und Bildungstexten über automatische Untertitel in mehreren Sprachen bis hin zum Einsatz in Regierungsdiensten, die Bürger in ihrer Muttersprache besser erreichen wollen.
Sarvam-Translate setzt Maßstäbe für qualitativ hochwertige Übersetzung durch ein tiefes Verständnis sprachlicher Eigenheiten, struktureller Komplexität und kultureller Feinheiten. Mit einem Fokus auf Inklusion trägt es zur Demokratisierung digitaler Informationen bei und öffnet Türen für mehrsprachige Teilhabe und breit zugängliche Inhalte. Insgesamt markiert Sarvam-Translate einen wichtigen Meilenstein in der KI-gestützten Übersetzung für das indische Spracharchipel. Es verbindet neueste Technologien, datengestützte Methodik und kulturelle Kompetenz, um eine bislang unerreichte Qualität und Vielfalt der Übersetzungen zu erzielen. Für Entwickler, Unternehmen, Bildungseinrichtungen und Nutzer gleichermaßen bietet es eine leistungsstarke und flexible Lösung, die den Weg für die nächste Generation indischer Sprach-KI ebnet und langfristig die digitale Kluft verringert.
Die Zukunft der Sprachübersetzung in Indien ist damit ein Stück näher gerückt – dank einer KI, die nicht nur übersetzt, sondern verstanden hat, was Sprache für eine Kultur und eine Gesellschaft bedeutet.


![Replication is Recursion; or, Lambda: the Biological Imperative (2015) [pdf]](/images/FE4FE205-FBA0-40F8-9860-E4B50F8D8AF7)



