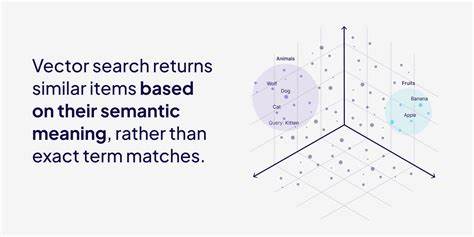
Vector Datenbanken sind mittlerweile zu einem unverzichtbaren Werkzeug in der Welt der künstlichen Intelligenz und des maschinellen Lernens geworden. Mit der explosionsartigen Zunahme unstrukturierter Daten sind herkömmliche relationale Datenbanken oft nicht mehr in der Lage, semantische Beziehungen zwischen Datenpunkten effektiv abzubilden. Hier kommen Vector Datenbanken ins Spiel, die speziell dafür entwickelt wurden, um Ähnlichkeiten und Kontext zwischen Datenpunkten in hochdimensionalen Vektorräumen zu erkennen und somit eine neuartige Art der Suche zu ermöglichen. Unter einer Vector Datenbank versteht man eine Datenbank, die Daten in Form von Vektoren speichert – numerische Repräsentationen, die qualitative Informationen als Zahlenarrays abbilden. Diese Vektoren entstehen durch sogenannte Embeddings, welche unstrukturierte Daten, wie Texte, Bilder oder Audioinhalte, in standardisierte numerische Vektorformen umwandeln.
Diese Transformation ermöglicht es, semantische Beziehungen zwischen den Daten zu erfassen, sodass ähnliche Konzepte in der Datenbank nahe beieinanderliegen. Ein klassisches Beispiel ist die Nähe zwischen Wörtern wie "König" und "Königin" oder "Mann" und "Frau", die in einem embeddingbasierten Vektorraum logisch zueinander positioniert werden. Die Funktionsweise einer Vector Datenbank beruht auf der effizienten Suche nach Vektoren, die einem gegebenen Suchvektor am ähnlichsten sind. Hierbei werden verschiedene Suchalgorithmen und Indexierungsmechanismen eingesetzt, um die Komplexität der Suche in hochdimensionalen Räumen zu reduzieren und dennoch möglichst genaue Treffer zu liefern. Der wohl bekannteste Algorithmus ist k-Nearest Neighbors (k-NN), der die Nähe anderer Vektoren zum Suchvektor durch Messen von Distanzen, etwa über die kosinusähnlichkeit oder die euklidische Distanz, bestimmt.
In der Praxis unterscheidet man zwischen exakten und approximativen Suchmethoden. Eine exakte Suche durchläuft sämtliche Vektoren, vergleicht sie einzeln mit dem Suchvektor und liefert die tatsächlich nächsten Nachbarn. Dieser Ansatz ist zwar immer präzise, aber bei großen Datenmengen sehr langsam und ressourcenintensiv. Approximative Methoden wie Graph-basierte Ansätze, Baumstrukturen oder Hash-basierte Verfahren reduzieren den Suchaufwand erheblich, bringen aber eine gewisse Unschärfe in der Treffergenauigkeit mit sich. Graph-basierte Methoden, wie der Hierarchische Navigierbare Kleine Weltgraph (HNSW), erweisen sich als besonders performant bei der Suche in großen Vektor-Datenbanken.
Dabei wird ein Index mit mehreren Ebenen aufgebaut, wobei jede Ebene eine gewisse Menge der Datenpunkte enthält, die miteinander verbunden sind. Die Suche startet in der obersten Schicht mit einer gröberen Durchmusterung und arbeitet sich schrittweise zu detaillierteren Ebenen vor. Diese Struktur erlaubt eine schnelle Annäherung an den gesuchten Vektor ohne den gesamten Datenbestand durchsuchen zu müssen. Alternativ kommen Baum-basierte Lösungen zum Einsatz, darunter der K-Dimensional Tree (KD-Tree), Ball Tree oder Spotify's Annoy. KD-Trees teilen den Raum entlang gewählter Dimensionen in rechteckige Bereiche auf, wodurch insbesondere bei niedrigdimensionalen Daten eine schnelle Suche möglich ist.
Allerdings verschlechtert sich die Leistung bei Daten mit vielen Dimensionen erheblich, da die Unterschiede zwischen Vektoren in hochdimensionalen Räumen weniger aussagekräftig werden – ein Phänomen, das auch als Fluch der Dimensionalität bekannt ist. Ball Trees gruppieren Daten in sphärische Cluster, sogenannte Bälle, die jeweils einen Mittelpunkt und einen Radius besitzen. Beim Suchen kann dadurch schnell entschieden werden, ob ein Cluster durchsucht werden muss oder übersprungen werden kann, was den Umfang der tatsächlich zu vergleichenden Punkte reduziert. Diese Methode funktioniert besser als KD-Trees bei etwas höherdimensionalen Daten, leidet jedoch ebenfalls bei sehr hohen Dimensionen an Performanceproblemen. Annoy, kurz für Approximate Nearest Neighbors Oh Yeah, ist ein besonderer Vertreter der Baum-basierten Verfahren, der durch die Verwendung vieler flacher Bäume mit zufälligen Splits arbeitet.
Dies erhöht die Suchgeschwindigkeit und Skalierbarkeit, bringt aber im Gegenzug eine Approximation mit sich. Durch das Aggregieren der Ergebnisse mehrerer Bäume werden dennoch gute Trefferquoten erzielt, weshalb Annoy gerade bei großen Datensätzen populär ist. Neben den genannten Baum- und Graph-basierten Algorithmen wird auch Locality Sensitive Hashing (LSH) häufig eingesetzt. LSH funktioniert durch das Zerlegen des Vektorraumes in viele Partitionen mittels spezieller Hashfunktionen, sodass ähnliche Vektoren mit hoher Wahrscheinlichkeit im gleichen Bucket landen. Dies ermöglicht besonders schnelle, wenn auch approximative Suchen, die in hochdimensionalen Räumen performanter sind als naheliegende Exhaustive Search Strategien, aber mit dem Nachteil eines höheren Speicherverbrauchs und möglicher Fehlerraten.
Ein zentraler Aspekt bei der Arbeit mit Vektor-Datenbanken ist das Reduzieren des Suchraums, um das Durchsuchen umfangreicher Datenmengen zu beschleunigen. Clustering ist hier ein bewährtes Mittel, bei dem Vektoren in Gruppen zusammengefasst werden, die semantisch nahe beieinanderliegen. Die Suche beginnt dann mit der Identifikation des oder der nächstgelegenen Cluster, bevor die Distanzberechnung auf die darin enthaltenen Vektoren beschränkt wird. Allerdings kann Clustering bei schlecht gewählten oder hochdimensionalen Embeddings versagen, da die Vektorqualität die Gruppierbarkeit maßgeblich bestimmt. In solchen Fällen helfen Techniken wie Dimensionsreduktion oder Optimierung der Embedding-Modelle, um bessere Clusterstrukturen zu erzielen.
Die Speicherung und Verwaltung von großen Vektor-Datenbanken bringt neben der algorithmischen Herausforderung auch Herausforderungen im Bereich Speicherbedarf und Hardware-Ressourcen mit sich. Beispielsweise kann alleine die Speicherung einer Million Embeddings in Standardformat schnell einige Gigabyte an RAM oder Festplattenspeicher benötigen. Ein typisches Embedding-Modell wie "all-MiniLM-L6-v2" erzeugt Vektoren mit einer Dimension von 384, die in 32-Bit Fließkommazahlen gespeichert werden, was pro Embedding beträchtlichen Speicherplatz beansprucht. Um die Effizienz von Speicherung und Suche zu erhöhen, kommen Kompressionstechniken wie Produktquantisierung (Product Quantization, PQ) zum Einsatz. PQ teilt lange hochdimensionale Vektoren in kleinere Subvektoren auf, für die jeweils Clusterzentren ermittelt werden.
Diese Zentren können durch kurze Indizes repräsentiert werden, wodurch die Vektoren stark komprimiert werden, ohne die wichtigsten semantischen Eigenschaften völlig zu verlieren. Diese Komprimierung kann den Speicherbedarf massiv reduzieren und gleichzeitig schnelle Ähnlichkeitssuchen ermöglichen, allerdings mit einem gewissen Qualitätsverlust bei den Suchergebnissen. Die Wahl des richtigen Indexierungs- und Suchalgorithmus ist stark von den Anforderungen und der Natur der jeweiligen Anwendung abhängig. Bei kleinen Datensätzen mit hohem Anspruch an treffsichere Ergebnisse ist eine exakte exhaustive Suche bei K-NN oft ausreichend, auch wenn sie langsamer ist. Für große, schnell wachsende Datensätze mit hohen Dimensionen sind approximative Ansätze wie HNSW oder Annoy meistens die bessere Wahl, weil sie den Kompromiss zwischen Geschwindigkeit und Präzision sinnvoll ausbalancieren.
Aktuelle Lösungen auf dem Markt umfassen sowohl spezialisierte Vektor-Datenbanken als auch die Erweiterung bestehender allgemeiner Datenbankdienste um Vektor-Suchfähigkeiten. Spezialisierte Systeme wie Pinecone, Milvus, Qdrant oder Weaviate bieten umfassende Optimierung und Skalierbarkeit speziell für Vektordaten an. Gleichzeitig integrieren bekannte Datenbanken wie PostgreSQL mit Erweiterungen wie pgvector oder Redis Stack mittlerweile native Vektor-Suchfunktionen. Darüber hinaus existieren leistungsfähige Open-Source-Bibliotheken wie Faiss von Facebook, ScaNN von Google oder Annoy, die sich auf effiziente Ähnlichkeitssuchen spezialisiert haben und in vielen Projekten verwendet werden. Die Entwicklung von Vector Datenbanken wird weiterhin stark von Fortschritten in KI-modellierten Embeddings, Hardware-Technologien und Suchalgorithmen beeinflusst.