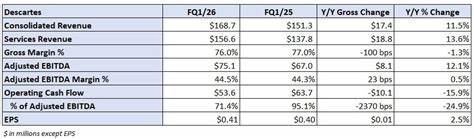
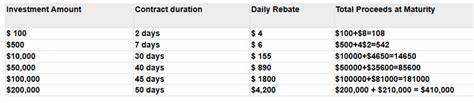
![What do you all think of the latest Apple paper on LLM capabilities? [pdf]](/images/F307C3F5-E4E6-4AF7-92AF-8EDA8CCD1308)
In den letzten Jahren haben große Sprachmodelle, kurz LLMs, einen enormen Fortschritt in der künstlichen Intelligenz markiert. Die jüngste Veröffentlichung von Apple trägt entscheidend dazu bei, unser Verständnis über die Fähigkeiten und Grenzen dieser Modelle zu erweitern. Apples neue Studie geht weit über die bloße Evaluierung der finalen Antwortgenauigkeit hinaus und taucht tief in die Struktur und Qualität der Denkprozesse – der sogenannten Reasoning Traces – dieser Modelle ein. Besonders untersuchen die Forscher, wie Modelle sich bei der Bewältigung von Problemen unterschiedlicher Komplexität verhalten und welche Rolle das argumentative Denken dabei spielt. Die Veröffentlichung baut auf aktuellen Trends auf, in denen spezialisierte Varianten von LLMs, sogenannte Large Reasoning Models (LRMs), Entwicklungsschwerpunkte bilden.
Diese LRMs zeichnen sich durch die Fähigkeit aus, lange Chain-of-Thought (CoT)-Prozesse mit Selbstreflexion zu generieren und gelten als vielversprechende Werkzeuge für anspruchsvollere Denkaufgaben. Doch Apples Forschungsarbeit stellt diese Versprechen der LRMs systematisch auf die Probe. Der Fokus liegt darauf, wie gut sie tatsächlich komplexe Probleme lösen können, und ob ihr „Denken“ konsistent sowie nachvollziehbar ist. Eines der herausragenden Merkmale dieser Studie ist die Nutzung von kontrollierbaren Puzzle-Umgebungen, die eine präzise Manipulation der komplexen Herausforderungen ermöglichen. Damit wird ein standardisiertes Testfeld geschaffen, das die Vergleichbarkeit der Modellantworten auf unterschiedlichen Schwierigkeitsgraden sichert.
Unter diesen Bedingungen offenbaren die Forscher eine überraschende Dynamik: LRMs zeigen eine drastische Genauigkeitsminderung sobald eine bestimmte Komplexitätsschwelle überschritten wird. Interessanterweise beobachten sie auch einen paradoxen Skalierungseffekt, bei dem der Aufwand fürs Denken mit zunehmender Problemkomplexität zunächst steigt, später aber abstumpft, obwohl weiterhin genügend Tokens für eine ausführliche Antwort zur Verfügung stehen. Neben einem Vergleich mit herkömmlichen LLMs unter vergleichbarem Rechenaufwand identifiziert die Arbeit ganz verschiedene Leistungsmodi. Während einfache Aufgaben überraschend besser von Standardmodellen erledigt werden, zeigen LRMs in mittleren Schwierigkeitsstufen eine kleine, aber relevante Überlegenheit. Allerdings kollabieren beide Modelltypen bei hochkomplexen Problemen vollständig, was grundlegende Fragen nach deren wahrhaftigem Denkvermögen aufwirft.
Auch die Fähigkeit von LRMs, exakte Berechnungen durchzuführen und expliziten Algorithmen zu folgen, erweist sich als begrenzt. Ebenso sind ihre Argumentationsketten derzeit noch inkonsistent, wenn sie über verschiedene Puzzle hinweg verglichen werden. Dies legt nahe, dass gegenwärtige LRMs trotz beeindruckender Fortschritte noch keinen echten, robusten Algorithmus-basierten Denkprozess realisieren. Besonders wertvoll sind die detaillierten Analysen der Reasoning Traces, die Muster in den Lösungsansätzen und im Rechenverhalten der Modelle offenlegen. Durch Aufdeckung dieser intermenschlichen Denkspuren haben die Autoren neue Einblicke in die Funktionsweise der KI geliefert, die über reine Ergebnisqualität hinausgehen.
Die Ergebnisse geben deutliche Hinweise darauf, dass sich die Entwicklung noch in der Phase komplexer Herausforderungen befindet, in der man nicht allein an der finalen Genauigkeit der Antworten messen darf, sondern vor allem an der Zuverlässigkeit, Nachvollziehbarkeit und Konsistenz der zugrundeliegenden Denkprozesse. Die Veröffentlichung von Apple birgt damit nicht nur wichtige akademische Erkenntnisse, sondern hat auch praktischen Charakter für die Industrie und Forschung weltweit. Gerade die Feststellung, dass existierende Modelle bei einfachen Aufgaben bereits sehr leistungsfähig sind, aber bei steigender Komplexität schnell an Grenzen stoßen, kann als Leitlinie für künftige Entwicklungsstrategien dienen. Außerdem veranschaulicht sie, dass die Suche nach einem möglichst langen, reflektierenden Chain-of-Thought nicht zwangsläufig bessere Lösungen garantiert. Stattdessen zeigten Untersuchungen, dass das sogenannte „Denken“ eines Modells phasenweise abnimmt, wenn Komplexität zu groß wird.
Dies eröffnet Fragen, ob es nicht neue Architektur- oder Trainingsansätze benötigt, um diese Barrieren zu überwinden. Außerdem vermittelt der Bericht auch eine gewisse Skepsis gegenüber der derzeit verbreiteten Praxis, die Leistungsfähigkeit von KI-Systemen ausschließlich anhand der Endergebnisse zu bewerten. Gerade bei komplexen Denkprozessen kann diese Methode irreführend sein, da sie nicht offenlegt, ob die Antworten durch authentisches Verständnis oder durch Auswendiglernen entstanden sind. Apples Ansatz, interne Denkwege konsequent zu analysieren, könnte zukünftig als idealer Maßstab für echte Intelligenzleistungen dienen. Darüber hinaus eignet sich die Studie als wertvolles Beispiel dafür, wie Forschung im Bereich der Künstlichen Intelligenz künftig gestaltet werden kann: transparent, methodisch strikt und mit Fokus auf eine tiefere Einsicht in die Qualitäten und Defizite der Modelle.
Nicht zuletzt ist diese Veröffentlichung Teil eines wachsenden Trends großer Tech-Unternehmen, ihre Forschungsergebnisse offen zu teilen, was der gesamten Community zu Gute kommt. Zusammenfassend zeigt das Apple-Paper eindrucksvoll, wie weit wir mittlerweile bei der Entwicklung von KI-Modellen sind, die nicht nur Antworten liefern, sondern auch versuchen, komplexe Denkprozesse zu simulieren. Gleichzeitig macht es aber auch klar, dass wir erst am Anfang stehen, wenn es darum geht, Systeme zu schaffen, die wirklich vertrauenswürdig und in ihrer Argumentation robust sind. Die Untersuchung legt nahe, dass es für die Weiterentwicklung von LLMs von zentraler Bedeutung ist, die Grenzen ihrer gegenwärtigen Denkfähigkeit ehrlich zu erkennen und gezielt an Lösungen zu arbeiten, die eine konsistentere, algorithmisch fundiertere und skalierbarere Denkweise ermöglichen. Für Anwender, Entwickler und Forscher bedeutet dies, dass der Blick stärker auf die innere Logik der Modelle gerichtet werden sollte, um ihre tatsächlichen Stärken optimal zu nutzen und Schwächen verantwortungsbewusst zu adressieren.
Apples aktueller Beitrag stellt hier einen wichtigen Meilenstein dar und wird sicher viele weitere spannende Diskussionen und Innovationen anstoßen, die die Zukunft der KI entscheidend prägen dürften.