Am 12. Juni 2025 wurde die technologische Welt durch eine großflächige Störung zahlreicher Google Cloud Platform (GCP) Produkte erheblich beeinträchtigt. Nutzer weltweit berichteten von Ausfällen, erhöhten Fehlermeldungen und Beeinträchtigungen in verschiedensten Google Cloud und Google Workspace Diensten, was zu erheblichen Problemen für Unternehmen führte, die auf die Zuverlässigkeit dieser Plattformen angewiesen sind. Diese Störung betraf eine breite Palette von Services, von API Gateways über Cloud Storage bis hin zu identitätsbezogenen Diensten und künstlicher Intelligenz. Die Auswirkungen waren global spürbar, mit besonderer Intensität in der Region US-Central-1.
In diesem umfassenden Bericht wird die Ursache der Störungen, die betroffenen Produkte, die Wiederherstellungsmaßnahmen sowie die langfristigen Strategien zur Vermeidung ähnlicher Vorfälle eingehend analysiert. Im Kern der Störung stand der Google API Management- und Kontroll-Stack, der dafür verantwortlich ist, dass API-Anfragen autorisiert, überprüft und kontrolliert werden. Zentral für diese Prozesse ist die Komponente „Service Control“, die regional arbeitet und auf eine Datenbank namens Spanner zugreift, um Quoten- und Richtliniendaten zu verarbeiten. Am 29. Mai 2025 wurde eine neue Funktion in der Service Control eingeführt, die zusätzliche Quotenprüfungen vornimmt.
Obwohl die neue Funktion schrittweise ausgerollt wurde, wurde der pfad, der den Fehler auslöste, erst durch eine nachträgliche Richtlinienänderung am 12. Juni global aktiviert, was zu einem kritischen Fehler führte. Das Problem lag darin, dass bei der Richtlinienaktualisierung leere Felder übermittelt wurden. Diese führten zu einem sogenannten Null-Pointer-Fehler in der Service Control, welcher in der Folge die entsprechenden Prozesse zum Absturz brachte. Dies verursachte eine Kettenreaktion: Zahlreiche Dienste, die auf diese Quoten- und Richtlinienprüfungen angewiesen sind, konnten ihre API-Anfragen nicht verarbeiten und antworteten mit Fehlermeldungen, hauptsächlich mit HTTP-Status 503.
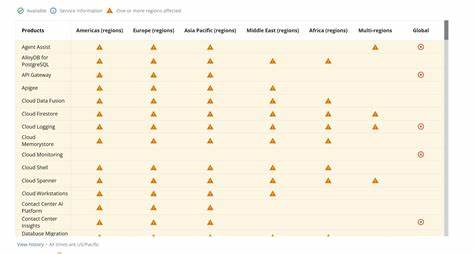
Diese Fehler bedeuteten für die Nutzer, dass ihre Anfragen nicht bearbeitet werden konnten, was zu erheblichen Verzögerungen und Ausfällen in den betroffenen Produkten führte. Die Störung machte sich nicht nur regional bemerkbar, sondern breitete sich aufgrund der globalen Replikation der Quoteninformationen zügig auf nahezu sämtliche Google Cloud-Rechenzentren weltweit aus. Betroffene Standorte reichten von Johannesburg über mehrere asiatische Regionen bis hin zu Europa, Nord- und Südamerika sowie dem Nahen Osten und Australien. Besonders die Region us-central1 kämpfte aufgrund von Überlastungen in den zugrundeliegenden Spanner-Datenbanken mit einer verzögerten Wiederherstellung, was die Dauer der Störung erheblich verlängerte. Die Liste der betroffenen Produkte war lang und umfasste essentielle Google Cloud Services und deren Ableger.
Darunter befanden sich Produkte wie API Gateway, AlloyDB für PostgreSQL, Cloud Firestore, Cloud Logging, Cloud Memorystore, Cloud Monitoring, Cloud Run, Cloud Spanner, Dialogflow, Google BigQuery, Google Cloud Storage, Google Compute Engine, Identity and Access Management sowie Vertex AI Dienste. Zudem waren viele Google Workspace Produkte wie Gmail, Google Drive, Google Calendar und Google Docs von den Ausfällen betroffen. Die Mehrzahl dieser Dienste ist integraler Bestandteil moderner Unternehmensinfrastrukturen und damit die Auswirkungen auf den Geschäftsbetrieb gravierend. Die Google-Ingenieure reagierten schnell: Innerhalb von Minuten nach Beginn der Krise wurde der Fehler eingegrenzt und ein „Red-Button“, eine Sicherheitsabschaltung für die fehlerhafte Codepfad-Funktion, aktiviert. Dies führte zu einer schrittweisen Wiederherstellung der Services, allerdings zeigte sich insbesondere in größeren Regionen wie us-central1 eine sogenannte „Herdeneffekt“-Problematik, bei der gleichzeitiges Hochfahren vieler Prozesse die Datenbankinfrastruktur zusätzlich belastete.
Die Ingenieure mussten daher zusätzliche Kapazitätssteuerungen implementieren und den Datenverkehr auf multiregionale Datenbanken umleiten, was Stunden in Anspruch nahm. Im Verlauf des Tages wurden die meisten Dienste wiederhergestellt, jedoch traten bei einigen Services wie Google Cloud Dataflow, Personalized Service Health und Vertex AI Online Prediction noch verzögerte Fehler auf. Hier kam es weiterhin zu erhöhten 5xx-Fehlerraten bei API-Anfragen, die sich erst über mehrere Stunden abschwächten. Besonders das Modell „Model Garden“ bei Vertex AI war betroffen und konnte eine Zeit lang nicht vollumfänglich genutzt werden. Google adressierte die Ursachen mit einer Reihe kurzfristiger und langfristiger Maßnahmen.
Kurzfristig wurden alle Änderungen und manuelle Richtlinieneinspielungen für den Service Control Bereich eingefroren, um weitere Fehler zu vermeiden. Langfristig plant Google eine umfassende Überarbeitung der Service Control Architektur, um einzelne funktionale Komponenten zu isolieren und Fehler im System besser handhaben zu können, ohne dass der gesamte Dienst ausfällt. Zudem soll das Ausrollen von neuen Features zukünftig vollständig durch Feature Flags geschützt werden, um fehlerhafte Pfade vor der Aktivierung abzufangen. Ein weiterer wichtiger Punkt betrifft die Datenreplikation. Google will sicherstellen, dass globale Datenupdates inkrementell erfolgen und ausreichend Validierungszeit zur Verfügung steht, bevor die Daten weltweit angewendet werden.
Die Einführung von Backoff-Mechanismen, die das Überlastungsrisiko minimieren, wird ebenfalls gezielt verbessert. Darüber hinaus wird die Transparenz und Qualität der Kommunikation mit den Kunden intensiviert, um in Notfällen schnellere und aussagekräftigere Informationen bereitstellen zu können. Der Ausfall des Cloud Service Health Dashboards während des Vorfalls wurde als besonders kritisch angesehen, da es den Kunden die Möglichkeit zur Echtzeitbeobachtung des Systemzustands nahm. In Zukunft sollen Monitoring- und Kommunikationssysteme auch bei primären Ausfällen zuverlässig funktionieren, um die Geschäftskontinuität der Kunden zu sichern. Für Unternehmen, die intensiv auf Google Cloud setzen, verdeutlicht diese Störung die Wichtigkeit robuster Ausfallszenarien und einer Diversifikation der Cloud-Ressourcen.
Die Abhängigkeit von einzelnen Cloud-Diensten kann bei systemweiten Ausfällen erhebliche Risiken bergen. Daher empfiehlt es sich, Notfallpläne zu entwickeln, redundante Systeme zu implementieren und die Auswirkungen von Cloud-Ausfällen auf kritische Geschäftsprozesse regelmäßig zu evaluieren. Die Offenheit von Google bei der Kommunikation und die Schnelligkeit der Reaktion zeigen die hohe Bedeutung, die das Unternehmen der Stabilität seiner Cloud-Plattform beimisst. Die geplanten technischen Verbesserungen werden langfristig dazu beitragen, die Zuverlässigkeit der Dienste weiter zu stärken und die Nutzererfahrung zu verbessern. Dennoch mahnt dieser Vorfall zur Wachsamkeit und zur proaktiven Vorbereitung auf unerwartete technische Schwierigkeiten.
Zusammenfassend stellt der großflächige Ausfall bei Google Cloud am 12. Juni 2025 ein bedeutendes Ereignis in der Geschichte der Cloud-Infrastruktur dar, das die Verwundbarkeit auch großer und etablierter Systeme deutlich macht. Für Nutzer und Unternehmen bietet der Vorfall wichtige Erkenntnisse und Impulse, Cloud-Strategien kritisch zu überprüfen, für robustere Architektur zu sorgen und sich auf Notfallsituationen bestmöglich vorzubereiten. Google seinerseits ist gefordert, die gewonnenen Erkenntnisse fundiert umzusetzen, um das Vertrauen in die Cloud-Dienste weiter zu festigen und Ausfälle künftig zu vermeiden. Die gesamte Technologiebranche beobachtet gespannt die Nachwirkungen dieses Vorfalls.
Das Zusammenspiel von Features, globaler Datenreplikation und komplexen Systemarchitekturen ist eine Herausforderung, die stetige Innovation und sorgfältige Umsetzung erfordert. Die Cloud der Zukunft wird von Unternehmen, Entwicklern und Anbietern gleichermaßen getragen, und die Ereignisse dieser Störung sind ein Weckruf, weiterhin höchste Standards an Sicherheit, Verlässlichkeit und Kommunikation zu setzen.