In der sich rasant entwickelnden Welt der Künstlichen Intelligenz und insbesondere der Sprachmodelle stehen Entwickler und Anwender ständig vor neuen Herausforderungen. Ein besonders bemerkenswertes Phänomen zeigt sich derzeit bei den Claude-Modellen von Anthropic. Während frühere Versionen relativ präzise nur die gewünschten Codeänderungen ausgegeben haben, neigen die neueren Varianten dazu, den gesamten Quellcode einer Datei als Antwort auszugeben. Dieses Verhalten führt zunehmend zu Frustration bei Nutzern, die schnelle, gezielte Änderungen in ihren Projekten erwarten. Die Hintergründe dieses Trends, die Reaktionen der verschiedenen Modellversionen sowie konkret umsetzbare Lösungsansätze werden im Folgenden eingehend beleuchtet.
Die Claude-Modelle, bekannt für ihre hervorragenden Fähigkeiten im Bereich der Codegenerierung, haben mit den Versionen Claude 3.7 Sonnet und Claude Sonnet 4 eine markante Veränderung erfahren. Anwender stellen fest, dass diese Modelle standardmäßig ganze Code-Dateien ausgeben – unabhängig davon, ob im Prompt lediglich nach geringfügigen Modifikationen gefragt wurde. Bereits einfache Aufgaben wie das Hinzufügen eines einzelnen Datenfeldes führen so zu äußerst umfangreichen Ausgabeergebnissen. Dagegen verhält sich die Vorgängerversion Claude 3.
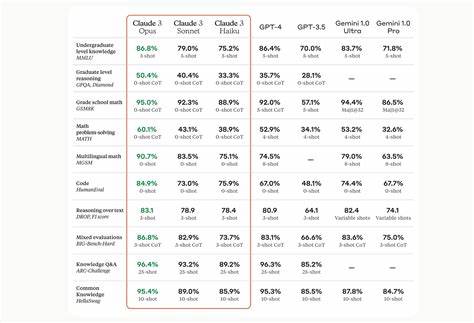
5 Sonnet deutlich instruktionstreuer und folgt Aufforderungen, nur die relevanten Änderungen herauszufiltern. Ebenso zeigen andere Modelle wie GPT-4.1 eine stärkere Präzision bei der Einhaltung solcher Anforderungen und erzeugen weniger redundante Codeblöcke. Die Ursachen für dieses Verhalten sind bislang nicht offiziell von Anthropic bestätigt, lassen sich jedoch anhand der Modelleigenschaften schlüssig nachvollziehen. Zum einen könnte ein Trainingsdatensatz vorliegen, der bevorzugt mit kompletten Dateiausgaben arbeitet.
Das würde einen Bias erzeugen, der auf Vollständigkeit und Vollständigkeitsvermeidung setzt. Die Modelle sollen somit aus Sicherheitsgründen und zur Verbesserung der Verständlichkeit stärker dazu tendieren, Kontext vollständig abzubilden, um Fehlinterpretationen zu minimieren. Außerdem ist es denkbar, dass das Modell-Design den Schwerpunkt auf umfangreiche Hilfestellung und Vollständigkeit gelegt hat, um auch weniger erfahrenen Anwendern die Interpretation zu erleichtern. Trotz möglicher Vorteile ergeben sich für erfahrene Softwareentwickler, die schnell präzise Änderungen benötigen, erhebliche Nachteile. Die standardmäßige Ausgabe des gesamten Codes erschwert das Auffinden der tatsächlich relevanten Anpassungen, verlangsamt den Entwicklungsprozess und führt zu unnötigem Mehraufwand bei der Nachbearbeitung.
Die Rolle der Promptgestaltung gewinnt hier eine zentrale Bedeutung. Versuche mit einfachen Aufforderungen, wie „Gib nur die geänderten Codezeilen aus“, zeigen bei den neueren Claude-Modellen nicht die gewünschte Wirkung. Diese ignorieren derartige moderate Anweisungen häufig und liefern weiterhin vollständige Dateien. Einblick in diese Problematik geben vergleichende Experimente, die verschiedene Promptvarianten mit unterschiedlichen Modellen testen. Besonders effektiv erwiesen sich dabei stark verstärkte Anweisungen, beispielsweise mit Formulierungen wie „Gib auf keinen Fall den vollständigen Code aus.
Zeige ausschließlich die tatsächlich zu ändernden Teile“. Diese stärkeren Befehle führten dazu, dass das Modell Claude Sonnet 4 erstmals zwischen den relevanten Änderungen und dem Gesamtcode differenzierte und nur die notwendigen Modifikationen ausgab. Claude 3.7 Sonnet dagegen bleibt sich treu und zeigt selbst bei maximalen Promptverstärkungen keine Kompromisse: Das Modell gibt weiterhin komplette Dateien aus und lässt sich durch promptseitige Manipulationen nicht auf präzise Codeänderungen beschränken. Die Konsequenz daraus liegt für Entwickler auf der Hand: Wenn präzise, minimalistische Ausgaben gefordert sind, empfiehlt sich die Nutzung neuester Claude-Modelle nur dann, wenn entsprechende starke Prompt-Instruktionen verwendet werden.
Alternativ ist ein Wechsel zu älteren Versionen wie Claude 3.5 Sonnet oder zu anderen leistungsstarken Modellen wie GPT-4.1 möglich, die von Haus aus besser mit solch strikten Anforderungen umgehen. Auch Gemini 2.5 Pro zeigt bei sinnvollem Feinjustieren der Prompts eine verbesserte Output-Konsistenz und kann mittels direkter Anweisungen „sei prägnant“ auf kurz gehaltene Veränderungen eingeschworen werden.
Neben praktischen Aspekten stellt sich die Frage nach den Wirkungen auf den Arbeitsalltag und den Umgang mit KI-unterstützter Softwareentwicklung. Während Vollständigkeit und größere Ausgaben für Anfänger und visuell orientierte Nutzer hilfreich sein können, stehen professionelle Coding-Teams oftmals unter Zeitdruck und benötigen punktgenaue Resultate ohne unnötiges Rauschen. Abrufen kompletter Dateien verzögert die Integration in bestehende Projekte und erzeugt unnötige Komplexität beim Review-Prozess. Die Herausforderung liegt daher darin, mit den Tools und vorhandenen Modellen intelligenter umzugehen. Ein sinnvoll strukturierter Prompt-Aufbau wird unverzichtbar.
Empfehlenswert sind klare und wiederholte Hinweise, welche exakt definieren, wie der Output strukturiert sein soll, zum Beispiel die explizite Aufforderung, keine vollständigen Dateien zu liefern, sondern sich ausschließlich auf notwendige Änderungen zu beschränken. Ebenso nützlich sind Beispiel-Codestücke im Prompt, welche die gewünschte Output-Form demonstrieren. Zusätzlich sollte die Einbettung von Kontext geschickt umgesetzt werden, damit das Modell erkennt, welche Codeabschnitte unverändert bleiben und entsprechend durch Kommentare repräsentiert werden können. Entwickler sind angehalten, ihre Prompts nicht nur informativ, sondern auch rigoros präzise und unmissverständlich zu formulieren. Parallel dazu tragen Tools, die das Verhalten der Modelle auswerten und den Output automatisch vergleichen, dazu bei, die bestmöglichen Prompt-Inputs zu identifizieren.
Die Plattform 16x Eval ist ein Beispiel für solche Werkzeuge, die eine systematische Evaluierung von Modell-Prompt-Kombinationen erlauben und somit Zeit bei der Optimierung sparen. Auch im Vergleich mit anderen Modellen wird deutlich, dass die Prompt-Engineering-Maßnahmen bei GPT-4.1 einen relativ geringen Aufwand erfordern, um sauberen, fokussierten Code zu erhalten. Die Notwendigkeit aggressiver Perfektionierung ist größten Teils bei den neuen Claude-Versionen gegeben. Daraus resultiert eine klare Empfehlung für Projektmanager und Entwicklerteams, bei der Auswahl der KI-gestützten Werkzeuge neben der reinen Leistungsfähigkeit auch die Flexibilität und Instruktionsfolgsamkeit zu berücksichtigen.
Ein weiterer Aspekt betrifft den Einfluss auf die Weiterentwicklung von KI-Modellen. Die Tatsache, dass neuere Versionen tendenziell mehr Vollständigkeit bieten, könnte eine Absicht widerspiegeln, im Sinne der Nachvollziehbarkeit und Transparenz von Outputs Verantwortung zu übernehmen. Gerade im Umfeld von kritischen Anwendungen ist eine Vollständigkeit der gezeigten Codebasis hilfreich, um Seiteneffekte zu vermeiden. Gleichzeitig zeigt das Nutzungsverhalten, dass Entwickler zunehmend differenzierte Steuerungsmöglichkeiten erwarten. Die Möglichkeit, die Ausgabegranularität durch einfache und intuitive Prompts einzustellen, wird als essenziell eingestuft.
Die Entwicklung zukünftiger Modellgenerationen wird sich daher mit hoher Wahrscheinlichkeit auf bessere Instruktionsaufnahme und fein abgestimmte Steuermöglichkeiten konzentrieren müssen. Zusammenfassend spiegelt das Beobachtete eine doppelte Herausforderung wider: Auf der einen Seite will die KI umfassend und hilfreich sein, auf der anderen muss sie präzise und zielgerichtet agieren können. Die aktuellen Claude-Modelle positionieren sich eher im ersteren Spektrum, wodurch zwingend stärkere Prompts benötigt werden, um gewünschte Genauigkeit zu erreichen. Für Entwickler liegt der Schlüssel zum optimalen Einsatz darin, die Eigenheiten der jeweiligen Modellversion zu kennen und Prompts intelligent anzupassen. Durch experimentelles Testen, zum Beispiel mit Tools wie 16x Eval, lassen sich die besten Kombinationen aus Modell und Eingabeaufforderung ermitteln.
So können Entwickler die Balance zwischen Vollständigkeit und Präzision effektiv steuern und ihre Coding-Prozesse maximal effizient gestalten. Die Zukunft der KI-gestützten Codegenerierung wird maßgeblich davon abhängen, wie flexibel und präzise diese Modelle in der Steuerung ihrer Ergebnisse werden. Die gewonnenen Erkenntnisse zu den aktuellen Claude-Versionen sind dabei wertvolle Hinweise. Insbesondere die Möglichkeit, mit klaren und starken Prompts Einfluss auf den Outputumfang zu nehmen, stellt eine wichtige Lektion für Anwender und Modelldesigner dar. Ebenso zeigt der Vergleich mit anderen modernen KI-Modellen Parallelen und Unterschiede auf, die für die Auswahl der passenden Technologie in Abhängigkeit vom jeweiligen Anwendungsfall richtungsweisend sind.
Letztendlich ist die intelligente Kombination von Modellwahl und durchdachtem Promptdesign der Schlüssel zu effizienter, zielgenauer und praxisorientierter KI-gestützter Softwareentwicklung in der Zukunft.



![The Gift and the Curse of Staying Private with Bill Gurley [video]](/images/48F532AC-94EE-4C72-A1E6-01AF8379D9C7)