Die Welt der Suchtechnologien ist dynamisch und vielschichtig. Zwei prominente Vertreter in diesem Bereich sind Vespa und Elasticsearch. Beide versprechen leistungsfähige Suchlösungen, sind jedoch in ihren technischen Ansätzen und Anwendungsstärken unterschiedlich. Ein aktueller Benchmark-Vergleich, der von den Vespa-Entwicklern durchgeführt und von einem erfahrenen Lucene-Entwickler analysiert wurde, gibt spannende Einblicke in die Leistungsfähigkeit beider Systeme und deren Unterschiede in verschiedenen Einsatzszenarien. Dieser Vergleich ist von besonderem Interesse, da Vespa und Elasticsearch trotz ähnlicher Zielsetzungen unterschiedliche Architekturentscheidungen getroffen haben, die sich deutlich auf ihre Performance und Nutzung auswirken.
Vespa, als Suchplattform mit Fokus auf Echtzeit-Suche, zeichnet sich insbesondere durch die Fähigkeit aus, Dateien direkt vor Ort zu modifizieren. Diese in-place Änderungen ermöglichen es Vespa, Updates nahezu sofort in den Suchindex einfließen zu lassen und dadurch eine besonders aktuelle Sucherfahrung zu bieten. Dagegen basiert Elasticsearch auf dem Lucene-Ökosystem, das eine write-once-Directory-Abstraktion verwendet. Hier werden keine Dateien im Index selbst verändert, sondern neue Segmente geschrieben und alte veraltet markiert beziehungsweise durch Zusammenführungen konsolidiert. Obwohl diese Methode eine gewisse Verzögerung bei der Indizierung neuer Daten mit sich bringt, besitzt sie Vorteile bei der Skalierbarkeit und Replikation.
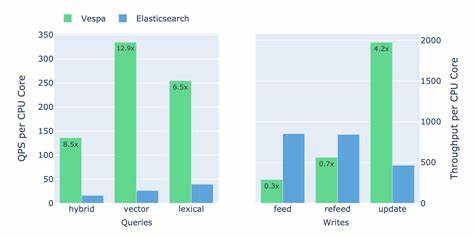
Die Segment-basierten Indexdateien können leicht auf verschiedene Suchknoten verteilt werden, was eine effiziente Lastverteilung und hohe Verfügbarkeit ermöglicht. Ein zentrales Thema im Benchmark ist die Performance bei Schreib- und Aktualisierungsoperationen. Lucenes sogenannter Near-Realtime-Search-Mechanismus sorgt dafür, dass geänderte Daten erst nach dem Flushen von Segmenten für Suchanfragen verfügbar sind. Flush- und Merge-Prozesse erschweren hier die Veröffentlichung von Updates und führen teilweise zu einer spürbaren Systemlast. Besonders bei häufigen Änderungen und Echtzeit-Anforderungen zeigt Vespa hier Vorteile, da es Updates in-place vornehmen kann und somit den Overhead durch Segment-Flushing vermeidet.
Zusätzlich ist die Datenstruktur von Vespa auf die Unterstützung schneller Vektor-Operationen ausgelegt, wohingegen das Zusammenführen von Vektordaten in Lucene vergleichsweise langsam erfolgt. In Szenarien mit regelmäßigen und intensiven Updates zeigt der Benchmark eine bessere Performance von Vespa, die sich auf zeitkritische Anwendungen positiv auswirkt. Auf der anderen Seite schlägt Lucene mit einer besseren Performance bei rein append-lastigen Workloads zu Buche, in denen Daten hauptsächlich hinzugefügt und selten bearbeitet werden. Die Fähigkeit, Index-Operationen zu bündeln und effizienter abzuarbeiten, ermöglicht Elasticsearch in solchen Fällen oft eine höhere Indexierungsgeschwindigkeit. Ein interessanter Kritikpunkt im Benchmark betrifft die Vorgehensweise bei kompletten Reindexierungen, die bei Elasticsearch in-place durchgeführt wurden.
Eine Alternative wäre das Indizieren in einen neuen Index, gefolgt von einem Alias-Update zur Suche und anschließender Löschung des alten Index. Diese Methode würde eine schnellere Ausführung ermöglichen und die Verfügbarkeit der Suche während der Neuberechnung verbessern. Die Abfrageperformance ist ein weiterer bedeutender Aspekt, der im Vergleich behandelt wird. In der Praxis enthalten Suchanfragen häufig Filter, etwa nach Mandantenkennung, Kategorie oder weiteren Parametern. Viele Benchmarks vernachlässigen jedoch diesen Aspekt und messen lediglich reine Volltextsuchanfragen.
Diese Untersuchung hingegen schätzt Filter sehr und visualisiert deren Einfluss auf die Leistung. Zudem werden Abfragen über mehrere Suchfelder ausgewertet – auch hier hebt sich der Benchmark positiv hervor, da viele vergleichende Tests diese Komplexität nicht berücksichtigen. Eine Herausforderung bleibt jedoch die Berechnung der Ähnlichkeit bei Multi-Field-Suchen: Das bisher verwendete Verfahren, das den maximalen Wert über alle Felder nimmt, ist weniger robust als beispielsweise BM25F, welches die Scores auf differenzierte Weise kombiniert. Diese Problematik betrifft Elasticsearch ebenso wie Lucene und verdeutlicht den Bedarf an weiterentwickelten Suchstrategien, um präzisere und leistungsfähigere Suchergebnisse zu erzielen. Auch die Kombination von Vektor- und lexikalischer Suche wird diskutiert.
Der Benchmark verzichtete auf die Nutzung von Reciprocal Rank Fusion (RRF), da diese Funktion in Elasticsearch als experimentell gilt. Künftige Tests mit RRF könnten die Suchpräzision und auch die Performance verbessern. Der gegenwärtige Einsatz von Vektor-Abfragen als optionale Bestandteile von Bool-Queries scheint dynamische Optimierungen wie Pruning zu verhindern, was sich leistungsmäßig negativ bemerkbar macht. Die Kombination von Lexikal- und Vektor-basierten Suchverfahren ist ein aufstrebendes Thema und zentral für anspruchsvolle Anwendungen im Bereich der semantischen Suche. Im Bereich der Latenzzeit und des Durchsatzes bei unfilterter semantischer Suche liefert Vespa im Benchmark etwa doppelt so hohe Werte wie Elasticsearch.
Technisch gesehen sollten beide Systeme mit einem vergleichbaren HNSW-Datenstruktur-Index arbeiten, der nach ähnlichen Parametern aufgebaut ist. Dieses Ergebnis wirft Fragen nach möglichen Optimierungen in Lucene/Elasticsearch auf. Hier könnten spezielle Indexierungs- oder Abfrageoptimierungen fehlen, die Vespa besser nutzt. Dieses Thema bleibt spannend, da es Spielraum für Performance-Verbesserungen im Lucene-Ökosystem bietet. Trotz der gezeigten Vorteile von Vespa sieht der Berichterstatter auch die Stärken von Elasticsearch und Lucene.
Besonders die Möglichkeit, unveränderliche Segmente effizient zu replizieren, stellt ein großes Skalierungspotential dar, das zunehmend von großen Unternehmen genutzt wird. Amazon, Yelp oder OpenSearch demonstrieren, wie Segment-Replikation eine flexible und kosteneffiziente Lastverteilung untermauert. Hier liegt ein wichtiger Gestaltungsvorteil gegenüber Vespa, das durch seine In-place-Update-Fähigkeiten zwar schneller bei Echtzeit-Updates ist, eventuell aber bei der horizontalen Skalierung Herausforderungen hat. Weitere Verbesserungsmöglichkeiten für Elasticsearch umfassen ein besseres Benchmarking des Szenarios „Suchen während des Indexierens“ mit sehr kurzen Refresh-Intervallen. Funktionen wie das sogenannte Merge-on-Refresh oder das Überspringen der HNSW-Grafik-Erstellung bei kleinen Segmenten könnten in künftigen Versionen die Effizienz steigern.
Ebenfalls spannend ist die Evaluation von Doc-Value-Updates, die selektiv nur auf das geänderte Feld wirken und dadurch die Schreib-Last reduzieren können. Diese Technik wird bereits in Solr und nrtSearch genutzt, findet aber bisher weniger Aufmerksamkeit in Elasticsearch. Insgesamt unterstreicht der Benchmark-Vergleich die Entwicklungen und Innovationspotenziale beider Systeme. Vespa glänzt durch seine Echtzeit-Fähigkeiten und die flexible In-place-Modifikation, während Elasticsearch durch Basisarchitektur und Replikationsmechanismen in großen, verteilten Umgebungen punktet. Die Zukunft verspricht weitere Verbesserungen und möglicherweise auch eine Annäherung in der Performance, wobei jede der Technologien ihre individuellen Stärken behalten dürfte.
Für Entwickler und Architekten bedeutet dies, die Wahl der Suchplattform grundsätzlich auf den individuellen Anwendungsfall abzustimmen. Wer höchste Echtzeit-Anforderungen bei häufigen Updates hat, ist mit Vespa möglicherweise besser bedient. Für Anwendungen mit schwerpunktmäßig append-lastigen Workloads und großen verteilten Clustern bietet Elasticsearch oft die bessere Grundlage. Der Vergleich zeigt auch die Bedeutung sorgfältiger und realitätsnaher Benchmarks, die Faktoren wie Filter, Multi-Feld-Suchen und hybride Suchansätze berücksichtigen. Die Auswahl der richtigen Suchstrategie, von der Indexierung über die Anfragegestaltung bis zur Systemeinstellung, bleibt ein Schlüssel zum Erfolg bei der Implementierung effizienter Suchlösungen.
Die Erkenntnisse aus diesem Benchmark liefern wertvolle Impulse, wie bestehende Suchtechnologien weiterentwickelt und in der Praxis optimal eingesetzt werden können. So bleibt die Suche auch in Zukunft ein spannendes und innovationsgetriebenes Feld in der IT-Landschaft.