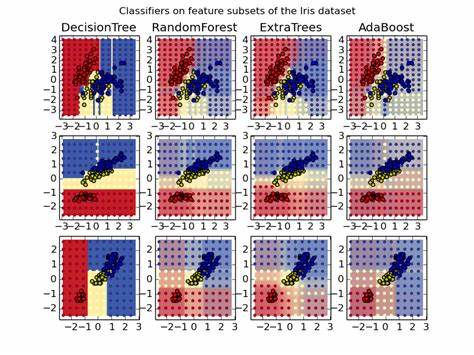
Random Forests haben sich seit ihrer Entwicklung zu einem der populärsten und vielseitigsten Algorithmen im Bereich des maschinellen Lernens entwickelt. Ihr Erfolg beruht auf ihrer Fähigkeit, auf verschiedensten Datentypen und in unterschiedlichsten Szenarien robuste und zuverlässige Modelle zu erzeugen. Im Gegensatz zu vielen komplexen Algorithmen bieten Random Forests eine bemerkenswerte Balance zwischen Leistung, Einfachheit und Interpretierbarkeit, was sie für viele Praktiker und Forscher äußerst attraktiv macht. Die Grundidee hinter Random Forests ist simpel, aber wirkungsvoll: Durch die Kombination vieler Entscheidungsbäume, die jeweils auf einer zufälligen Teilmenge von Daten und Merkmalen trainiert werden, entstehen Modelle, die in der Lage sind, komplexe Zusammenhänge zu erfassen, ohne leicht zu überfitten. Diese Technik der Ensemble-Lernmethoden nutzt die Diversität der Bäume aus, um Fehler einzelner Modelle zu kompensieren und somit insgesamt bessere Vorhersagen zu erzielen.
Ein großer Vorteil von Random Forests ist die geringe Notwendigkeit einer aufwendigen Datenvorbereitung. Sie können problemlos mit binären, kategorialen oder numerischen Daten umgehen, ohne dass eine Normalisierung oder Standardisierung erforderlich ist. Diese Eigenschaft spart Anwendern sehr viel Zeit und reduziert potenzielle Fehlerquellen in der Datenaufbereitung. Zudem führen Random Forests eine implizite Merkmalsauswahl durch. Dadurch können sie wichtige Variablen identifizieren und deren Einfluss auf die Vorhersage quantifizieren, was für das Verständnis der Daten und die Modellinterpretation von großem Nutzen ist.
Ein weiterer Aspekt, der Random Forests auszeichnet, ist ihre relative Unempfindlichkeit gegenüber der Wahl der Hyperparameter. Während viele andere maschinelle Lernalgorithmen einer genauen Feinabstimmung bedürfen, um gute Ergebnisse zu erzielen, können Random Forests mit einer großen Anzahl von Bäumen und standardmäßigen Einstellungen oft bereits sehr gute Performance liefern. Dies macht sie besonders attraktiv für Anwender, die schnell erste Modelle evaluieren möchten, ohne tiefgehendes Expertenwissen in Hyperparameter-Optimierung zu besitzen. Die Trainingsgeschwindigkeit von Random Forests ist ebenfalls bemerkenswert, besonders wenn man die Qualität der Modelle berücksichtigt. Durch das Konzept des zufälligen Teilens der Merkmale und der Proben werden die einzelnen Bäume effizienter aufgebaut.
Darüber hinaus erlauben diese Algorithmen eine einfache Parallelisierung, was große Datensätze noch schneller bearbeitbar macht – ein Vorteil, den komplexe Modelle wie tiefe neuronale Netze oder manche Boosting-Verfahren nicht in gleichem Maße bieten. Trotz ihrer vielen Stärken sind Random Forests keineswegs unbesiegbar. In manchen Fällen können spezialisierte Algorithmen, wie Gradient Boosting oder tiefere neuronale Netzwerke, eine bessere Performance erzielen – allerdings meist zu Lasten eines erheblichen Mehraufwands bei der Trainingszeit und der Notwendigkeit einer sorgfältigen Parametereinstellung. Für viele praktische Anwendungen bieten Random Forests deshalb eine hervorragende Ausgangsbasis oder Benchmark, an der andere Modelle gemessen und weiterentwickelt werden können. Ein Kritikpunkt, der gelegentlich gegenüber Random Forests geäußert wird, betrifft die Speichergröße und Geschwindigkeit bei der Vorhersage.
Weil sie aus vielen einzelnen Bäumen bestehen, können die resultierenden Modelle sehr groß werden und dadurch mehr Ressourcen benötigen als einfachere Modelle. Dies kann in Umgebungen mit beschränkten Speicherressourcen oder Echtzeitanforderungen problematisch sein. Darüber hinaus wird Random Forest häufig als Black Box betrachtet, deren innere Funktionsweise schwer zu interpretieren ist. Zwar erlauben einzelne Entscheidungsbäume eine einfache visuelle Darstellung, doch das Ensemble als Ganzes verliert oft diese Transparenz. Dennoch gibt es Methoden wie die Berechnung von Feature Importances oder Partial Dependence Plots, die eine annähernde Erklärung der Modellentscheidungen ermöglichen und die Akzeptanz in kritischen Anwendungsgebieten steigern.
Random Forests sind außerordentlich vielseitig und finden Anwendung in zahlreichen Bereichen, von klassischen Klassifikations- und Regressionsproblemen bis hin zu komplexeren Aufgaben wie der Clusteranalyse. Diese Flexibilität macht sie zu einem unverzichtbaren Werkzeug für Data Scientists und Machine Learning Engineer. Ihre Verbreitung wird durch hochwertige, kostenlose Implementierungen in Bibliotheken wie scikit-learn, R und Weka stark unterstützt, was den Zugang für Anwender aller Erfahrungsstufen erleichtert. Die „Unreasonable Effectiveness“ von Random Forests, wie Ahmed El Deeb in seinem einflussreichen Beitrag von 2015 beschreibt, liegt vor allem in der Kombination zahlreicher kleiner, relativ einfacher Entscheidungen, die zusammen ein mächtiges Modell ergeben. Sie bieten eine seltene Mischung aus Effizienz, Benutzerfreundlichkeit und hoher Prognosequalität, die nur durch wenige andere Algorithmen erreicht wird.
Zusammenfassend lässt sich sagen, dass Random Forests aus gutem Grund einen festen Platz in der Toolbox jedes Maschinellen Lernens-Experten innehaben. Sie ermöglichen es, ohne großen Aufwand zuverlässige Modelle zu erstellen und eignen sich daher hervorragend für die schnellen Validierungen von Hypothesen oder als Ausgangspunkt für weiterführende Analysen. Ihre Eigenschaften ermöglichen es auch, Lehrinhalte verständlich zu vermitteln und die Prinzipien des maschinellen Lernens praxisnah zugänglich zu machen. Trotz der zunehmenden Popularität komplexerer Techniken sollte man den Wert von Random Forests nicht unterschätzen. Ihre einfache Struktur, hohe Anpassungsfähigkeit und solide Leistungsfähigkeit garantieren, dass sie auch in Zukunft eine zentrale Rolle in der Datenanalyse spielen werden.
Wer sich tiefgehend mit maschinellem Lernen beschäftigt, sollte Random Forests sowohl verstehen als auch anwenden können, um das Potential dieses einfach genialen Algorithmus voll auszuschöpfen.