Die rasant wachsende Bedeutung von Sprachmodellen hat die Art und Weise, wie Maschinen Sprache verarbeiten, dramatisch verändert. Besonders Very Large Language Models (VLLM) spielen dabei eine zentrale Rolle, da sie die Grundlage für vielfältige Anwendungen bilden, von Chatbots über Suchmaschinen bis hin zu komplexen Empfehlungssystemen. Embeddings, also Vektor-Darstellungen von Texten, sind ein elementarer Bestandteil dieser Technologien, denn sie ermöglichen eine effiziente und semantisch fundierte Verarbeitung von sprachlichen Inhalten. Doch die enorme Größe und Komplexität von VLLM bringen auch Herausforderungen mit sich, insbesondere hinsichtlich Skalierung, Kosteneffizienz und Durchsatz. Eine 16-fache Verbesserung in diesen Bereichen zeigt den Weg zu einer effektiveren Nutzung von VLLM für Embeddings auf und stellt einen bedeutenden Schritt in der KI-Forschung sowie praktischen Anwendung dar.
Eines der größten Hindernisse bei der Nutzung großer Sprachmodelle ist die Rechenintensität. Je größer das Modell, desto mehr Ressourcen werden benötigt, was wiederum zu hohen Kosten und längeren Wartezeiten führt. Gerade bei der Generierung von Embeddings in Echtzeit oder bei der Verarbeitung großer Datenmengen kann dies zum Flaschenhals werden. Die Skalierung von VLLM zielt daher darauf ab, diese Limitierungen zu überwinden, indem sie sowohl Hardware- als auch Softwareoptimierungen nutzen, um den Durchsatz signifikant zu erhöhen und gleichzeitig die Betriebskosten zu senken. Eine wesentliche Strategie zur Skalierung von VLLM besteht in der Optimierung der Berechnungspipelines und der Parallelisierung der Arbeitslast.
Durch verteiltes Computing können verschiedenste Berechnungen auf mehrere Prozessoren oder GPUs aufgeteilt werden, wodurch die Verarbeitungsgeschwindigkeit enorm steigt. Insbesondere die Integration von hochperformanten GPUs, die speziell für maschinelles Lernen optimiert sind, ermöglicht drastische Verbesserungen in der Rechenleistung. Durch intelligente Verteilung der Aufgaben und Minimierung redundanter Verarbeitungsschritte lassen sich Wartezeiten reduzieren und eine nahezu lineare Skalierung realisieren. Parallel zum Hardware-Upgrade spielen auch algorithmische Verbesserungen eine zentrale Rolle. Techniken wie Quantisierung, Pruning und Knowledge Distillation helfen, die Modelle schlanker zu machen, ohne signifikant an Genauigkeit einzubüßen.
Quantisierung reduziert die Präzision der Werte, um Rechenressourcen zu sparen, während Pruning unwichtige Verbindungen im Netzwerk entfernt. Knowledge Distillation wiederum erlaubt es, das Wissen eines großen Modells auf ein kleineres zu übertragen. Diese Methoden tragen maßgeblich dazu bei, gleichzeitig Kosten zu senken und die Latenzzeiten zu verkürzen. Ein weiterer entscheidender Faktor ist die Optimierung der Softwarearchitektur im Umfeld von VLLM. Spezialisierte Frameworks, die für große Sprachmodelle entwickelt wurden, bieten effiziente Speicherverwaltung und optimierte Berechnungskerne.
Sie ermöglichen das schnelle Laden, Zwischenspeichern und den Zugriff auf die Modelle, was besonders bei der Arbeit mit großen Embedding-Datenmengen wichtig ist. Fortschritte in der Nutzung von Mixed Precision Training und Inferenzverfahren reduzieren zudem den Speicherverbrauch und verbessern die Performance, ohne die Genauigkeit zu beeinträchtigen. Parallel zur technologischen Weiterentwicklung verändert sich auch die Infrastruktur, auf der VLLM betrieben werden. Cloud-basierte Lösungen bieten flexible Skalierungsmöglichkeiten und erlauben es Unternehmen, entsprechend ihrem aktuellen Bedarf Ressourcen hoch- oder herunterzufahren. Die Möglichkeit, Kapazitäten dynamisch anzupassen und nur bei tatsächlichem Bedarf zu bezahlen, führt zu einer erheblichen Kosteneinsparung.
Insbesondere durch die Kombination von Cloud-Services mit On-Premise-Hardware können Unternehmen optimale Performance bei maximaler Kontrolle über Kosten und Sicherheit erreichen. Ein besonderer Fokus liegt auch auf der Optimierung der Inferenzphase, bei der die Modelle tatsächlich verwendet werden, um Input-Daten in Embeddings umzuwandeln. Durch den Einsatz von Batch-Processing, bei dem mehrere Anfragen gebündelt abgearbeitet werden, lassen sich die Ressourcen effizienter nutzen. Ebenso helfen Caching-Mechanismen und intelligente Abrufstrategien, wiederholte Berechnungen überflüssig zu machen. Diese Verfahren minimieren den Energieverbrauch und die Latency erheblich, was gerade im produktiven Einsatz großen Mehrwert bietet.
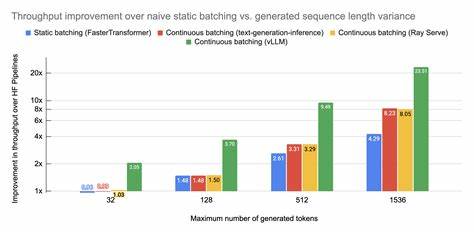
Die Kombination dieser Technologien und Ansätze hat in der Praxis gezeigt, dass eine 16-fache Steigerung des Durchsatzes bei gleichzeitigem Rückgang der Kosten um den gleichen Faktor durchaus realistisch ist. Diese dramatischen Verbesserungen machen den Einsatz von VLLM für Embeddings auch in Bereichen praktikabel, die bisher durch Kosten- und Performancebeschränkungen limitiert waren. Anwendungen wie große semantische Suche, personalisierte Empfehlungssysteme oder automatisierte Textanalyse profitieren enorm von diesen Fortschritten. Darüber hinaus führt die Skalierung der VLLM nicht nur zu unmittelbaren Effizienzgewinnen, sondern erweitert auch den kreativen und technologischen Spielraum für Entwickler und Forscher. Komplexere Modelle mit höherer Genauigkeit und besserem Verständnis der Sprache können so in Echtzeit eingesetzt werden.
Dies eröffnet neue Möglichkeiten in der Entwicklung von Sprachschnittstellen, intelligenten Assistenten und in der Verarbeitung natürlicher Sprache allgemein. Nicht zuletzt verbessern sich durch die erhöhte Datenverarbeitungsrate auch die Trainings- und Feinabstimmungsprozesse von VLLM. Schnelleres Feedback während des Trainings ermöglicht eine zügigere Anpassung der Modelle an spezifische Anwendungsfälle. Die gesunkene Kostenbasis fördert zudem eine breitere Verwendung und Experimente mit größeren Modellen in kleineren Unternehmen und Forschungsgruppen, was insgesamt zu einer Demokratisierung und Beschleunigung der KI-Entwicklung beiträgt. Natürlich bringt die hohe Skalierung auch neue Herausforderungen mit sich.
Sicherheitsaspekte, Datenschutz und verantwortungsbewusste Nutzung rücken stärker in den Fokus, wenn sensibler Inhalt in größeren Mengen verarbeitet wird. Zudem verlangt der Betrieb hochskalierter Infrastruktur ein spezialisiertes Know-how in IT und Datenmanagement. Die kontinuierliche Weiterentwicklung und Integration innovativer Verfahren ist daher essenziell, um die Vorteile von VLLM voll auszuschöpfen und nachhaltige Lösungen zu schaffen. Zukünftige Perspektiven der Skalierung von VLLM für Embeddings zeichnen sich durch eine noch stärkere Integration von Hardware-Optimierungen und softwareseitigen Innovationen ab. Die Erschließung neuer Architekturen, etwa spezialisierte KI-Chips, wird die Effizienz zusätzlich steigern.