Im Bereich der künstlichen Intelligenz und insbesondere im Feld des Reinforcement Learnings (Verstärkungslernen) spielen moderne Optimierungsalgorithmen eine zentrale Rolle, um komplexe Modelle sicher und effizient zu trainieren. Zwei bedeutende Methoden, die in diesem Zusammenhang häufig diskutiert und angewandt werden, sind Proximal Policy Optimization (PPO) und Group Relative Policy Optimization (GRPO). Diese Techniken ermöglichen es Agenten, bzw. großen Sprachmodellen (Large Language Models, LLMs), besser und stabiler zu lernen, indem sie Richtlinien („Policies“) effizient anpassen und dabei das Risiko von übermäßigen, destabilisierten Anpassungen minimieren. Im Folgenden geben wir einen umfassenden Einblick in die Grundlagen, die mathematischen Zusammenhänge und die praktischen Implikationen dieser beiden Algorithmen sowie deren Anwendung innerhalb moderner Sprachmodelle.
Die Entwicklung von Sprachmodellen hat sich in zwei entscheidenden Phasen vollzogen: dem Pre-Training und dem Post-Training. Während das Pre-Training sich auf die Aufnahme von Sprachstrukturen und die Wissensaneignung mittels riesiger Textkorpora konzentriert, dient das Post-Training der Ausrichtung dieser Base-Modelle auf spezifische Aufgaben und Präferenzen. Innerhalb dieses Post-Trainings hat das Reinforcement Learning eine immer größere Bedeutung für die Feinabstimmung (Fine-Tuning) erlangt, indem es hilft, Modelle an menschliche Präferenzen und Belohnungen anzupassen. Im klassischen Verstärkungslernen findet ein Agent in einer Umgebung durch eine durch eine Politik gesteuerte Abfolge von Aktionen („Actions“) statt, die darauf abzielt, eine kumulierte Belohnung („Reward“) zu maximieren. Die Herausforderung bei großen Sprachmodellen besteht darin, dass der klassische Zustand-zu-Aktion-Übergang hinfällig wird: Die „Umgebung“ ist in diesem Fall ein sprachlicher Kontext, und die „Aktion“ ist die generierte Antwort auf einen Prompt.
Belohnungen werden auf der Ebene kompletter Antworten und nicht einzelner Tokens vergeben, was die Problemstellung zu einem sogenannten „Bandit-Problem“ macht. Dieses erschwert die Attribution von Belohnungen auf einzelne Teile einer Antwort – ein klassisches Problem in der Verstärkungslern-Forschung. Um dieses Problem zu adressieren, wird ein sogenanntes Reward Model eingesetzt. Dieses Modell ist eine maschinell gelernte Approximation menschlicher Präferenzen: Es wird darauf trainiert, zu predizieren, welche Antwort eines Sprachmodells von menschlichen Annotatoren bevorzugt wird. Dabei basiert die Belohnung auf einem probabilistischen Modell, das aus Paarbewertungen lernt und die relative Qualität von Antworten quantifiziert.
Das mathematische Fundament hierfür bildet das Bradley-Terry-Modell, welches die Wahrscheinlichkeit angibt, mit der eine Antwort über einer anderen bevorzugt wird. Formuliert als Wahrscheinlichkeitsfunktion verwenden die Modelle eine Sigmoidfunktion auf die Differenz der Reaktions-Belohnungen, was sich elegant in den Verlust für das Training als Kreuzentropie übersetzen lässt. Nachdem das Belohnungsmodell etabliert wurde, stellt sich die Frage, wie die Sprachmodelle diesen Feedback-Signal nutzen, um ihr Verhalten zu verbessern. Hier kommen die Policy-Gradient-Algorithmen ins Spiel. Diese Verfahren optimieren die Parameter einer Policy, indem sie steuern, wie wahrscheinlich bestimmte Aktionen in einem gegebenen Zustand sind, gewichtet durch den Vorteil („Advantage“) einer Aktion gegenüber dem Durchschnitt.
Dabei ist die Herausforderung immer eine angemessene Schätzung des Vorteils, um unnötige Varianz zu vermeiden und gleichzeitig Verzerrungen (Bias) möglichst gering zu halten. Eine wichtige Verbesserung zur stabileren Schätzung bieten sogenannte Generalized Advantage Estimations (GAE). GAE kombiniert mehrere Schätzwerte über verschiedene Zeithorizonte durch gewichtete Mittelbildung, um so eine ausgewogenere und robustere Schätzung des Vorteils zu liefern. Dies ist vor allem in Sprachmodellen bedeutsam, wo Rückmeldungen spärlich sind und nur für komplette Ausgaben vorliegen. Durch die differenzierte Schätzung können einzelnen Tokens innerhalb einer Antwort proportional zur Qualität ihrer Beteiligung ein Vorteil zugeschrieben werden.
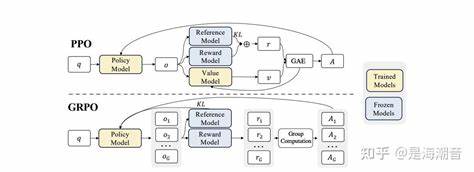
Proximal Policy Optimization (PPO) zählt zu den populärsten Policy-Gradient-Methoden, weil es den Lernprozess stabilisiert und Überschätzungen vermeidet. Wie der Name schon sagt, erlaubt der Algorithmus nur kleine, „proximal“ begrenzte Änderungen an der Policy pro Update-Schritt. Er tut dies durch einen Clipping-Mechanismus, der eine sicherere Optimierung gewährleistet, indem er relative Änderungen in der Wahrscheinlichkeit einer Aktion begrenzt. Der Kern von PPO ist eine Loss-Funktion, die aus dem Minimum zwischen der „ungeclippten“ und der „geclippten“ Policy-Änderung besteht. So verhindert PPO, dass Updates zu drastische Änderungen in der Policy bewirken, was insbesondere in großen neuronalen Netzwerken mit hohen Aktionsräumen wichtig ist, da es sonst zu instabilen oder gar katastrophalen Trainingsergebnissen kommen kann.
In der Welt der großen Sprachmodelle wird PPO oft auf Token-Ebene adaptiert, da die einzelnen Wahrscheinlichkeiten von Tokens kontrolliert werden müssen, um die Qualität der gesamten Antwort zu steuern. Die Policy entspricht hierbei dem Wahrscheinlichkeitsvektor, der die Auswahl des nächsten Tokens vorhersagt. Die Wahrscheinlichkeit für die Generierung eines Tokens wird mit der alten Policy verglichen, und der Vorteil gibt an, wie sehr dieser Token zur Belohnung beiträgt. PPO sorgt mittels Clipping dafür, dass selbst bei hohen Unterschieden in den wahrscheinlichen Aktionen, die Policy-Updates moderat bleiben. Group Relative Policy Optimization (GRPO) ist ein Ansatz, der auf PPO aufbaut, sich aber insbesondere durch die Gruppenbetrachtung von Antworten auszeichnet.
Anstatt eine Value-Funktion zu lernen, verzichtet GRPO darauf und nutzt stattdessen die Idee, dass mehrere Antworten zu demselben Prompt gruppiert und verglichen werden. So wird die Advantage-Schätzung auf Gruppenebene normalisiert. Diese Gruppennormalisierung stabilisiert den Lernprozess, da durch Mittelwert- und Standardabweichungsberechnungen der Vorteil je Antwortkontext relativ zur Gruppe skaliert wird. GRPO bietet somit eine elegante Lösung für das Credit Assignment Problem, ohne zusätzlich eine aufwendige Value-Funktion lernen zu müssen. Weiterhin beinhaltet GRPO eine KL-Divergenz-Strafe, die dazu führt, dass sich das Modell nicht zu stark von einer Referenzpolicy entfernt.
Das bewahrt das Modell davor, bereits erworbenes Wissen zu verlieren oder unbrauchbare Politiken zu entwickeln. Diese Regularisierung ist in vielen modernen Reinforcement-Learning-Algorithmen von zentraler Bedeutung, um übermäßigen Policy-Drift zu verhindern. Die Vereinfachung des Trainings durch Wegfall des Value-Netzwerks bedeutet, dass GRPO weniger Speicherressourcen benötigt und dabei schneller trainiert werden kann, was insbesondere bei großen LLMs sowie komplexen oder langsamen Value-Modellen von großem Vorteil ist. Gleichzeitig sorgt der gruppenbasierte Ansatz für eine bessere Stabilität durch Ausnutzung des Kontextes mehrerer Antworten auf einen Prompt. Um die Bedeutung solcher Algorithmen einzuordnen, lohnt sich ein Blick in die Praxis.
Moderne Anwendungen mit Sprachmodellen erfordern eine kontinuierliche Anpassung an menschliche Präferenzen, diverse Stilistiken und sicherheitsrelevante Vorgaben. Reinforcement-Learning-Methoden wie PPO und GRPO ermöglichen es, bereits vortrainierte Modelle gezielt weiter zu entwickeln, um dieses Niveau an Spezialisierung passgenau zu erreichen. Beispiele sind Chatbots mit natürlicherem Sprachverhalten, automatisierte Antwortsysteme oder kreative Textgenerierung, bei denen die Kontrolle der Qualität und Zielgerichtetheit von großer Bedeutung ist. Darüber hinaus gewinnen solche Verfahren in der Forschung an Bedeutung, da sie eine Möglichkeit bieten, von einfachen Belohnungssignalen auf komplexe und abstrakte Qualitätsmerkmale zu schließen. So kann man nicht nur technisch definierte Faktenwissen integrieren, sondern auch subjektive Präferenzen wie „Höflichkeit“, „Kohärenz“ oder „Kreativität“ verbessern.
Die mathematische Eleganz von PPO und GRPO spiegelt sich in ihrer Balance zwischen explorativen Anpassungen und der Vermeidung von extremen Policy-Sprüngen wider. Dadurch basiert der Lernerfolg nicht länger auf unkontrollierten und potenziell zerstörerischen Veränderungen, sondern folgt einer kontrollierten Schrittfolge, die stabilen Fortschritt sicherstellt. Die Kombination aus geschicktem Vorteilsschätzer, Clipping-Mechanismen und Gruppenanalyseposition macht diese Methoden leistungsfähige Werkzeuge im Arsenal moderner KI-Forschung. Abschließend lässt sich sagen, dass sowohl PPO als auch GRPO zentrale Technologien für die zeitgemäße Feinanpassung von großen Sprachmodellen darstellen. Während PPO die bewährte Grundlage für stabileres Policy-Gradient-Learning liefert, optimiert GRPO den Trainingsprozess, indem es den Bedarf an Value-Funktionen eliminiert und Antwortgruppen als Basis für den Vorteil nutzt.
Die zunehmende Integration solcher Algorithmen in industrielle Anwendungen zeigt zudem das große Potenzial und die kontinuierliche Weiterentwicklung dieses Forschungsfeldes. Die Beherrschung und Anwendung dieser Algorithmen eröffnet enorme Chancen für die Verbesserung leistungsfähiger Sprachmodelle und lässt zukünftige KI-Systeme noch hilfreicher und menschenorientierter agieren. Für Entwickler, Forscher und Anwender gilt es, diese Technologien weiter zu erforschen, zu optimieren und im Sinne sicherer sowie leistungsfähiger KI-Systeme einzusetzen.