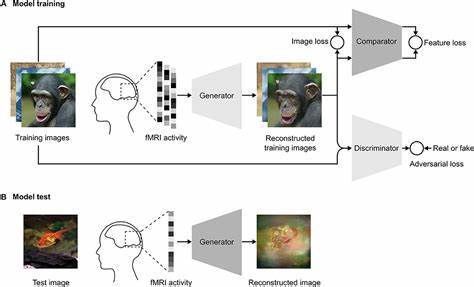
Die Rekonstruktion visueller Bilder direkt aus der Gehirnaktivität gilt als eine der faszinierendsten Herausforderungen der modernen Neurowissenschaft und Künstlichen Intelligenz. Dabei geht es darum, jene Bilder sichtbar zu machen, die Menschen in ihrem Gehirn wahrnehmen oder sich vorstellen – und zwar ausschließlich basierend auf den neuronalen Signalen, die bei der visuelle Verarbeitung oder inneren Vorstellung eines Bildes entstehen. Als wegweisender Ansatz hat sich in den letzten Jahren die Nutzung von Deep Neural Networks (DNNs) und generativen Modellen gezeigt, die latent-kodierte Repräsentationen der visuellen Inhalte erzeugen können. Diese Technologien ermöglichen eine immer genauere, detailreichere und subjektivere Rekonstruktion der inneren visuellen Zustände. Die Entwicklung der Bildrekonstruktion aus Gehirnaktivität hat sich von recht einfachen Klassifikationsmethoden hin zu komplexen, hierarchisch aufgebauten Modellen gewandelt.
Ursprünglich wurden neuronale Muster meist nur dazu verwendet, einfache Kategorien von Bildern zu erkennen oder zu unterscheiden. Mit den Fortschritten in den Bereichen maschinelles Lernen, Bildgenerierung und neuronale Kodierung konnten Forscher mittlerweile deutlich komplexere und naturgetreuere Darstellungen visuell erlebter Inhalte gewinnen. Latente Repräsentationen spielen dabei eine zentrale Rolle. Sie dienen als komprimierte, abstrakte Codes, welche die essenziellen visuellen Merkmale in einem hochdimensionalen Raum einfangen. Durch diese komprimierte Form der Daten können generative Modelle frei rekonstruieren, was im Gehirn verarbeitet wird.
Der Einsatz solcher latent-basierter Modelle bringt entscheidende Vorteile. Einerseits kann auf diese Weise eine flexiblere, robustere und detailliertere Rekonstruktion erzielt werden, die subjektive Wahrnehmungseigenheiten besser abbildet. Andererseits erlauben sie eine modulare Architektur, bei der verschiedene Teile des Modells sich auf unterschiedliche Aspekte der visuellen Information spezialisieren. Dies erleichtert nicht nur den Trainingserfolg und die Generalisierbarkeit, sondern unterstützt auch die Zusammensetzung komplexer Szenen aus ihren konstituierenden Elementen. Beispielhaft sind hier Ansätze, die Bildteile getrennt codieren und später zusammenfügen, was die Modellgenauigkeit in realistischen Anwendungsszenarien erhöht.
Trotz der beeindruckenden Fortschritte gibt es aktuell noch wichtige Herausforderungen, die das Forschungsfeld konfrontieren. Eine davon ist die sogenannte Zero-Shot-Generalisation. Dies bedeutet die Fähigkeit eines Modells, visuelle Inhalte zu rekonstruieren, die es während des Trainings noch nie gesehen hat. Viele existierende Systeme arbeiten gut mit bekannten oder ähnlichen Bildtypen, scheitern aber oft bei vollständig neuen, unbekannten Motiven. Hier sind noch weiterführende Studien und größere, vielfältigere Datensätze erforderlich, um die neuronale und algorithmische Anpassungsfähigkeit zu verbessern.
Ein weiterer kritischer Punkt betrifft die exakte Modellierung der komplexen, subjektiven Aspekte visueller Wahrnehmung. Das menschliche Seherlebnis wird nicht nur durch die reinen Bildinformationen bestimmt, sondern auch durch kontextuelle Faktoren, Erinnerungen, Emotionen und individuelle Unterschiede in der neuronalen Verarbeitung. Die Integration dieser über das rein Bildhafte hinausgehenden Dimensionen in rekonstruierende Modelle stellt eine enorme wissenschaftliche und technische Herausforderung dar, eröffnet jedoch gleichzeitig das Potenzial für deutlich tiefere Einsichten in die menschliche Kognition. Die Bedeutung umfangreicher, qualitativ hochwertiger und vielfältiger Datensätze stellt eine weitere fundamentale Voraussetzung für den Fortschritt dar. Gehirnscans wie fMRT, EEG oder invasive Elektrophysiologie liefern jedem für sich wichtige, aber teilweise begrenzte Informationen.
Die Kombination multimodaler Datenerhebung und die Nutzung großer Datenbanken mit vielfältigen visuellen Stimuli sind entscheidend, um robuste und generalisierbare Modelle zu entwickeln. Parallel müssen auch die Evaluationskriterien verbessert werden, sodass nicht nur technische Metriken wie Pixelgenauigkeit oder Rekonstruktionsfehler herangezogen werden, sondern auch menschliche Wahrnehmungsurteile berücksichtigt werden, um die Relevanz der Rekonstruktionen für das subjektive Erleben zu garantieren. Neben rein wissenschaftlichen Fragestellungen wirft die visuelle Bildrekonstruktion aus Gehirnaktivität auch bedeutende ethische und gesellschaftliche Fragen auf. Die Möglichkeit, private visuelle Eindrücke sichtbar zu machen, berührt fundamental Grundrechte auf Denken, Privatsphäre und persönliche Freiheit. Die Sicherstellung von informierter Zustimmung bei der Datenerhebung, der Schutz vor Missbrauch der Technologie und der verantwortungsvolle Umgang mit sensiblen Informationen sind zentrale Anliegen.
Die Forschungsgemeinschaft ist in der Pflicht, transparent über Risiken zu informieren und Richtlinien zu entwickeln, die eine ethische Nutzung gewährleisten. Die Anwendungsgebiete der visuellen Bildrekonstruktion sind vielfältig und reichen von der klinischen Diagnostik bis hin zu innovativen Schnittstellen zwischen Mensch und Maschine. In der Medizin können solche Technologien helfen, visuelle Funktionseinbußen oder Wahrnehmungsstörungen besser zu verstehen und zu behandeln. In der Neuropsychologie bieten sie neue Messinstrumente, um visuelle Vorstellungen und Erinnerungen objektiv zu erfassen. Besonders spannend sind die Perspektiven für Brain-Machine-Interfaces (BMIs), mit denen Menschen mit Bewegungseinschränkungen oder Sprachverlust durch direkte Kommunikation mit Computern unterstützt werden können, indem innere Bilder in externe visuelle Darstellungen übersetzt werden.