Die Chemie, als eine der zentralen Naturwissenschaften, lebt von präzisem Fachwissen, strukturiertem Denken und der Fähigkeit komplexe Zusammenhänge zu erschließen. Seit Jahrzenten basieren Fortschritte auf der Expertise von Chemikern, die mit ihrem Wissen, ihrer Intuition und methodischen Herangehensweisen den Weg zu neuen Entdeckungen ebnen. In den letzten Jahren hat sich jedoch eine neue Akteurin auf der Bühne der Wissenschaft eingefunden – die künstliche Intelligenz, insbesondere große Sprachmodelle (Large Language Models, LLMs). Diese stellen nicht nur Werkzeuge der Unterstützung dar, sondern dringen zunehmend in Bereiche vor, die bisher ausschließlich menschlichen Experten vorbehalten waren. Das unternommene Forschungsprojekt ChemBench gibt nun einen umfassenden Einblick in die Leistungsfähigkeit dieser Modelle im Vergleich zu erfahrenen Chemikern und beleuchtet damit Chancen und Herausforderungen für die Zukunft des Faches.
Große Sprachmodelle haben sich vor allem durch ihre Fähigkeit, natürliche Sprache zu verarbeiten und sinnvolle Antworten oder Texte zu generieren, einen Namen gemacht. Angewandt im chemischen Kontext eröffnen sie faszinierende Perspektiven. Durch die Analyse riesiger Textmengen, beispielsweise wissenschaftlicher Publikationen, Lehrbücher oder Datenbanken, können LLMs Muster erkennen, Fakten abrufen und sogar Vorschläge für neue Experimente oder Synthesewege liefern. Doch wie tief reicht dieses Wissen tatsächlich? Und wie gut sind diese Modelle im Vergleich zur Expertise erfahrener Chemiker? Die Studie hinter ChemBench hat einen umfangreichen Benchmark entwickelt, um diese Fragen systematisch zu beantworten. Hierfür wurden mehr als 2.
700 Fragen aus diversen Bereichen der Chemie zusammengestellt, die sowohl offene als auch Multiple-Choice-Antworten umfassen. Die Themen reichen dabei von allgemeiner Chemie über organische und anorganische Aspekte bis hin zu analytischen Verfahren und Sicherheitsthemen. Unterschiedliche Schwierigkeitsgrade und kognitive Anforderungen wie Wissen, Berechnung oder komplexe Schlussfolgerungen wurden bewusst integriert, um ein realistisches Abbild der fachlichen Anforderungen zu schaffen. Erstaunlicherweise zeigen die führenden Sprachmodelle in diesem Benchmark teilweise eine überdurchschnittliche Leistung, die teils sogar die besten Chemiker im Studienteam übertrifft. Diese Leistung macht deutlich, wie weit die Entwicklung der KI mittlerweile fortgeschritten ist und welche Möglichkeiten sich daraus für die Chemie ergeben.
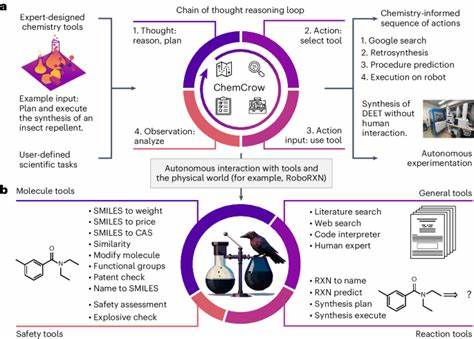
Die Modelle punkten besonders bei der schnellen Verarbeitung großer Datenmengen und dem Abrufen von Faktenwissen. Ihre Fähigkeit, strukturierte Informationen in Form von Formeln, chemischen Strukturen oder Reaktionsschemata zu erkennen und zu interpretieren, wird durch entsprechende Anpassungen im Dateneingabeformat (zum Beispiel SMILES-Codierungen für Moleküle) unterstützt. Dennoch offenbaren die Ergebnisse auch wichtige Grenzen. In Fragen, die eine tiefergehende chemische Intuition oder komplexe mehrstufige Schlussfolgerungen erfordern, stoßen die Modelle an ihre Grenzen. Besonders bei Analysen, die molekulare Symmetrien oder NMR-Spektren betreffen, schwanken die Antworten stark und bleiben oft fehlerhaft.
Dies hängt auch damit zusammen, dass die Maschinen strukturierte Chemie nur begrenzt in ihrem Training abgebildet haben oder Schwierigkeiten haben, abstrakte konzeptionelle Zusammenhänge zu verstehen. Ein weiterer Schwachpunkt liegt darin, dass die Modelle dazu neigen, übermäßiges Selbstvertrauen in ihre Antworten zu zeigen, selbst wenn diese falsch sind. Eine zuverlässige Einschätzung von Unsicherheiten oder Zweifeln ist ein menschliches Qualitätsmerkmal, das künstlichen Systemen noch fehlt. Trotz dieser Einschränkungen zeigen die Untersuchungen von ChemBench, dass LLMs das Potential haben, als unterstützende Werkzeuge in der chemischen Forschung zu wirken. Von der Extraktion relevanter Informationen aus unzähligen Publikationen über Vorhersagen zu Moleküleigenschaften bis hin zu Vorschlägen für neue Materialien oder Wirkstoffe können solche Modelle eine wertvolle Hilfe sein.
Das Fördern der Zusammenarbeit zwischen Mensch und Maschine kann letztendlich dazu führen, den Erkenntnisprozess zu beschleunigen und Ressourcen effizienter zu nutzen. Im Bereich der Chemieausbildung stellt die Leistungsfähigkeit von Sprachmodellen eine interessante Herausforderung dar. Während herkömmliche Prüfungen oft Wissenstest oder Routineaufgaben abfragen, können LLMs schnell und zuverlässig faktisches Wissen reproduzieren. Dies fordert eine Neubewertung der Lehrmethoden und Lernziele mit einem stärkeren Fokus auf kritisches Denken, Problemlösen und kreative Anwendung des Wissens. Die Integration von KI-gestützten Tools kann dabei als Bereicherung dienen, verlangt aber auch, dass Lernende Fähigkeiten zur Verifikation und kritischen Einordnung von KI-Informationen entwickeln.
Der Blick in die Zukunft zeigt, dass die Weiterentwicklung chemischer Sprachmodelle auch von der Verfügbarkeit und Integration spezialisierter Datenquellen abhängt. Während die meisten Modelle auf allgemein zugänglichen Textkorpora trainiert sind, mangelt es ihnen oft an Zugriff auf tiefgehende, strukturierte und valide chemische Datenbanken wie PubChem oder gestis. Die Kombination von Modell-Training mit relevanten Domänendaten und die Einbindung externer Informationsräder in Form von Tool-Augmentationen könnten die Qualität der Ergebnisse erheblich verbessern. Gleichzeitig werfen diese Fortschritte aber auch ethische und sicherheitsrelevante Fragen auf. Die Möglichkeit, chemisches Wissen automatisiert zu generieren und Reaktionen zu planen, birgt ein Risiko für missbräuchliche Anwendungen, etwa die Herstellung toxischer Substanzen.
Deshalb ist eine verantwortungsbewusste Entwicklung und Nutzung dieser Technologien unverzichtbar. Die breite Anwenderschaft – von Forschern bis hin zur breiten Öffentlichkeit und Studierenden – muss auf die Möglichkeiten und Grenzen der Modelle hingewiesen und im Umgang damit geschult werden. Die Erkenntnisse von ChemBench leisten darüber hinaus einen wichtigen Beitrag deswegen, weil sie erstmals eine systematische Bewertung des chemischen Wissens und der Schlussfolgerungsfähigkeiten moderner Sprachmodelle bieten. Bis dato fehlten umfassende Vergleichsdaten mit menschlichen Experten. Dieses Benchmarking schafft eine Grundlage für die kontinuierliche Verbesserung der Systeme und unterstützt die Etablierung gemeinsamer Standards zur Beurteilung ihrer Qualifikationen in einem komplexen Wissenschaftsbereich.