In der Welt der Informatik sind Datenstrukturen fundamental, wenn es darum geht, große Datenmengen effizient zu speichern und schnell abzufragen. Eine besondere Herausforderung stellt dabei die Speicherung von umfangreichen Wortlisten dar, wie sie beispielsweise in Wörterbüchern, Suchmaschinen oder Textverarbeitungsprogrammen benötigt werden. Eine elegante Lösung für dieses Problem bietet der deterministische azyklische endliche Zustandsautomat, kurz DAFSA. In diesem Text soll dieser spezielle Automat genauer betrachtet werden – von seiner Definition über seine Unterschiede zu ähnlichen Datenstrukturen bis hin zu seinen praktischen Vorteilen und Anwendungsgebieten. Ein deterministischer azyklischer endlicher Zustandsautomat ist ein spezieller Typ eines endlichen Zustandsautomaten, der deterministisch und azyklisch aufgebaut ist.
Die Determiniertheit bedeutet dabei, dass vom aktuellen Zustand aus für jedes mögliche Eingabesymbol genau ein Übergang definiert ist – eine Eigenschaft, die sicherstellt, dass das System jederzeit eindeutig auf ein Symbol reagieren kann. Die Azyklizität wiederum verhindert, dass der Automat Zyklen besitzt, was wiederum impliziert, dass er nur eine endliche Menge von Zeichenketten erkennt. Dies macht den DAFSA besonders geeignet, um eine bestimmte, abgeschlossene Sammlung von Wörtern darzustellen. Strukturell kann man sich einen DAFSA als einen gerichteten azyklischen Graphen mit genau einem Startknoten vorstellen, bei dem jeder Übergang mit einem einzelnen Buchstaben oder Symbol beschriftet ist. Pfade von diesem Startknoten zu sogenannten Endknoten entsprechen genau den Wörtern oder Zeichenketten, die der Automat erkennt.
Weil keine Zyklen vorhanden sind, ist jeder Pfad endlich und repräsentiert eine komplette, gespeicherte Wortfolge. Ein wichtiger Punkt bei der Betrachtung von DAFSA ist ihre Beziehung zu anderen Datenstrukturen, insbesondere zu Tries. Tries sind ebenfalls ein bewährtes Mittel, um Wortlisten abzuspeichern und Anfragen über deren Inhalte zu ermöglichen. Sie sind Bäume, die gemeinsame Präfixe von Wörtern bündeln – das bedeutet, dass gleiche Anfangsteile verschiedener Wörter nur einmal gespeichert werden. Diese Redundanzreduktion ist oft schon sehr effektiv.
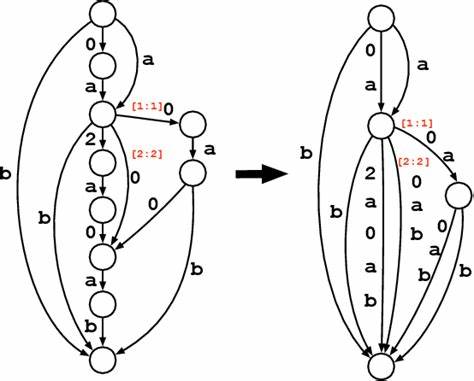
Dennoch betreibt ein Trie keine Reduzierung von Suffixen oder anderen inneren Teilstrings. Hier setzt der DAFSA an, der nicht nur gemeinsame Präfixe, sondern auch gemeinsame Suffixe und sogar Zwischenabschnitte effizient zusammenfasst. Dadurch verbraucht ein DAFSA, besonders bei umfangreichen und komplexen Wortsammlungen, oft deutlich weniger Speicherplatz als ein Trie. Um dies zu verdeutlichen, lässt sich das Beispiel der vier englischen Wörter „tap“, „taps“, „top“ und „tops“ heranziehen. Ein Trie, der diese Wörter speichert, besitzt für jedes Präfix und für jedes komplette Wort mit Endemarkierung einen eigenen Knoten, was insgesamt 12 Knoten ergeben kann.
Ein DAFSA hingegen kann dieselbe Menge von Wörtern mit nur sechs Knoten darstellen. Dabei werden Pfade so verschmolzen, dass sowohl gemeinsame Anfangsbuchstaben als auch gemeinsame Endungen nur einmal gespeichert werden. Durch diese Verbindung können DAFSAs Speicheranforderungen erheblich reduziert werden, was sie für Anwendungen mit großen Wortlisten besonders attraktiv macht. Die Effizienz eines DAFSA zeigt sich nicht nur in der Speicherersparnis, sondern auch in der Geschwindigkeit bei Abfragen. Da der Automat deterministisch ist, kann in linearer Zeit zur Länge der Abfragestrings entschieden werden, ob ein bestimmtes Wort zur gespeicherten Menge gehört oder nicht.
Dieser Geschwindigkeitsvorteil macht den DAFSA zu einer bevorzugten Datenstruktur beispielsweise in Suchmaschinen, Autovervollständigungsmechanismen oder anderen Systemen, in denen hohe Performance bei Wortabfragen entscheidend ist. Ein Nachteil im Vergleich zum Trie ist jedoch, dass der DAFSA keine direkten Zusatzinformationen mit einzelnen gespeicherten Wörtern verknüpfen kann, da Endknoten von mehreren Pfaden erreicht werden können. Informationen wie die Häufigkeit eines Wortes oder zusätzliche Metadaten lassen sich also nicht direkt an Pfade binden. Um dieses Problem zu umgehen, können allerdings separate Datenstrukturen mit Indizes verwendet werden, sodass jedes Wort über einen eindeutigen Index referenziert und somit Zusatzinformationen in Arrays oder anderen Strukturen gespeichert werden können. Die Geschichte des DAFSA ist eng mit der Entwicklung verwandter Automaten wie dem Directed Acyclic Word Graph (DAWG) verbunden.
Erste Beschreibungen solcher Strukturen stammen aus den frühen 1980er Jahren. Wissenschaftler wie Blumer, Appel und Jacobsen trugen wesentlich zur theoretischen Fundierung und praktischen Anwendung bei. Im Jahr 2000 wurde der Begriff DAFSA von Daciuk und Kollegen geprägt, die eine algorithmische Methode entwickelten, um solche minimalen Automaten inkrementell zu konstruieren und zu pflegen. Diese Entwicklungen führten zu einer vereinfachten Nutzung und Implementation in zahlreichen Anwendungen. Im praktischen Einsatz finden sich DAFSAs beispielsweise im Bereich der Textverarbeitung, wo große Wortschätze schnell durchsucht werden müssen.
Ebenso profitieren Scrabble-Programme, automatische Rechtschreibkorrekturen und Suchmaschinen von der kompakten Repräsentation großer Wortmengen. Auch in der Bioinformatik können ähnliche Techniken bei der Analyse von Sequenzdaten Anwendung finden. Heute gibt es vielfältige Werkzeuge und Bibliotheken, die eine Implementierung von DAFSAs erleichtern. Neben zahlreichen Forschungspapieren gibt es open-source-Projekte in Programmiersprachen wie Python, welche die Nutzung und Integration in praktische Anwendungen vereinfachen. Durch stetige Weiterentwicklung sind diese Implementationen gut dokumentiert und bieten effiziente, minimal gehaltene Speichermechanismen.
Zusammenfassend ist der deterministische azyklische endliche Zustandsautomat eine äußerst wertvolle Datenstruktur für die Speicherung und Abfrage von endlichen Mengen an Zeichenketten. Seine Fähigkeit, sowohl Präfix- als auch Suffix-Redundanzen zu eliminieren, führt zu erheblicher Speicherersparnis und ermöglicht schnelle Abfrageoperationen. Trotz gewisser Einschränkungen hinsichtlich der Speicherung zusätzlicher Wortinformationen bieten DAFSAs in vielen praktischen Szenarien eine optimale Kombination aus Effizienz und Funktionalität. Für Entwickler, die mit großen Lexika oder Wortlisten arbeiten, stellt der DAFSA somit eine empfehlenswerte Wahl dar, um Speicherplatz zu sparen und gleichzeitig hohe Performance zu gewährleisten.