Git ist eines der beliebtesten Versionskontrollsysteme der Welt und wird von Entwicklern aller Erfahrungsstufen eingesetzt. Trotz seiner Verbreitung gibt es viele technische Details, die auch erfahrene Anwender gelegentlich überraschen. Eines dieser Konzepte ist die klare Trennung zwischen Git Commits und den Git Trees, die im Repository verwaltet werden. Dieses Prinzip ist grundlegend für das Verständnis der Arbeitsweise von Git und kann dabei helfen, den Umgang mit großen und komplexen Repositories effizienter zu gestalten. Ein Commit in Git ist im Wesentlichen ein Schnappschuss oder eine Momentaufnahme eines Projekts zu einem bestimmten Zeitpunkt.
Doch entgegen der weit verbreiteten Annahme enthält der Commit nicht direkt die Dateien eines Projekts. Stattdessen verweist ein Commit auf einen Git Tree, welcher die Baumstruktur der Dateien und Verzeichnisse zu jenem Zeitpunkt repräsentiert. Diese Trennung ist ein grundlegendes Designkonzept von Git, das es erlaubt, Speicherplatz zu sparen und den Umgang mit Änderungen zu optimieren. Die meisten Entwickler verbinden beim Begriff "Commit" vor allem die Änderungshistorie oder die Reihenfolge von Änderungen mit einem Repository. Tatsächlich ist der Commit-Objekt ein Zeiger auf den Tree, der wiederum aus Blobs besteht – den tatsächlichen Dateninhalt der Dateien.
Diese Blobs sind selbst adressiert mittels eines Hashs, was die Einzigartigkeit und Verifizierbarkeit immens erhöht. Warum ist diese Trennung zwischen Commits und Trees so wichtig? Ein Hauptgrund ist die Effizienz in der Speicherung und Übertragung von Daten. Wenn sich der Inhalt eines Projekts nahezu nicht ändert, aber Änderungen der Commit-Historie auftreten – etwa beim Neustrukturieren der Historie oder Wechsel des Remotes – muss nicht die gesamte Datenbasis neu übertragen oder gespeichert werden. Nur die Commit-Objekte benötigen eine Aktualisierung. Nehmen wir als Beispiel eine große Software wie Firefox, deren Quellcode über Jahre hinweg gewachsen ist und mehrere Gigabyte an Daten umfasst.
Sollte das Projekt auf ein neues Git-Repository umziehen und dabei eine komplett neue Commit-Historie erhalten, wird man zunächst befürchten, das gesamte Datenpaket erneut herunterladen zu müssen. Doch die Realität zeigt, dass viele der Dateien und Verzeichnisse unverändert bleiben. Daher existieren viele der Bäume und Blobs schon lokal und müssen nicht erneut übertragen werden. Lediglich die Commit-Objekte, die sich auf die neue Historie beziehen, müssen hinzugefügt werden. Diese Eigenschaft macht Git zum sogenannten content-adressierten Speicher.
Jedes Objekt in Git ist eindeutig identifizierbar durch seinen SHA-1 oder SHA-256 Hash, der auf dem Inhalt basiert. Wenn sich der Inhalt ändert, ändert sich auch der Hash – andernfalls bleibt er identisch. So kann Git identifizieren, welche Teile eines Repositories bereits vorhanden sind und welche neu heruntergeladen werden müssen. Dieser Mechanismus wurde von Chris Siebenmann in Bezug auf den Wechsel des Firefox-Quellcodes zu einem neuen Git-Repository besonders treffend erläutert. Obwohl sich die Commit-IDs komplett ändern, da eine neue Historie aufgebaut wurde, bleiben die zugrunde liegenden Bäume und Blobs oft dieselben.
Wenn man das neue Repository als zusätzlichen Remote in einer bestehenden lokalen Kopie hinzufügt und von dort zieht, müssen die meisten Daten nicht erneut übertragen werden, sondern nur die Commit-Objekte und eventuell einige neue Tree-Objekte. Diese Praxis kann insbesondere bei der Arbeit mit sehr großen Repositories Zeit und Bandbreite sparen. Entwickler werden so in die Lage versetzt, lokale Änderungen leichter in das neue Repository einzupflegen, beispielsweise durch Rebase, ohne den Mehraufwand eines kompletten Neuklons. Gleichzeitig bleibt der Zugriff auf den Quellcode dank der effizienten Speicherung und vernetzten Objekthistorie schnell und ressourcenschonend. Die Unterscheidung zwischen Commit und Tree kann auch beim Verständnis von Tools wie "git rebase" helfen.
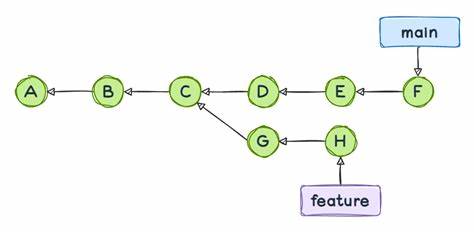
Rebase modifiziert die Commit-Geschichte, indem es die Commits quasi neu schreibt. Dabei bleiben allerdings viele der zugrundeliegenden Tree-Objekte erhalten, solange der tatsächliche Zustand der Dateien unverändert bleibt. Dies verdeutlicht, dass Commits als strukturierende Metadaten fungieren, die auf den eigentlichen Dateibaum verweisen, anstatt ihn direkt zu enthalten. Für Entwickler, die mit Git größere Projekte verwalten oder Projekte über mehrere Repositories synchronisieren, sind diese Erkenntnisse Gold wert. Sie eröffnen Möglichkeiten, Daten effizienter zu handhaben und übertragen.
Auch lassen sich Missverständnisse vermeiden, warum ein vermeintlich „neuer“ Klon gar nicht so groß sein muss, wie erwartet, oder warum lokale Änderungen sich leichter in eine neue Historie einbindet lassen, selbst wenn die Commit-IDs sich stark unterscheiden. Zusammenfassend lässt sich sagen, dass das Verständnis der Trennung von Git Commits und Git Trees für einen Profi eine wichtige Grundlage schafft, um Git als Werkzeug vollumfänglich zu nutzen. Es ist ein Beleg für die ausgeklügelte Architektur von Git, die auf Wiederverwendung und Effizienz setzt. Entwickler profitieren dadurch in vielerlei Hinsicht: sie sparen Bandbreite, sie arbeiten schneller und können komplexe Repository-Historien besser verstehen und manipulieren. Git wird auch in Zukunft eine Schlüsselrolle bei der Softwareentwicklung spielen.
Je tiefer Entwickler in die Konzepte eintauchen, desto größer wird ihr Vorteil. Die Trennung von Commits und Trees ist dabei ein Schlüsselprinzip, das Git unabhängig von der Größe des Projekts schnell, stabil und zuverlässig macht. Wer diese Dynamik versteht, ist einen Schritt näher daran, Git wirklich zu meistern und das Maximum aus seinen Anwendungen herauszuholen.