In der heutigen digitalen Ära sind elektronische Bücher oder eBooks nicht mehr aus dem Alltag vieler Leser und Verlage wegzudenken. Das ePub-Format hat sich als einer der führenden Standards für elektronische Bücher etabliert und bietet dabei Flexibilität und Vielseitigkeit für Bildschirmanzeige und Inhaltshandhabung. Trotz der weit verbreiteten Nutzung von ePub-Dateien besteht oft die Herausforderung, diese gründlich zu analysieren oder zu validieren, besonders wenn man Probleme bei der Darstellung oder Metadatenverwaltung hat. Hier kommt epub-utils ins Spiel – eine spezialisierte Python-Bibliothek mit zugehörigem Kommandozeilen-Interface, die das Inspektieren von ePub-Dateien vom Terminal aus ermöglicht und so Entwicklern und Anwendern des elektronischen Buchformats eine enorme Erleichterung bietet. epub-utils ist ein Open-Source-Projekt auf GitHub und kombiniert die Leichtigkeit von Python mit einer benutzerfreundlichen Konsole zur schnellen Analyse von ePub-Containern.
Es unterstützt wesentliche Funktionen wie das Parsen und Validieren der Container- und Package-Dateien von ePub, das Extrahieren von Metadaten sowie die Anzeige und Bearbeitung von Inhaltsverzeichnissen und Manifesten. Der Fokus liegt dabei auf einer klaren und aussagekräftigen Ausgabe, die durch Syntax-Hervorhebung, Rohdatenansichten oder gut strukturierte Formatierungen verschiedene Nutzerbedürfnisse berücksichtigt. Im Kern nutzt epub-utils die in Python geschriebenen Komponenten, um die Struktur einer ePub-Datei zu erkennen und ihre internen XML-Dateien darzustellen. Die ePub-Datei an sich ist ja im Grunde ein ZIP-Archiv mit einer spezifischen Verzeichnis- und Dateistruktur, die Containerinformationen, Package-Daten (OPF-Dateien), Navigationselemente (wie NCX oder nav.xhtml), sowie die eigentlichen Inhalte und Ressourcen einbettet.
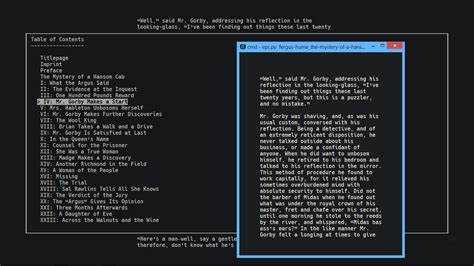
Die Bibliothek erlaubt es, diese einzelnen Elemente programmgesteuert oder über die Kommandozeile sichtbar zu machen. Mit nur wenigen Befehlen können Nutzer Containerinformationen ausgeben, das Inhaltsverzeichnis durchsuchen oder Metadaten wie Titel, Autor und Identifikatoren einsehen – das alles wahlweise mit farblicher Syntaxunterstützung oder als Rohdaten. Die Einfachheit und Effizienz von epub-utils zeigt sich besonders im Kommandozeilen-Interface. Nach der Installation per pip reicht ein einfacher Aufruf mit dem Dateipfad zum ePub und einem entsprechenden Befehl, etwa container, package oder metadata, um tiefgehende Einblicke zu erhalten. Zugleich bietet das Tool verschiedene Ausgabeoptionen an, darunter rohe Darstellung, XML-Format mit Hervorhebung oder sogar menschenlesbare Key-Value-Paare.
Für den Umgang mit den tatsächlichen Buchinhalten lässt sich darüber hinaus eine manuelle Auswahl einzelner Manifest-Elemente treffen und deren Text oder Rohdaten analysieren. Diese Flexibilität ist besonders für Entwickler interessant, die automatisierte Prüfungen, Qualitätssicherungen oder auch eigene eBook-Anwendungen bauen möchten. Die Offenheit von epub-utils erstreckt sich auch auf moderne ePub-Standards. Die Bibliothek unterstützt vollständig die Spezifikationen von EPUB 2.0.
1 und EPUB 3.0+, inklusive der jüngsten EPUB 3.3-Version. Dadurch sind nicht nur einfache Textbücher, sondern auch komplexere Publikationen mit HTML5-Inhalten, multimedialen Überlagerungen, Skripten und barrierefreien Navigationen abdeckbar. Das macht epub-utils zum idealen Werkzeug für verschiedene Anwendungsfälle im digitalen Publishing.
So profitieren Verleger von einer validen Kontrolle und Lesbarkeit ihrer Werke, während Entwickler von stabilen, standardkonformen ePub-Komponenten profitieren. Ein weiterer großer Vorteil ist die Integration von Dublin Core Metadaten und Open Packaging Format Standards. Diese gewährleisten präzise und strukturierte Daten zu Büchern, die für Katalogisierung, Suche oder semantische Anwendungen unerlässlich sind. epub-utils kann diese Metadaten extrahieren, formatieren und übersichtlich darstellen, was insbesondere bei großen eBook-Sammlungen oder bei der Entwicklung von Bibliothekssoftware nützlich ist. So lassen sich etwa Titel, Autoren, Herausgeber und eindeutige Kennungen einfach abrufen und weiterverarbeiten.
Ebenso nützlich ist die Fähigkeit, einzelne Dateien aus dem ePub-Archiv direkt zu betrachten. Nutzer können eine Liste aller Dateien abrufen, manifestierte Contents identifizieren und anschließend gezielt auf HTML, CSS oder sogar Bilder zugreifen. Die Ausgabe unterstützt dabei unterschiedliche Formate, beispielsweise mit oder ohne XML-Hervorhebung, als reiner Text oder als strukturierte XML-Darstellung. Dies erleichtert das Debugging oder die Anpassung von eBooks erheblich, da alle Inhalte jederzeit transparent einsehbar sind. Wer epub-utils nicht nur als Kommandozeilentool, sondern auch programmatisch verwenden möchte, erhält eine gut dokumentierte Python-Bibliothek mit klaren APIs.
Dabei steht das Document-Objekt im Fokus, welches ein ePub-Dokument symbolisiert und Zugriff auf dessen Container, Package und Inhaltsverzeichnis erlaubt. Diese strukturierte Modellierung macht den Umgang mit ePub-Dateien intuitiv und solide, wodurch sich automatisierte Abläufe, Analysen oder komplexe Manipulationen einfacher realisieren lassen. Auf technischer Ebene legt epub-utils großen Wert auf Kompatibilität und zuverlässige Umsetzung etablierter Industriestandards. Die Entwickler fügen regelmäßig Tests und Updates hinzu, um Abweichungen zu minimieren und auch mit teils fehlerhaften oder ungewöhnlichen ePub-Dateien fertig zu werden. Das Projekt setzt moderne Python-Werkzeuge ein und bindet zahlreiche Funktionen direkt in eine benutzerfreundliche CLI ein, wodurch sich der Workflow spürbar verbessert.
Unterstützt wird auch die Option, die XML-Ausgabe hübsch und übersichtlich zu formatieren, um die Lesbarkeit zu erhöhen. Der Umgang mit ePub-Formaten ist häufig komplex und gerade für Nicht-Entwickler schwierig zu durchschauen. In der Praxis entstehen viele Fragestellungen etwa zur Validität eines Buches, zur Struktur des Inhalts oder zur korrekten Einbindung von Medien. epub-utils bietet Abhilfe, indem es direkten und schnellen Zugang zu den inneren Elementen erlaubt. Für wissenschaftliche Bibliotheken, Verlagshäuser, technische Supportteams oder auch eBook-Sammler ist dies eine große Hilfe.
Zudem erleichtert das Tool die Entwicklung neuer eBook-Reader, Konverter und Analysewerkzeuge wesentlich. Open Source, aktiv weiterentwickelt und mit einer aktiven Community gestützt, ist epub-utils ein Leuchtturmprojekt für alle, die professionell oder hobbymäßig elektronische Bücher verwalten oder erforschen möchten. Die einfache Installation mittels pip, die umfassende Dokumentation und Beispiele machen den Einstieg zudem unkompliziert. Serverseitige Automatisierungen oder lokale Skripte profitieren gleichermaßen vom modernen und effizienten Ansatz, der die ePub-Dateien in all ihren Facetten zugänglich macht. Insgesamt stellt epub-utils ein unverzichtbares Werkzeug im Ökosystem der digitalen Publikation dar.
Es verbindet das mächtige Python-Ökosystem mit komfortabler und übersichtlicher Kommandozeilenbedienung und deckt dabei den gesamten Lebenszyklus einer ePub-Analyse ab. Ob es um das Erkennen von Fehlern, das Extrahieren von Inhalten, das Formatieren von Metadaten oder das Entwickeln eigener Publishing-Lösungen geht, epub-utils stellt stets eine zuverlässige Grundlage bereit. Wer mit ePub-Dateien arbeitet und eine flexible, zugleich robuste Unterstützung braucht, findet hier ein äußerst empfehlenswertes Toolset, das sich schnell und gezielt in den Arbeitsalltag integrieren lässt.