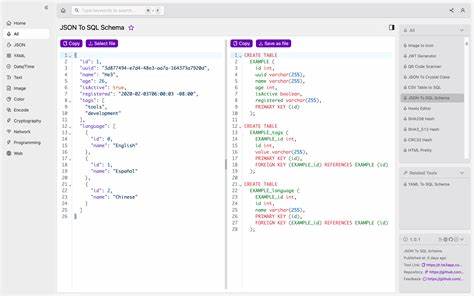
Die digitale Transformation zwingt Unternehmen zunehmend dazu, große Datenmengen effizient und strukturiert zu verwalten. In diesem Kontext gewinnt die Umwandlung von JSON Schema in SQL Data Definition Language (DDL) eine besondere Bedeutung. JSON Schema ist ein weit verbreitetes Format zur Beschreibung der Struktur von JSON-Daten, während SQL DDL zur Definition der Struktur relationaler Datenbanken verwendet wird. Das Konvertieren von JSON Schema in SQL DDL ermöglicht eine reibungslose Migration von schemalosen oder semi-strukturierten Daten hin zu strukturierten relationalen Datenbanken und bietet zahlreiche Vorteile für Entwickler und Datenarchitekten. Die Grundlage dieser Transformation liegt in der logischen Zuordnung der JSON Schema-Typen und -Strukturen zu relationalen Datenbankkonzepten.
Das Prinzip beruht auf einer automatisierten Generierung von SQL-Skripten, die Tabellen, Spalten, Datentypen, Primär- und Fremdschlüssel sowie weitere Constraints wie CHECK-Bedingungen und Standardwerte definieren. Durch die Nutzung spezieller Libraries, z.B. der Open-Source-Lösung „json-schema-to-sql“ entwickelt von Vasil Velikov, wird diese Umwandlung flexibel und effizient umgesetzt. Ein wesentlicher Vorteil der Verwendung von JSON Schema liegt darin, dass es kompatibel mit modernen Webtechnologien und APIs ist.
Somit können Entwickler unmittelbar das JSON-Format nutzen, welches in Echtzeit-Datenübertragungen vorherrscht, und dieses Schema mit wenigen Anpassungen in relationalen Datenbanken abbilden. Dabei wird sichergestellt, dass die Datenintegrität und Datenstruktur erhalten bleiben, während die Vorteile von SQL-Datenbanken wie Abfrageoptimierung, Datenmanipulation und Transaktionssicherheit weiterhin verfügbar sind. Die Konvertierung respektiert wichtige JSON Schema-Features wie Pflichtfelder, Enum-Werte oder Datentypen und bildet diese angemessen in der relationalen Datenbank ab. So werden etwa erforderliche Felder als Nicht-NULL-Spalten implementiert, Enum-Werte als CHECK-Constraints formuliert, und Datenformate wie UUIDs als geeignete SQL-Datentypen ausgewiesen. Zusätzlich wird die Möglichkeit geboten, erweiterte Annotationen via „x-“-Präfixe einzusetzen, um logische Relationen und Primärschlüssel explizit zu definieren.
Diese Erweiterungen überbrücken die semantische Lücke zwischen JSON Schema und relationalem Modell und erhöhen die Anpassbarkeit der generierten Datenbankschemata. Die Herausforderung im Umgang mit komplexen, verschachtelten Datenstrukturen wird durch die Normalisierung gelöst. Konvertiert man verschachtelte Objekte oder Arrays innerhalb des JSON Schemas, erzeugt die Library separate Tabellen, die durch Fremdschlüssel mit ihren übergeordneten Elementen verbunden sind. Beispielsweise führt ein Array von Objekten innerhalb eines Userschemas zu einer eigenen Tabelle, in der jede Zeile einem einzelnen Element des Arrays entspricht und auf die übergeordnete Tabelle referenziert. Diese Vorgehensweise sichert sowohl Datenkonsistenz als auch Skalierbarkeit der Datenbank.
Der Einsatz moderner Validierungsmechanismen während der Schema-Konvertierung ist ein weiterer Pluspunkt. Die Software prüft syntaktische Korrektheit mit Bibliotheken wie Ajv, ermittelt strukturelle Richtigkeit via Zod und führt letzte semantische Kontrollen durch, unter anderem das Sicherstellen von referenzieller Integrität. Dieses mehrstufige Validierungsverfahren stellt sicher, dass das endgültige SQL DDL frei von Fehlern ist und die Datenbank stabil sowie performant arbeitet. Trotz der zahlreichen Vorteile existieren auch Limitationen. Komplexe Primärschlüssel, sogenannte Composite Keys, werden derzeit noch nicht vollständig unterstützt, da die Implementierung der korrekten Fremdschlüsselverweise in verschachtelten Tabellen zusätzliches Mapping benötigt.
Auch mehrfache verschachtelte Arrays innerhalb von Arrays können aktuell nicht abgehandelt werden, was die Modellierung mancher sehr komplexer Datenstrukturen limitiert. Hier sind zukünftige Weiterentwicklungen und Community-Beiträge gefragt, um die Funktionalität weiter auszubauen. Der modulare Aufbau und die Unterstützung unterschiedlicher SQL-Dialekte wie PostgreSQL und MySQL ermöglichen eine flexible Nutzung des Tools in diversen IT-Umgebungen. Die Voreinstellung für PostgreSQL nutzt moderne Datentypen wie UUID und ENUM, was insbesondere bei der Entwicklung von skalierbaren und performanten Unternehmensanwendungen von Vorteil ist. Durch diese Dialektanpassung lassen sich bestehende Datenbanklandschaften optimal ergänzen und homogenisieren.
Für Entwickler, die mit JSON-basierten APIs arbeiten und den Sprung in relationale Datenbanksysteme wagen wollen, stellt dieser Ansatz einen erheblichen Mehrwert dar. Er verkürzt Entwicklungszeiten, erhöht die Datenqualität und gewährleistet, dass die Datenmodelle konsistent und wartbar bleiben. Auch die Migration vorhandener JSON-Datensammlungen in strukturierte Datenbanken wird durch die automatisierte DDL-Generierung effektiver und weniger fehleranfällig. Zusammengefasst zeigt sich, dass die Konvertierung von JSON Schema in SQL DDL eine wertvolle Brücke zwischen modernen Datenformaten und klassischen relationalen Datenbanksystemen darstellt. Mit der Unterstützung von Validierungsmechanismen, Unterstützung für verschachtelte Strukturen und Anpassungsfähigkeit an unterschiedliche SQL-Dialekte vereinfacht diese Methode den Datenbankentwurf erheblich.
Sie ermöglicht nicht nur die Übernahme bestehender schemaloser oder semi-strukturierter Daten, sondern fördert auch die saubere Definition und Dokumentation komplexer Datenmodelle, die für den langfristigen Betrieb und die Analyse unerlässlich sind. Unternehmen, Entwickler und Datenarchitekten sollten diese Technologie in ihren Werkzeugkasten aufnehmen, um die wachsenden Anforderungen der Datenverwaltung und -migration souverän zu meistern. Die Weiterentwicklung und das Engagement der Open-Source-Community versprechen zudem eine kontinuierliche Verbesserung und Erweiterung dieser innovativen Lösung in den kommenden Jahren.