Die Verarbeitung unstrukturierter Daten stellt Unternehmen und Entwickler seit Langem vor große Herausforderungen. Im Gegensatz zu strukturierten Daten, die in klar definierten Formaten wie Tabellen und Datenbanken organisiert sind, bestehen unstrukturierte Daten aus vielfältigen Quellen und Formaten – darunter Verträge, E-Mails, Rechnungen, handschriftliche Notizen oder multimediale Inhalte. Große Sprachmodelle, auch als Large Language Models (LLMs) bekannt, versprechen, viele dieser Herausforderungen zu lösen. Dennoch sind LLMs noch weit davon entfernt, die sprichwörtliche „Silberkugel“ für die Verarbeitung unstrukturierter Daten zu sein. Ein genauer Blick auf die Gründe zeigt, warum dies so ist und welche Rolle sie zukünftig spielen können.
Die derzeitige Landschaft der Datenverarbeitung beruht überwiegend auf bewährten Systemen, die strukturierte Daten effizient verwalten und analysieren können. Relationale Datenbanken, NoSQL-Systeme und darauf aufbauende ETL-Plattformen (Extract, Transform, Load) bilden das Rückgrat für die meisten datenbasierten Anwendungen. Diese Systeme funktionieren gut, weil der Dateninput klar definiert, standardisiert und stabil bleibt. Wenn jedoch unstrukturierte Daten ins Spiel kommen, ist keine solche Standardisierung vorhanden. Hier liegen die Schwierigkeiten.
LLMs haben als flexibel einsetzbare KI-Modelle großes Potenzial, weil sie menschliche Sprache verstehen und erzeugen können. Sie sind darauf trainiert, große Mengen an Text zu verarbeiten, Zusammenhänge zu erkennen und sogar komplexe Inhalte zu interpretieren. Doch sie stoßen an Grenzen, wenn es um die Verarbeitung spezieller Dokumententypen mit unzähligen Varianten und komplexer geschäftlicher Logik geht. Beispielsweise kann ein einfacher Vertrag von Hunderten verschiedenen Anbietern stammen, die alle unterschiedliche Formate, Begriffe und Strukturen verwenden. LLMs müssen dann nicht nur den Text erkennen, sondern auch eine konsistente Darstellung liefern – ein Prozess, der aktuell sehr kostspielig, langsam und fehleranfällig sein kann.
Ein weiterer wichtiger Punkt ist die „Kontextfenstergröße“ der LLMs. Diese bestimmt, wie viele Informationen das Modell auf einmal verarbeiten kann. Große Dokumente oder Dokumentensets überschreiten häufig dieses Limit, was dazu führt, dass Entwickler komplexe Strategien wie Retrieval-Augmented Generation (RAG) verwenden müssen, um mehrere Datenstücke nacheinander zu verarbeiten und dann zusammenzuführen. Das erhöht die Komplexität und Kosten weiter. Neben den textbasierten Herausforderungen bringt auch die Vielfalt der unstrukturierten Daten Probleme mit sich.
Formulare mit mehrspaltigen Layouts, Tabellen, handschriftlichen Notizen oder interaktiven Elementen wie Checkboxen und Radiobuttons können von unseren digitalen Assistenten nur schwer interpretiert werden. Zwar gibt es Technologien wie OCR (Optical Character Recognition) und Computervision, doch deren Ergebnisse müssen oft noch stark nachbearbeitet werden, bevor eine automatisierte Weiterverarbeitung möglich ist. Eines der größten Probleme bei der Anwendung von LLMs in der Praxis ist die Neigung dieser Modelle zu „Halluzinationen“. Das bedeutet, sie generieren manchmal fehlerhafte oder erfundene Informationen ohne Wahrheitsbezug, was in einem geschäftlichen Umfeld verheerend sein kann. Um diesem Problem zu begegnen, wurden Techniken wie das sogenannte „LLMChallenge“ entwickelt, bei denen zwei Modelle miteinander verglichen werden, um die Genauigkeit zu erhöhen oder fehlerhafte Extraktionen konsequent auszuschließen.
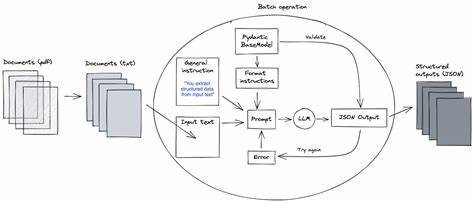
Trotzdem bleibt die Herausforderung bestehen, insbesondere bei Daten, deren Qualität ohnehin niedrig oder sehr variabel ist. Um die Vorteile der etablierten datenverarbeitenden Ökosysteme zu nutzen, versuchen Entwickler heute, Brücken zwischen den unstrukturierten Daten und den traditionellen Tools fürs strukturierte Datenmanagement zu bauen. Das heißt, unstrukturierte Informationen müssen erst in ein festes, standardisiertes Schema gebracht werden, bevor sie in Datenbanken oder Data Warehouses eingespeist werden. Diese Aufgabe verlangt eine sorgfältige Kartierung, die oft viele Iterationen und detailliertes Wissen von Fachexperten erfordert – Wissen, das nicht einfach auf ein Modell übertragen werden kann. Spezialisierte Plattformen wie Unstract bauen darauf auf und bieten dedizierte Werkzeuge zur Schema-Mapping-Entwicklung an, die speziell auf die Nutzung von LLMs zugeschnitten sind.
Mit Funktionen wie „Prompt Studio“ kann man verschiedene Varianten eines Dokuments analysieren und kontrolliert einem einheitlichen JSON-Schema zuordnen. Das erhöht die Konsistenz, erleichtert spätere Auswertungen und gewährleistet, dass die Systeme in der Praxis vertrauenswürdig arbeiten. Dennoch sind solche Plattformen oft weder kostengünstig noch extrem schnell, weshalb sie vor allem für Anwendungsfälle geeignet sind, in denen die Dokumente komplex sind, viele Varianten aufweisen und ein menschliches Eingreifen bisher unvermeidlich war. Für einfachere Fälle, in denen bekannte Formate vorliegen und die Sprache relativ unkompliziert ist, sind traditionell etablierte Technologien wie OCR, NLP und IDP (Intelligent Document Processing) nach wie vor ausreichend und effizient. Ein weiterer wirtschaftlicher Aspekt ist die Skalierbarkeit.
Für Unternehmen mit hohem Volumen unstrukturierter, wertvoller Daten lohnt sich die Investition in moderne Lösungen eher als für Firmen mit gelegentlichen oder sehr individuellen Dokumentenströmen. Wenn der Automationsgrad dadurch signifikant erhöht wird, amortisieren sich die Kosten schneller. Die Weiterentwicklung von Vision-Modellen verspricht in der Zukunft eine Verschmelzung der Analyse von Bild- und Textinformationen in einem Prozess. Solche Modelle könnten direkt mit komplexen Dokumenten umgehen, Grafiken interpretieren, handschriftliche Notizen lesen und visuelle Datenformate inhaltlich verstehen, ohne vorher eine reine Textebene extrahieren zu müssen. Das würde aktuelle Engpässe bei LLMs überwinden und den Workflow deutlich vereinfachen.
Gleichzeitig wird die Forschung an effizienteren, kostengünstigeren und weniger fehleranfälligen KI-Modellen intensiv vorangetrieben. Trotz allem sollten Erwartungen an LLMs im Kontext unstrukturierter Daten realistisch bleiben. Sie markieren einen bedeutenden Fortschritt und eröffnen neue Möglichkeiten der Automatisierung, sind aber noch kein Allheilmittel. Die Integration in bewährte Datenökosysteme, die Einbindung menschlicher Kontrolle und die Berücksichtigung wirtschaftlicher Faktoren sind weiterhin entscheidend für den Erfolg. Zusammenfassend lässt sich sagen, dass Large Language Models in der Verarbeitung unstrukturierter Daten eine spannende Rolle spielen, aber derzeit noch mit Beschränkungen und Herausforderungen konfrontiert sind, die ihre universelle Einsetzbarkeit limitieren.
Die Zukunft wird zeigen, wie rasch Technologien wie verbesserte LLMs und Vision-Modelle diese Lücken schließen können. Bis dahin erfordert die Handhabung unstrukturierter Daten ein ausgewogenes Zusammenspiel aus traditionellen Methoden, spezialisierter Software und adaptiven KI-Ansätzen, die sich an die besonderen Anforderungen verschiedener Branchen und Use Cases anpassen lassen.