In der heutigen digitalen Welt gewinnen multimodale Künstliche-Intelligenz-Systeme zunehmend an Bedeutung. Sie ermöglichen Maschinen nicht nur, einzelne Arten von Daten zu verstehen, sondern verschiedenste Medienformate gleichzeitig zu analysieren und darauf zu reagieren. Qwen2.5-Omni stellt in diesem Zusammenhang einen bedeutenden Durchbruch dar. Als ein end-to-end multimodales Modell bietet es eine umfassende Plattform für die Integration und Verarbeitung von Text, Bildern, Audio und Video.
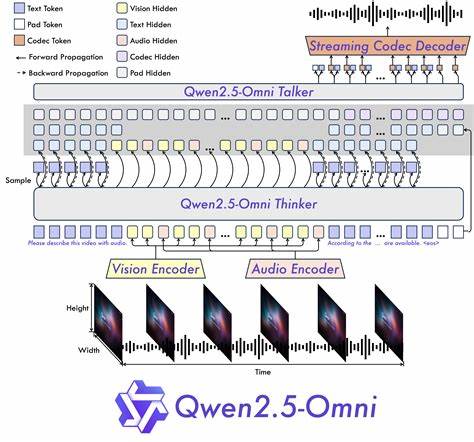
Diese Kombination ermöglicht eine Vielzahl an Anwendungen, von Echtzeit-Dialogsystemen bis hin zu kreativen Lösungen in der Medienproduktion und Forschung. Qwen2.5-Omni wurde vom Qwen-Team bei Alibaba Cloud entwickelt und setzt neue Maßstäbe hinsichtlich der Vielseitigkeit und Effektivität in der multimodalen KI. Die Architektur des Modells basiert auf einem innovativen Ansatz namens Thinker-Talker, der das simultane Verarbeiten von verschiedenen Datenquellen mit der simultanen Erzeugung von sowohl Text als auch natürlicher Sprachwiedergabe ermöglicht. Mit dieser Struktur reagiert Qwen2.
5-Omni flexibel und in Echtzeit auf Nutzereingaben, was insbesondere für interaktive Anwendungen wie Voice- und Video-Chats von großer Bedeutung ist. Ein herausragendes Merkmal des Modells ist die Integration der neuen Positionscodierung TMRoPE (Time-aligned Multimodal RoPE). Diese Technologie synchronisiert Zeitstempel bei Videoeingaben mit Audio und gewährleistet so eine präzise Ausrichtung multimodaler Signale über verschiedene Kanäle hinweg. Das Ergebnis ist eine kohärente und natürliche Interpretation von Inhalten, die für Nutzende spürbar ist – beispielsweise bei der Analyse und Antwort auf kombinierte Video- und Toninformationen. Die Fähigkeit zur Echtzeit-Interaktion ist ein weiterer Meilenstein von Qwen2.
5-Omni. Anwender können in Video- oder Sprachanrufen mit dem Modell kommunizieren und erhalten unmittelbar generierte Antworten in Textform sowie als natürliche Sprache. Diese Funktion hebt das Modell von vielen älteren Systemen ab, die meist erhebliche Verzögerungen in der Ausgabe haben oder nur bestimmte Modalitäten unterstützen. Die natürliche und robuste Sprachsynthese von Qwen2.5-Omni überzeugt durch große Natürlichkeit und klare Artikulation.
Die KI erzeugt Stimmen, die menschlichen Sprecherinnen und Sprechern in ihrer Lebendigkeit und Varianz ähneln, was speziell in Kundenservice, virtuellen Assistenten und unterhaltsamen Chatbots von großem Vorteil ist. Zwei vordefinierte Stimmen, Chelsie und Ethan, bieten unterschiedliche Charakteristika, sodass Nutzende die Möglichkeit haben, je nach Einsatzszenario und persönlichem Geschmack zu wählen. Performance-technisch übertrifft Qwen2.5-Omni selbst spezialisierte Einzelmodellsysteme. In umfangreichen Tests konnte das Modell mit der speziell für Audio entwickelten Variante Qwen2-Audio sowie dem visuellen Modell Qwen2.
5-VL-7B mithalten oder diese sogar übertreffen. Das Modell bewies sich zudem auf unterschiedlichen Benchmark-Datensätzen wie Common Voice für Spracherkennung, CoVoST2 für Übersetzungen und MVBench für Videoverstehen und sicherte sich dort Spitzenpositionen. Die Fähigkeit, Multimodalität in einem einzigen System nahtlos zu vereinen, eröffnet ganz neue Anwendungsfelder. So ist es möglich, aus Videoaufnahmen nicht nur die visuelle Information zu extrahieren, sondern gleichzeitig auch die akustischen Signale zu analysieren und in Beziehung zu setzen. Dies ermöglicht neue Formen etwa der Videoanalyse in Sicherheitsanwendungen, beim Content Monitoring oder in der Medienproduktion.
Ein wichtiger Schritt zur breiten Einsetzbarkeit von Qwen2.5-Omni sind die optimierten Quantisierungsverfahren GPTQ-Int4 und AWQ. Diese Methoden reduzieren den GPU-Speicherbedarf um mehr als 50 Prozent, ohne signifikante Leistungseinbußen. Somit kann das Modell auch auf Geräten mit eingeschränkten Hardware-Ressourcen wie modernen Gaming-GPUs oder Edge-Geräten betrieben werden. Besonders für den Einsatz in der Praxis, bei dem häufig nicht unbegrenzt Rechenkapazitäten zur Verfügung stehen, ist das ein entscheidender Vorteil.
Die Entwickler legen großen Wert auf benutzerfreundliche Einsatzmöglichkeiten. So ist Qwen2.5-Omni nahtlos in bekannte Frameworks wie Hugging Face Transformers und ModelScope integriert. Für Entwickler stehen SDKs und Tools bereit, die den Umgang mit multimodalen Daten stark vereinfachen. Videos, Audios, Bilder oder Texte können als Eingaben fungieren, die direkt vom Modell verarbeitet und beantwortet werden.
Für noch bessere Performance wird die Unterstützung von FlashAttention 2 empfohlen. Dieses Upgrade optimiert die Speicher- und Rechenlast während der Modellausführung und trägt dazu bei, insbesondere bei der Verarbeitung großer Datenströme effizient zu bleiben. Gleichzeitig unterstützt das System Streaming-Ausgaben, sodass Nutzer den Output kontinuierlich in Echtzeit erhalten, was bei Gesprächen oder langen Audio- und Videodateien besonders wertvoll ist. Neben der Unterstützung in der Cloud wurde das Modell auch für den Betrieb auf mobilen und Edge-Geräten entwickelt. Mit der MNN-Implementierung können Nutzer Qwen2.
5-Omni auf beispielsweise Snapdragon-basierten Plattformen ausführen, was den Weg für smarte Geräte und Anwendungen im Alltag ebnet. Diese Vielseitigkeit zeigt deutlich, dass Qwen2.5-Omni ein skalierbares Modell für verschiedenste Einsatzzwecke darstellt. Die praktischen Anwendungsfälle von Qwen2.5-Omni sind umfangreich und reichen weit über einfache Chatbots hinaus.
Im Bereich Kundenbetreuung können virtuelle Assistenten nun Gespräche mit visuellen und auditiven Kontextinformationen führen und so präzisere, kontextbewusste Antworten geben. Im Bildungssektor lassen sich interaktive Lernumgebungen schaffen, bei denen Lehrvideos mit Erklärungen, Fragen und unmittelbarem Feedback des Systems ergänzt werden. Auch im Gesundheitswesen könnte das System eine wichtige Rolle spielen. Durch multimodale Analyse von Sprachproben, Videos oder Dokumentationen lassen sich Erkrankungen frühzeitig erkennen oder diagnostische Unterstützung anbieten. Kombiniert man die real-time Sprachsynthese, können Patienten mit eingeschränkter Kommunikationsfähigkeit so direkt und natürlich interagieren.
Darüber hinaus unterstützt Qwen2.5-Omni die Forschung in der KI selbst, indem es als Plattform für die Entwicklung neuer multimodaler Modelle und Anwendungen dient. Die offene Verfügbarkeit über Plattformen wie GitHub, Hugging Face und ModelScope vereinfacht den Zugang für Entwickler und Forscher weltweit. Die Zukunft der KI wird maßgeblich durch solche multimodalen Systeme geprägt sein. Sie bringen die Möglichkeit mit sich, die Kluft zwischen unterschiedlichen Datenwelten zu überwinden und natürlichen menschlichen Kommunikationsformen näherzukommen.
Qwen2.5-Omni stellt in diesem Feld einen bedeutenden Fortschritt dar, der sowohl technologisch als auch praktisch neue Horizonte eröffnet. Wer auf der Suche nach einem vielseitigen, leistungsstarken und zugleich anwenderfreundlichen KI-Modell ist, sollte Qwen2.5-Omni näher betrachten. Die Kombination aus Echtzeitfähigkeit, Multimodalität und natürlicher Sprachsynthese macht das Modell zu einem zukunftsweisenden Werkzeug.
Ob in der Industrie, Forschung, im Bildungsbereich oder im Endkundensegment – die Möglichkeiten sind beeindruckend. Abschließend lässt sich sagen, dass mit Qwen2.5-Omni der Grundstein für eine neue Generation multimodaler KI-Anwendungen gelegt ist. Entwickelt mit Blick auf Flexibilität und Leistungsfähigkeit, setzt es neue Maßstäbe für das, was Künstliche Intelligenz leisten kann, wenn unterschiedliche Sinnesmodalitäten verbunden und intelligent verarbeitet werden. Die stetige Weiterentwicklung und die Unterstützung großer Entwickler-Communitys lassen erwarten, dass Qwen2.
5-Omni auch in den nächsten Jahren eine zentrale Rolle bei der Gestaltung intelligenter Systeme spielen wird.


![Eric Barone Talks Stardew Valley and Haunted Chocolatier [video]](/images/6C48A610-5A4F-4621-A6B5-37228636C43B)