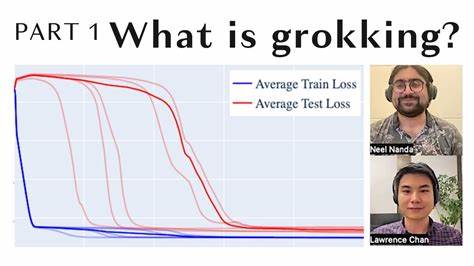
In der Welt der künstlichen Intelligenz und des maschinellen Lernens nehmen neuronale Netzwerke eine zentrale Rolle ein, wenn es darum geht, komplexe Muster und Zusammenhänge zu erkennen. Dennoch stellen sich Entwickler und Forscher immer wieder vor Herausforderungen, wenn es um die Trainingszeit und die Effizienz dieser Modelle geht. Ein besonders faszinierendes, jedoch zugleich herausforderndes Phänomen ist das sogenannte Grokking. Es beschreibt eine Phase im Training, in der ein Modell zunächst die Trainingsdaten memoriert und nur eine schwache Generalisierungsfähigkeit zeigt. Erst nach einer längeren Trainingsdauer erfolgt ein plötzlicher und sprunghafter Übergang zu nahezu perfekter Generalisierung.
Dieser späte Zeitpunkt der Leistungsexplosion ist zwar interessant, bringt aber Unsicherheiten und Ineffizienzen mit sich, die in der Praxis unerwünscht sind. Genau hier setzt die innovative Methode namens GrokTransfer an, die durch den Transfer von Embeddings aus einem schwächeren Modell die Grokking-Phase erheblich beschleunigt oder sogar ganz eliminiert. Embeddings sind dabei das zentrale Element, welches die Repräsentation der Daten von einfachen Eingaben in abstraktere Merkmale ermöglicht, die das Netzwerk verarbeitet. Die Bedeutung der Embeddings für die spätere Generalisierungsfähigkeit ist groß, wie die aktuelle Forschung eindrucksvoll demonstriert. GrokTransfer nutzt hierzu die Idee, zunächst ein kleineres, weniger komplexes Modell zu trainieren, bis es eine brauchbare, wenngleich nicht optimale Generalisierungsleistung erreicht.
Die während dieses Trainings erlernten Embeddings repräsentieren bereits eine wichtige Vorverarbeitung der Daten und erfassen Muster, die das Netzwerk als relevant erkannt hat. Anstatt die Lernphase eines leistungsstärkeren Modells komplett von Grund auf zu beginnen, werden diese Embeddings als Startpunkt genommen und in das größere, komplexere Netzwerk übertragen. Diese Initialisierung ermöglicht es dem stärkeren Modell, die Trainingsdaten von Anfang an besser zu interpretieren und schneller zu generalisieren – die verzögerte Phase des grokking wird dabei praktisch übersprungen. Die Wirksamkeit von GrokTransfer konnte in synthetischen Tests, wie beispielsweise dem XOR-Problem, überzeugend nachgewiesen werden. In diesem Szenario zeigt sich unter normalem Training stets ein deutliches Verzögerungsmoment, bevor eine Generalisierung einsetzt.
Mit Embedding Transfer hingegen gelingt die sofortige Generalisierung ohne Wartezeit. Auch in realistischeren Anwendungen und bei unterschiedlichen Netzwerkarchitekturen, etwa bei vollvernetzten neuronalen Netzen und Transformer-Modellen, bestätigt sich diese positive Wirkung. Was macht diesen Ansatz so besonders und relevant für die Zukunft der künstlichen Intelligenz? Zunächst steigert GrokTransfer die Effizienz von Lernprozessen immens. Kürzere Trainingszeiten bedeuten keinen geringeren Ressourcenverbrauch, was sowohl ökologische als auch ökonomische Vorteile mit sich bringt. Darüber hinaus verbessert es die Planbarkeit des Trainingsverlaufs, da der lange und unvorhersehbare „Warteabschnitt“ des Grokking wegfällt.
Dies ist besonders in Berufsfeldern wichtig, in denen Vorhersagbarkeit und schnelle Anpassung von Modellen gefragt sind, wie in der Medizin oder der autonomen Fahrzeugtechnik. Ein weiterer Aspekt ist, dass durch das Vorgehen des Embedding Transfers implizit ein Vorwissen oder eine Wissensbasis eines schwächeren Modells übertragen wird. Dieses Prinzip erinnert an das menschliche Lernen, bei dem frühere Erfahrungen und Grundlagenwissen neue Lernphasen unterstützen und beschleunigen. Im Bereich des maschinellen Lernens wird dieses Muster des Wissens- und Erfahrungstransfers zunehmend erforscht und bietet vielfältige Methoden für die Optimierung großer komplexer Modelle. Die Forschung von Zhiwei Xu, Zhiyu Ni und Kollegen, die ihre Erkenntnisse im Rahmen der ICLR 2025 vorgestellt haben, zeigt mit GrokTransfer genau eine solche elegante technische Umsetzung.
Der Ansatz ist relativ einfach umzusetzen, da er keine komplexen Modifikationen im Training erfordert, sondern auf einer intelligenten Initialisierungskomponente basiert. Damit wird das Verzögerungsphänomen des Grokking in einer Vielzahl von Settings bekämpft und damit neue Maßstäbe für die Trainingsdynamik neuronaler Netzwerke gesetzt. Es gilt jedoch auch zu beachten, dass das Training des schwächeren Anfangsmodells neuen Rechenaufwand bedeutet. Dieser Einsatz wird jedoch durch die insgesamt schnellere Schlussphase mehr als kompensiert. Zudem ist die Auswahl des schwächeren Modells und die Art des Transfers entscheidend, um optimale Ergebnisse zu erzielen.
Aktuelle Studien gehen zudem der Frage nach, wie gut der Embedding Transfer in unterschiedlichen Domänen funktioniert, etwa bei Bild-, Sprach- oder Textverarbeitung, und wie er in Kombination mit weiteren Techniken wie Transfer Learning oder Meta-Learning synergistisch wirken kann. Für Unternehmen und Entwickler bedeutet die Integration solcher Verfahren eine Chance, die Effizienz und Qualität ihrer KI-Systeme deutlich zu erhöhen. Gleichzeitig fördert es ein tieferes Verständnis der Trainingsmechanismen neuronaler Netzwerke und öffnet Türen zu neuen Produktivitäts- und Innovationspotentialen. Abschließend lässt sich festhalten, dass GrokTransfer mit seiner Fokussierung auf Embedding Transfer ein wegweisender Ansatz ist, um die bisherige Barriere des verspäteten Grokkings zu überwinden. Durch eine clevere Nutzung einfacher Modelle als Vorstufe gelingt es, die Leistungsfähigkeit komplexerer Netzwerke schneller und zuverlässiger zu aktivieren.
Diese Entwicklung bringt Maschinenlernen nicht nur näher an menschliches Lernen heran, sondern macht es auch effizienter und praxistauglicher. In naher Zukunft werden solche Methoden die Basis für viele weitere Fortschritte in der KI-Forschung und deren Anwendungen bilden. Wer sich ernsthaft mit modernen Lernprozessen in neuronalen Netzwerken auseinandersetzt, kommt an dem Prinzip des Embedding Transfers nicht mehr vorbei – es ist ein Schlüssel zur Beschleunigung von Lernen und Verstehen in künstlichen Systemen.