Die menschliche DNA ist das fundamentale Molekül des Lebens, das den Bauplan für jeden Organismus enthält. Mit etwa 3,1 Milliarden Basenpaaren repräsentiert sie eine enorme Menge an biologischer Information. Doch wie viel Datenmenge steckt tatsächlich in der DNA eines Menschen? Die einfache Antwort lautet: Etwa 12 Milliarden Bits, was ungefähr 1,5 Gigabyte entspricht. Doch diese Zahl allein täuscht darüber hinweg, wie komplex und vielschichtig das Konzept von „Information“ in der biologischen Welt wirklich ist. Jedes Basenpaar kann vier verschiedene Nukleotide enthalten — Adenin (A), Thymin (T), Cytosin (C) oder Guanin (G).
Diese vier Varianten lassen sich theoretisch mit zwei Bits codieren, da zwei Bits vier Zustände repräsentieren können. Daraus ergibt sich, dass das gesamte menschliche Erbgut bei einem weiblichen Genom, das zwei Kopien jedes Chromosoms enthält, rund 12,1 Milliarden Bits stellt. Bei männlichen Genomen, die ein X- und ein Y-Chromosom besitzen, sind es knapp 11,9 Milliarden Bits. Dieser Rohdatenwert ist jedoch nur der Anfang der Betrachtung. Die meisten Menschen teilen 99,6 Prozent ihres Erbguts miteinander.
Das bedeutet, dass die individuelle genetische Variation vergleichsweise gering ist. Man könnte also argumentieren, dass ein großer Teil der genetischen Information redundant ist, wenn man die DNA im Hinblick auf individuelle Unterschiede betrachtet. Diese Tatsache bildet die Grundlage vieler moderner Genom-Kompressionsalgorithmen, die mit einem sogenannten Referenzgenom arbeiten. Dabei wird das komplette menschliche Genom als Basis gespeichert und für jede Person nur die Abweichungen davon festgehalten. So kann die Speichergröße um über 99 Prozent reduziert werden, je nachdem, wie gut das Referenzgenom die Vielfalt abdeckt.
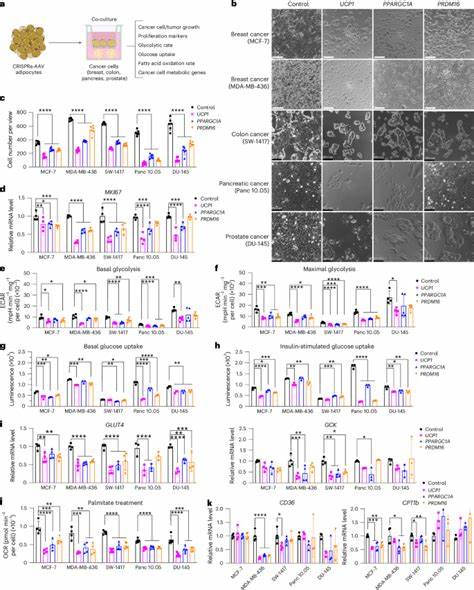
Doch Kompression ist kein einfaches Konzept, wenn es um die Definition von Information in der DNA geht. Man kann das Genom einfach als eine lange Folge von Buchstaben betrachten, aber was wirklich relevant ist, ist zu verstehen, welcher Anteil tatsächlich „Bedeutung“ hat und wie diese Bedeutung definiert wird. Hier kommen unterschiedliche Konzepte aus der Informationstheorie ins Spiel. Kolmogorov-Komplexität und Shannon-Information stellen zwei verschiedene Herangehensweisen dar, diesen Begriff praktisch zu fassen. Die Kolmogorov-Komplexität misst die Länge des kürzesten Computerprogramms, das eine bestimmte DNA-Sequenz ausgeben kann.
Diese Definition entspricht im Prinzip der bestmöglichen verlustfreien Kompression ohne Referenz. Gemäß dieser Definition enthält die DNA eines Menschen rund 4,6 Milliarden Bits an Information, wenn man von der besten verfügbaren Kompression ausgeht. Die Shannon-Information hingegen betrachtet die Wahrscheinlichkeit, mit der eine bestimmte Sequenz im Gesamtpool der menschlichen Genome vorkommt. Hierbei wird das Wissen um verbreitete Muster und Varianten einbezogen. Das Resultat ist eine viel geringere Menge an „Information“, da in dieser Betrachtung nur die individuellen Unterschiede gegenüber dem Durchschnittszustand gezählt werden.
Das heißt, unter dieser Perspektive enthält ein menschliches Genom nur etwa 120 Millionen Bits an Information. Dieser enorme Unterschied zeigt, wie stark die Interpretation von „Information“ variieren kann, je nachdem, welchen theoretischen Rahmen man anlegt. Für biologische Fragestellungen, bei denen es darum geht, wie viel Wissen über die Funktionsweise und Komplexität eines Lebewesens im Genom kodiert ist, ist die Kolmogorov-Komplexität oft die sinnvollere Wahl, da sie auch die konservierten, für alle Menschen gemeinsamen Abschnitte einbezieht. Biologisch gesehen ist die DNA jedoch weit mehr als nur eine lineare Abfolge von Nukleotiden. Nur etwa 1 Prozent des menschlichen Genoms codiert direkt für Proteine.
Ein weitaus größerer Teil wird in RNA transkribiert, die nicht immer in Proteine übersetzt wird, aber dennoch wichtige regulatorische Funktionen erfüllen kann. Das restliche Genom besteht aus sogenannten Introns, regulatorischen Sequenzen wie Promotoren, Enhancern oder Silencern, repetitiven Abschnitten, Pseudogenen und strukturellen Elementen wie Telomeren und Zentromeren. Diese Millionen Basenpaare erweisen sich häufig als ein komplexes Zusammenspiel von Funktionen, Redundanzen und scheinbar „nutzlosem“ genetischen Material, das in Wirklichkeit bedeutsame Rollen in der Genregulation, Chromosomenstabilität und evolutionären Anpassung spielt. Die DNA eines Lebewesens ist somit kein statisches Datenarchiv, sondern ein dynamisches System, das viele Schichten und Ebenen der Informationsverarbeitung enthält. Eine wesentliche Herausforderung bei der Bewertung der Informationsmenge in der DNA besteht darin, die „Nützlichkeit“ der codierten Sequenzen zu beurteilen.
Die molekulare Biologie hat gezeigt, dass evolutionär konservierte Regionen oft jene sind, die eine lebenswichtige Funktion erfüllen. Dennoch gibt es viele DNA-Abschnitte, deren Funktion noch unbekannt oder sehr subtil ist. Man spricht deshalb auch von der sogenannten „Dunklen Materie des Genoms“. Hier ist die Forschung weiterhin aktiv, und unser Verständnis von den Herausforderungen und Feinheiten der Genomkomplexität wächst beständig. Mutationen, also Veränderungen an der DNA, passieren ständig aufgrund von Fehlern bei der Zellteilung oder durch Umwelteinflüsse wie UV-Strahlung oder chemische Stoffe.
Der Körper verfügt über ausgeklügelte Reparaturmechanismen, die meistens dafür sorgen, dass Veränderungen minimal und kontrolliert bleiben. Doch der fortwährende Kampf zwischen Mutationen und Reparaturmechanismen trägt auch dazu bei, dass das Genom niemals statisch ist. Die biologische „Messy-ness“, also die „Unordnung“ in der DNA, ist deshalb kein Fehler, sondern ein Teil des Evolutionsprozesses. Aus all diesen Gründen schlägt die Wissenschaft vor, die Information in der DNA nicht nur anhand der Sequenz zu messen, sondern auch im Kontext des phänotypischen Outputs — also dem, was aus der DNA tatsächlich an sichtbaren und funktionalen Eigenschaften eines Lebewesens entsteht. Diese sogenannte „phänotypische Kolmogorov-Komplexität“ beschreibt die kürzeste mögliche Kompression der DNA, die dennoch zu einem Individuum führt, das äußerlich und funktional wie ein Mensch ist.