Die Entwicklung von großen Denkmodellen (Large Reasoning Models, LRMs) hat in den letzten Jahren wesentliche Fortschritte erzielt und verändert grundlegend die Art und Weise, wie KI komplexe Probleme löst. Ein bahnbrechender Beitrag in diesem Bereich ist AlphaOne, ein universelles Framework, das auf intelligente Weise Denkprozesse während der Testphase moduliert und dabei zwischen langsamen und schnellen Denkphasen unterscheidet. AlphaOne bringt eine innovative Herangehensweise an das Testzeitverhalten von Denkmodellen, die sowohl die Rechenressourcen als auch die Genauigkeit bei anspruchsvollen Aufgaben optimiert. Diese Kombination von „langsamem“ und „schnellem“ Denken orientiert sich an den Konzepten aus der kognitiven Psychologie und wird jetzt effektiv auf künstliche Intelligenz übertragen, um ihre Leistungsfähigkeit signifikant zu steigern. AlphaOne verfolgt das Ziel, die Testphase von großen Modellen nicht nur effizienter zu gestalten, sondern auch die Qualität der Ergebnisse auf wichtigen Benchmarks zu verbessern, die von mathematischen Problemen über Code-Generierung bis hin zu wissenschaftlichen Fragestellungen reichen.
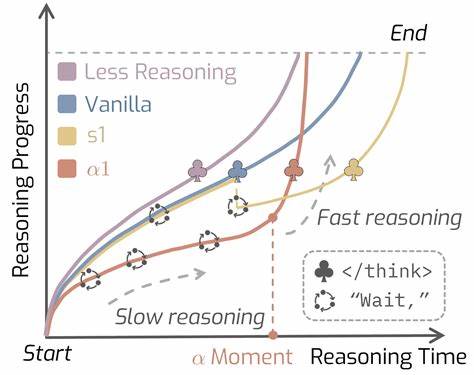
Das Modell führt die sogenannte „Moment“-Variable ein, welche die Dauer der langsamen Denkphase steuert. Innerhalb dieses sogenannten Pre-Moment-Intervalls moduliert AlphaOne dynamisch den Übergang vom langsamen Denken durch einen stochastischen Prozess, der reasoning transition tokens einfügt. Nach dem Erreichen dieses Moments beendet AlphaOne deterministisch die langsame Denkphase und sorgt durch das Einfügen eines End-of-Thinking-Tokens für einen nahtlosen Übergang in die schnelle Denkphase. Dieses Vorgehen erlaubt eine flexible und feinkörnige Kontrolle des Denkprozesses, die über bisherige monotone Skalierungsmethoden hinausgeht, da es sowohl dichte als auch variable Übergänge zwischen langsamen und schnellen Denkphasen ermöglicht. Durch diese innovative Modulation können Rechenzeiten und Komplexität optimiert werden, ohne dass die Qualität der Schlussfolgerungen leidet, eher im Gegenteil: AlphaOne verbessert die Leistungsfähigkeit auf unterschiedlichsten Benchmarks und Modellen mit einer Größenordnung von 1,5 bis zu 32 Milliarden Parametern.
Im Rahmen umfangreicher Experimente an sechs verschiedenen Benchmark-Sets, die komplexe mathematische Problemstellungen, wissenschaftliche Fragestellungen und Programmieraufgaben umfassen, zeigte AlphaOne signifikante Leistungssteigerungen sowohl in Bezug auf Genauigkeit als auch Effizienz. Besonders hervorzuheben ist dabei, dass eine anfängliche langsame Denkphase gefolgt von schnellem Denken zu besseren Ergebnissen führt. Diese Erkenntnis spiegelt wider, dass eine sorgfältige Vorbereitung und tiefere Überlegung zu Beginn, kombiniert mit einem schnellen Finalisierungsschritt, der Qualität der Antworten immens zugutekommt. Darüber hinaus fördert AlphaOne häufige, dichte Übergänge zwischen den Denkphasen während der langsamen Denkphase die Leistung, was auf eine dynamische Anpassung an die Komplexität der Aufgabe hindeutet. Die Möglichkeit, diese Übergänge präzise zu steuern, erlaubt es, die Denkstrategie an die individuellen Anforderungen jeder Herausforderung flexibel anzupassen.
AlphaOne bietet zudem einen wichtigen Beitrag zur Reduzierung der benötigten Rechenzeit im Testbetrieb, da die schnelle Denkphase effizienter ist und erst dann einsetzt, wenn die notwendige Vorarbeit geleistet wurde. Diese intelligente Zeit- und Ressourcensteuerung erhöht die Wirtschaftlichkeit und Benutzerfreundlichkeit von großen Denkmodellen erheblich und macht sie attraktiver für den praktischen Einsatz in produktiven Umgebungen. Die zugrundeliegende Technologie kann ferner als Grundlage für weitere Forschungen und Anwendungen dienen, die eine Verbindung von kognitiven Modellen mit maschinellem Lernen suchen und dabei von der modernen Skalierbarkeit großer KI-Modelle profitieren wollen. Auch die Herausforderung, zuverlässige und zugleich effiziente Schlussfolgerungen zu ziehen, wird durch Ansatzpunkte wie AlphaOne wesentlich adressiert. Die Autoren der Studie kommen dabei aus führenden Forschungsinstitutionen wie der University of Illinois Urbana-Champaign und der UC Berkeley und veröffentlichen ihre Ergebnisse auf der renommierten EMNLP 2025 Konferenz.
Ihr Beitrag zeigt überzeugend den Weg auf, wie adaptives Denken in großen Modellen nicht nur theoretisch, sondern auch praktisch umgesetzt werden kann. Insgesamt zeichnet sich AlphaOne durch seine universelle Anwendbarkeit, seine starke Verbesserung in komplexen Aufgabenbereichen und seine Effizienz bei der Ressourcenverwendung aus. Für Entwickler, Forscher und Anwender im Bereich der Künstlichen Intelligenz stellt dieses Framework eine wertvolle Innovation dar, um den aktuellen Stand der Technik bei Reasoning-Modellen auf das nächste Level zu heben. Die erfolgreiche Verbindung von langsamem und schnellem Denken bei großen Modellen lässt sich als Meilenstein interpretieren, der neue Perspektiven für die zukünftige Entwicklung intelligenter Systeme eröffnet. Die Erkenntnisse der Untersuchung laden zudem dazu ein, Denkprozesse bei KI-Systemen noch gezielter zu steuern und damit in vielfältigen Anwendungsfeldern präzisere und leistungsfähigere Ergebnisse zu erzielen, sei es in der Mathematik, im wissenschaftlichen Rechnen oder in der Softwareentwicklung.
AlphaOne ist somit ein bedeutender Schritt hin zu dynamischeren, skalierbaren und adaptiven Modellen, die den Anforderungen komplexer realweltlicher Problemlösungen optimal gerecht werden.