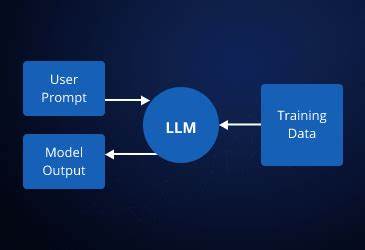
In der heutigen digitalen Welt gewinnen große Sprachmodelle, auch bekannt als Large Language Models (LLMs), immer mehr an Bedeutung. Sie ermöglichen es Entwicklern, intelligente Chatbots, KI-gestützte Assistenten oder andere interaktive Anwendungen zu bauen, die in natürlicher Sprache kommunizieren. Die Entwicklung solcher LLM-basierten Systeme wirkt auf den ersten Blick komplex, doch mit den richtigen Ansätzen und Werkzeugen wird sie zugänglich und effizient. Ein aktuelles Projekt zeigt auf praxisnahe Weise, wie solche Systeme konzipiert und umgesetzt werden können. Dabei wird deutlich, wie wichtig Elemente wie eine durchdachte Frontend-Integration, ein flexibler Nachrichten-Adapter, eine zuverlässige Streaming-Architektur und ein klar strukturiertes Nachrichtenverarbeitungspipeline sind.
Ebenso überrascht die Leistungsfähigkeit von Programmiersprachen wie Elixir, die dank ihres modernen Designs und ihrer hervorragenden Nebenläufigkeit sich perfekt für derartige KI-Projekte eignen. Ein zentraler Bestandteil des Entwicklungsprozesses war die Wahl eines Frontends, das von Anfang an eine robuste Basis bietet. Statt eine eigene Benutzeroberfläche von Grund auf zu entwickeln, wurde auf Open WebUI gesetzt – eine Open-Source-Lösung, die eine fertige Chat-Schnittstelle mitbringt. Diese Oberfläche ist besonders flexibel und unterstützt von Haus aus verschiedene Anzeigeformate, darunter Markdown und sogenannte Think Tags, die für spezielle KI-interne Funktionen genutzt werden. Dank Open WebUI liegt der Fokus in der Anfangsphase weniger auf dem visuellen Design, sondern auf der Funktionalität und auf dem nahtlosen Datenaustausch mit der KI-Engine.
Diese Trennung von Frontend und Backend ist sinnvoll, vor allem in den frühen Entwicklungsschritten. Das Frontend übernimmt hier die Rolle eines reinen Messaging-Clients, der Nutzereingaben erfasst, darstellt und an die Backend-Logik weiterleitet. Allerdings muss das Backend in der Lage sein, die Nachrichten in einer für die eigentliche KI-Engine passenden Form zu empfangen. Hier kommen sogenannte Filter und Adapter ins Spiel. Bei Open WebUI existiert ein Konzept von Filtern, mit denen sich die übermittelten Nachrichten anpassen lassen, etwa um zusätzliche Daten wie Nutzer-ID oder Chat-Thread-ID einzufügen.
Gerade für maßgeschneiderte KI-Anwendungen sind diese Informationen unverzichtbar, um den Kontext der Unterhaltung sicherzustellen und den Zustand korrekt zu verwalten. Die zugrunde liegende Adapter-Logik wird typischerweise als kleines Python-Skript realisiert, das die Daten aus dem Frontend in ein vereinfachtes und standardisiertes Format transformiert. So werden beispielsweise alle Nachrichten eines Threads auf einen neuen Input reduziert, der neben der eigentlichen Nutzeranfrage auch die eindeutige Kennung des Chats sowie eine Identifikation des Nutzers enthält. Dieses Format ermöglicht es dem KI-Backend, sich auf die aktuelle Eingabe zu konzentrieren, während der gesamte Gesprächskontext intern im Backend gespeichert und verwaltet wird. Eine vollständige Übermittlung des gesamten Nachrichtenverlaufs bei jedem Request entfällt somit und spart unnötigen Overhead.
Die Anbindung des Adapters erfolgt direkt in der Verwaltungsoberfläche von Open WebUI, in der sogenannte Connections eingerichtet werden. Dort wird die URL des Backend-Endpunkts hinterlegt – häufig ist dies eine lokale Entwicklungsumgebung, die mit Tools wie Tailscale sicher ins Internet gebracht wird. Die Konfiguration ist schnell erledigt und eröffnet die Möglichkeit, unterschiedliche KI-Modelle und Adapter über separate Workspaces zu organisieren. Diese Workspaces erlauben es, verschiedene Modelle individuell anzupassen, was gerade für Tests oder Entwicklungszwecke große Vorteile bietet. Ein weiteres Kernstück der Architektur ist der Chat-Completions-Endpoint, der der Kompatibilität mit dem OpenAI-Standard folgt.
Die Implementierung setzt auf einen streamfähigen Ansatz, der es ermöglicht, Antworten in Echtzeit Stück für Stück an den Client zu übermitteln. Diese Technik verbessert die Nutzererfahrung deutlich, da resultierende Antworten schneller sichtbar werden und nicht erst nach kompletter Erzeugung aller Daten angezeigt werden müssen. Die Basis dieses Streaming-Konzepts bildet eine elegante Lösung mit Phoenix, einem Elixir-Framework, das durch seine eingebaute Unterstützung von PubSub-Messaging die Kommunikation zwischen Server und Client unterstützt. Durch das Abonnieren eines bestimmten Topics, hier repräsentiert durch die eindeutige Nachricht-ID, kann der Stream permanent geöffnet bleiben. Neue Datenpakete, sogenannte Chunks, werden vom Backend erzeugt und sofort an den Client gesendet.
Der zuständige Listener bearbeitet parallel die empfangenen Chunks, überprüft sie auf das Ende des Streams und schließt dann die Übertragung ab. Damit stellt das System sicher, dass die Verbindung nicht vorzeitig geschlossen wird und der Nutzer die vollständige Antwort erhält. Die Verarbeitung eingehender Nutzeranfragen erfolgt in einem ausgefeilten Nachrichtenverarbeitungspipeline. Dieses Pipeline-Modell kann man sich als Denkprozess der KI vorstellen, der auf mehreren Schichten arbeitet, um die Bedeutung der Nachricht zu analysieren und die optimale Antwort zu generieren. Dabei wird jede Nachricht je nach Inhalt und Kontext unterschiedlich behandelt.
So kann die Pipeline zum Beispiel normale Konversationen von speziellen Kommandos unterscheiden oder zusätzliche Verarbeitungsschritte aktivieren. Am Ende dieser Kette steht der Aufruf eines LLMs, das auf Basis der vorbereiteten Informationen stückweise eine passende Antwort erzeugt und an den Stream zurückliefert. Ein besonderes Augenmerk liegt auf der asynchronen Verarbeitung der Antwortströme. Die LLM-Nutzung erfolgt häufig über externe APIs, die Antworten verzögert liefern oder sukzessive erweitern. Um diese Architektur effizient zu gestalten, wird eine sogenannte Agent-Verwaltung innerhalb von Elixir genutzt.
Diese Agenten sind leichte Prozesse, die Daten puffern und aggregieren können, während der Stream läuft. Dadurch lassen sich empfangene Chunks kontinuierlich sammeln, um am Ende der Übertragung aus den Daten eine vollständige Nachricht zusammenzusetzen. Beim Zusammenbauen der Antwort wird darauf geachtet, die OpenAI-konforme Struktur zu berücksichtigen. Die einzelnen Daten-Snippets werden dekodiert, deren Inhalte extrahiert und als stringbasierte Antwort zusammengesetzt. Das Ergebnis kann anschließend in einer Datenbank oder jedem anderen Speichersystem persistiert werden.
So wird der gesamte Gesprächsverlauf sicher gesichert und kann bei Bedarf jederzeit wieder abgerufen oder analysiert werden. Ein herausragendes Merkmal des Projekts ist die Nutzung von Elixir. Diese Sprache basiert auf dem Erlang-Ökosystem und ist speziell für nebenläufige Systeme entwickelt worden. Ihre starke Parallelitätsfähigkeit macht sie ideal, um mit zahlreichen gleichzeitig geöffneten Verbindungen umzugehen – ein Must-have bei modernen LLM-Anwendungen, die oft viele Nutzer gleichzeitig bedienen müssen. Phoenix, als Webframework von Elixir, integriert zusätzlich WebSocket-Unterstützung via LiveView, was Echtzeitinteraktion erleichtert.
Komponenten wie Phoenix.PubSub erlauben die mühelose Verteilung von Nachrichten an verschiedene Prozesse, während Req als HTTP-Client die Kommunikation mit externen APIs vereinfacht. Nicht zuletzt machen Tools wie Agent das Zustandsmanagement ohne großen Aufwand möglich, was sich in wenigen Zeilen Code umsetzen lässt. Diese Werkzeuge zusammengenommen sorgen für eine überschaubare, wartbare Codebasis trotz der Komplexität, die KI-Modelle mit sich bringen. Die Erfahrungen aus diesem Projekt zeigen deutlich, dass der Aufbau von LLM-basierten Anwendungen nicht zwangsläufig kompliziert sein muss, wenn man auf bewährte Komponenten und SaaS-ähnliche Muster zurückgreift.
Open WebUI bietet eine solide Basis für das Frontend, während Filter und Adapter die notwendige Schnittstellenerweiterung erlauben. Das Backend profitiert von Elixirs moderner Architektur, die Streaming, Nebenläufigkeit und funktionale Programmierung miteinander vereint. Zusammenfassend lässt sich sagen, dass durch eine klare Trennung der Bausteine, ein schlankes Nachrichtenformat und eine effiziente Streaming-Kommunikation leistungsfähige LLM-Anwendungen realisiert werden können. Das Ergebnis sind interaktive Systeme, die den Nutzern Echtzeit-Antworten liefern und zugleich robust und skalierbar bleiben. Wer sich eingehender mit modernen KI-Architekturen beschäftigen und selbst eigene LLM-Projekte entwickeln möchte, findet in diesen Mustern wertvolle Anregungen und bewährte Techniken.
Für Entwickler bieten solche praxisnahen Einblicke die Möglichkeit, sich schneller in die Welt der LLMs einzuarbeiten und typische Herausforderungen auf dem Weg zum eigenen Produkt zu meistern. Gleichzeitig unterstützt der Einsatz von Open-Source-Komponenten und modernen Programmiersprachen die Anpassbarkeit und Erweiterbarkeit der Systeme, was langfristig ein entscheidender Vorteil ist. Mit dem Innovationsschub, den LLMs und damit verbundene Technologien bringen, steht die Softwareentwicklung vor einer spannenden Zukunft, die heute schon greifbar ist.