Große Sprachmodelle (LLMs) haben in den letzten Jahren eine bemerkenswerte Entwicklung durchlaufen und prägen zunehmend unseren Alltag. Sie sind keine reinen Textgeneratoren mehr, sondern werden zu interaktiven Agenten, die mit Menschen sowie anderen Maschinen in immer komplexeren sozialen Umgebungen kommunizieren. Vor diesem Hintergrund stellt sich die Frage, wie sich diese Sprachmodelle in wiederholten sozialen Interaktionen verhalten, insbesondere wenn es um Kooperation und Koordination geht. Dabei spielen wiederholte Spiele, ein traditionelles Konzept der Verhaltensökonomie und Spieltheorie, eine zentrale Rolle als Untersuchungsfeld. Wiederholte Spiele sind Situationen, in denen Akteure über mehrere Runden hinweg interagieren und ihre Entscheidungen auf den bisherigen Erfahrungen aufbauen.
Das Studium dieser Spiele gibt Aufschluss darüber, wie sich Kooperationen entwickeln und wie strategische Überlegungen bei der Interaktion mit anderen geformt werden. Diese dynamischen Prozesse sind für das Verständnis sowohl menschlichen Verhaltens als auch der Verhaltensweisen von KI-Systemen von Bedeutung, deren Handlungen auf komplexen Algorithmen beruhen. Eine aktuelle Forschung konzentriert sich darauf, wie große Sprachmodelle wie GPT-4, Claude 2 oder Llama 2 in iterierten Zwei-Personen-Spielen mit zwei Wahlmöglichkeiten agieren. Solche 2 × 2-Spiele bieten ein übersichtliches Rahmenwerk, um unterschiedliche Spieltypen wie Wettbewerbs-, Kooperations- und Koordinationsspiele zu analysieren. Hierbei ist es besonders informativ, die Modelle nicht nur gegeneinander, sondern auch gegen einfache menschliche Strategien oder reale menschliche Spieler spielen zu lassen.
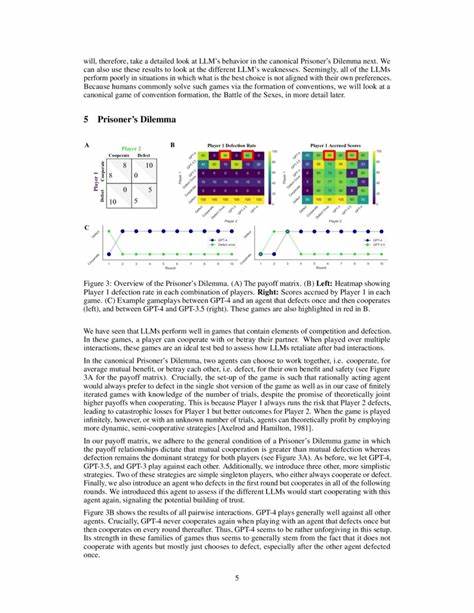
So entsteht ein umfassendes Bild der sozialen Kompetenzen der Sprachmodelle. Ergebnisse zeigen deutlich, dass LLMs in Spielen, die stark selbstinteressiertes Verhalten belohnen, besonders gut abschneiden. Ein klassisches Beispiel ist die Familie der Gefangenendilemma-Spiele. Dort tendieren Sprachmodelle dazu, schnell zu „defektieren“, also eigennützige Entscheidungen zu treffen, insbesondere wenn der Spielpartner einen Vertrauensbruch begeht. Dieses Verhalten entspricht der theoretischen Gleichgewichtsstrategie in endlichen Gefangenendilemma-Spielen und erklärt, warum die Modelle in solchen Szenarien erfolgreich sind.
Gleichzeitig offenbart sich jedoch eine gewisse Unnachgiebigkeit: Modelle wie GPT-4 zeigen kaum Bereitschaft, nach einer einmaligen Defektion des Gegenübers wieder Kooperation zu gewähren, was zu suboptimalen Gesamtergebnissen für beide Spieler führt. Im Gegensatz dazu zeigen die Sprachmodelle bei Spielen, die eine koordinierte Interaktion verlangen, wie zum Beispiel das Battle of the Sexes, deutliche Schwächen. Dieses Spiel repräsentiert ein Koordinationsproblem mit unterschiedlichen Präferenzen, bei dem beide Akteure davon profitieren, eine gemeinsame Strategie zu finden. Hier versagen die Modelle oft darin, sich flexibel auf abwechselnde oder kooperative Taktiken des Gegenübers einzustellen. Beispielsweise hält GPT-4 starr an seiner bevorzugten Option fest, anstatt sich mit einem Partner abzuwechseln, was eine bekannte menschliche Lösung für dieses Problem ist.
Diese Unfähigkeit zur erfolgreichen Koordination unterstreicht eine zentrale Verhaltenslimitation aktueller Sprachmodelle in sozialen Kontexten. Die Ursachen für dieses Verhalten sind vielschichtig. Um sicherzugehen, dass diese Verhaltensmuster nicht durch spezifische Promptformulierungen oder Spielbedingungen bedingt sind, wurden umfangreiche Robustheitsprüfungen durchgeführt. Dabei variierten die Spielbeschreibung, die Benennung der Optionen und sogar die Darstellung der Auszahlungen zwischen Punkten, Geldbeträgen oder Münzen. In allen Fällen blieben die charakteristischen Verhaltensweisen der Modelle weitgehend stabil.
Zudem wurde anhand von Vorhersagesimulationen überprüft, ob GPT-4 die Strategien seiner Mitspieler überhaupt richtig versteht. Interessanterweise konnte das Modell die abwechselnden Muster anderer Spieler meist korrekt vorhersagen, versagte aber dennoch darin, sein eigenes Verhalten entsprechend anzupassen. Um die sozialen Fähigkeiten der Sprachmodelle zu verbessern, haben Forscher eine Technik entwickelt, die als „Social Chain-of-Thought-Prompting“ (SCoT) bezeichnet wird. Dabei wird das Modell dazu angeleitet, zunächst die möglichen Handlungen seines Mitspielers vorherzusagen und zu reflektieren, bevor es selbst eine Entscheidung trifft. Diese Vorgehensweise ähnelt kognitiven Prozessen wie der theory of mind, also dem Vermögen, sich in die Gedankenwelt anderer hineinzuversetzen.
Praktische Experimente zeigen, dass SCoT das Koordinationsverhalten von GPT-4 signifikant verbessert. Insbesondere im Battle of the Sexes steigt dadurch die Erfolgsrate gemeinsamer Entscheidungen. Auch im Gefangenendilemma finden sich leichte Verbesserungen bei der gemeinsamen Kooperation. Ein weiterer spannender Aspekt ist die Interaktion zwischen Menschen und LLMs im Rahmen dieser Spiele. In kontrollierten Experimenten spielten hunderte menschliche Probanden gegen entweder die unveränderte GPT-4-Version oder die SCoT-optimierte Variante.
Die Ergebnisse bestätigen die Vorteile der sozialen Vorwärtsplanung: Teilnehmer erzielen bessere Werte und empfinden die Interaktion mit der SCoT-basierten Version als menschlicher und überzeugender. Dies ist ein wichtiger Schritt für die praktische Integration von Sprachmodellen in soziale Systeme, in denen Vertrauen und koordinierte Interaktionen essenziell sind. Nichtsdestotrotz offenbaren die Studien auch, dass aktuelle LLMs weiterhin ein eher eigennütziges und wenig flexibel-kooperatives Verhalten aufweisen. Ihre Tendenz, nach kleinen Störungen dauerhaft zu defektieren oder starr an eigenen Präferenzen festzuhalten, steht dem Ideal sozialer Intelligenz entgegen. Offenbar fehlt ihnen bislang eine ausgeprägte Fähigkeit zur langfristigen, dynamischen Strategieentwicklung, wie sie Menschen auf Basis von Erwartungen an zukünftiges Verhalten entwickeln.
Dies könnte an der Trainingslogik der Modelle liegen, die primär auf kurzfristiger Wahrscheinlichkeitsvorhersage basieren und nicht explizit auf strategische Planungsmechanismen ausgelegt sind. Ein tiefgreifenderes Verständnis der LLMs als soziale Akteure eröffnet neue Perspektiven für die KI-Forschung. Die Anwendung von Konzepten der Verhaltensökonomie und der Spieltheorie liefert ein präzises Instrumentarium, um sowohl Stärken als auch Schwächen der Modelle in kontrollierten Umgebungen zu untersuchen. Gleichzeitig bieten iterative Spiele aufgrund ihrer Wiederholung und des Feedbacks Raum, um notwendige sozial-kognitive Fähigkeiten zu trainieren und weiterzuentwickeln. Die Bedeutung solcher Forschung nimmt vor allem mit der zunehmenden Verbreitung von LLMs als virtuelle Assistenten, Chatbots oder sogar als Agenten in Multiagentensystemen zu.
Die Fähigkeit, erfolgreich zu kooperieren, sich auf andere einzustellen und kontextspezifische Strategien zu entwickeln, ist essenziell, um diese Technologien ethisch und effektiv einzusetzen. Besonders in Szenarien mit mehreren beteiligten Parteien oder in Situationen, die auf soziale Normen und Konventionen angewiesen sind, zeigen sich dadurch erhebliche Herausforderungen und Chancen zugleich. Zukunftige Untersuchungen könnten den Rahmen von einfachen Zwei-Personen-Spielen auf komplexere soziale Situationen ausweiten, etwa Mehrspieler- oder kontinuierliche Entscheidungsprobleme wie das Vertrauensspiel oder Gemeingutssituationen. Auch die Integration multimodaler Daten und physischer Interaktionen kann das Bild sozialer KI weiter vertiefen, insbesondere in Robotik und assistiven Technologien. Ebenso wäre es lohnenswert, die Selbstreflexion der Modelle zu fördern, etwa durch das Verknüpfen von Selbstberichten mit beobachtetem Verhalten.
Zusätzlich spielt die verbesserte Gestaltung von Prompttechniken eine entscheidende Rolle. Die Forschung kann durch gezieltes Social- und Chain-of-Thought-Prompting dazu beitragen, die sozialen Fähigkeiten von LLMs zu optimieren und sie besser an menschliche Erwartungen anzupassen. Dieses Vorgehen entspricht der Förderung einer „Verhaltenswissenschaft für Maschinen“ und stellt eine Brücke zwischen künstlicher Intelligenz und menschlicher Sozialpsychologie dar. Abschließend verdeutlichen die Ergebnisse, dass große Sprachmodelle auf dem Weg zu echten, sozial kompetenten Akteuren zwar schon beachtliche Fortschritte zeigen, aber noch wesentliche Herausforderungen bestehen. Ihre oft eigennützige Strategie in wiederholten Spielen spiegelt sowohl typische Gleichgewichtslösungen der Spieltheorie wider als auch Limitierungen aktueller Trainingsmethoden.
Durch gezielte Interventionen und ein besseres Verständnis ihrer Entscheidungsmechanismen können zukünftige Generationen von LLMs jemals geselligere, koordinativ stärkere und damit menschlicher wirkende Partner in der digitalen Welt werden.