In der heutigen Ära der Datenverarbeitung und künstlichen Intelligenz spielt die effiziente Berechnung von Vektorähnlichkeiten eine zentrale Rolle. Ob in der Bild- und Sprachverarbeitung, im maschinellen Lernen oder bei Empfehlungssystemen – präzise und schnelle Distanz- und Ähnlichkeitsberechnungen sind entscheidend, um große Datenmengen performant zu analysieren und nutzbar zu machen. Hsdlib, eine neue C-Bibliothek, bietet hierfür eine beeindruckende Antwort, indem sie moderne SIMD-Architekturen nutzt, um die Performanz signifikant zu steigern. Bei Hsdlib handelt es sich um eine schlanke und hochperformante Bibliothek, die sich auf die Berechnung von Vektordistanzen und Ähnlichkeiten spezialisiert. Die Entwickler konzentrieren sich dabei auf die wichtigsten und am häufigsten verwendeten Metriken, um Anwendern eine präzise und gleichzeitig schnelle Berechnung zu ermöglichen.
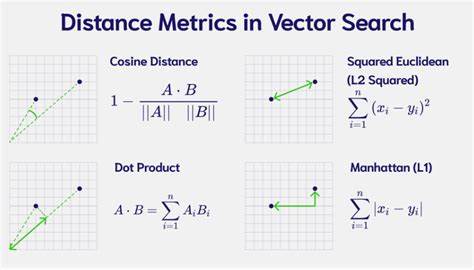
Im Kern unterstützt Hsdlib Distanzen wie die euklidische, die Manhattan- und die Hamming-Distanz. Darüber hinaus bietet die Bibliothek Berechnungen für verschiedene Ähnlichkeitsmaße an, darunter das Skalarprodukt (Dot Product), den Kosinus-Ähnlichkeitswert sowie die Jaccard-Ähnlichkeit. Besonders hervorzuheben ist die Nutzung moderner SIMD-Technologien (Single Instruction, Multiple Data), um die Rechenzeit deutlich zu verkürzen. SIMD erlaubt es, mehrere Datenpunkte parallel in einem einzigen Befehl zu verarbeiten, was bei Vektoroperationen zu enormen Geschwindigkeitsgewinnen führen kann. Hsdlib unterstützt verschiedene SIMD-Instruktionssets wie AVX, AVX2, AVX512, NEON und SVE.
Diese Multi-Plattform-Unterstützung macht die Bibliothek sowohl auf modernen x86-Systemen als auch auf ARM-basierten Geräten hoch performant einsetzbar. Die Relevanz von SIMD für die Vektorverarbeitung ist nicht zu unterschätzen. Traditionelle iterativen Methoden zur Berechnung von Distanzen sind oft durch die sequentielle Abarbeitung einzelner Vektorelemente limitiert. Durch SIMD kann Hsdlib hingegen viele Elemente in einem Durchgang verarbeiten, wodurch sie besonders für großdimensionale Vektoren und umfangreiche Datensätze signifikante Zeitersparnisse bietet. Für Datensätze, die Millionen oder gar Milliarden von Vektorvergleichen erfordern, ist eine solche Beschleunigung entscheidend.
Ein weiterer Vorteil von Hsdlib ist seine schlanke Implementierung in C. Dies gewährleistet maximale Kontrolle über Speicher und Rechenressourcen und macht die Bibliothek zu einer ausgezeichneten Wahl für systemnahe Anwendungen oder Embedded Systeme. Gerade in Szenarien, in denen Performance und geringe Latenz oberste Priorität haben, wie beispielsweise bei Echtzeit-Datenanalysen oder in intelligenten IoT-Geräten, kann Hsdlib punkten. Die Open-Source-Verfügbarkeit auf GitHub ermöglicht es Entwicklern, die Bibliothek nicht nur einzusetzen, sondern auch nach eigenen Bedürfnissen anzupassen und zu erweitern. Dieses transparente und kollaborative Modell fördert Innovationen und hilft dabei, Hsdlib stetig an neue Anforderungen und Hardware-Entwicklungen anzupassen.
Darüber hinaus ist die Benutzerfreundlichkeit ein wichtiges Merkmal von Hsdlib. Trotz seiner Komplexität sorgt die API für eine leichte Integration in bestehende Projekte. Die Dokumentation ist übersichtlich und praxisorientiert, sodass auch Entwickler, die nicht tief in die SIMD-Technik einsteigen wollen, schnell funktionierende Lösungen umsetzen können. Dies erleichtert den Einstieg und beschleunigt die Anwendungsentwicklung. Hsdlib ist auch aus Sicht der Forschung und Entwicklung relevant.
Viele fortgeschrittene Machine-Learning-Modelle basieren auf der schnellen Verarbeitung von Vektordaten. Durch die Verwendung einer robusten und effizienten Backend-Bibliothek wie Hsdlib können Forscher und Entwickler komplexe Algorithmen in kürzerer Zeit trainieren und evaluieren. Gerade im Bereich der Suche mit Vektoreinbettungen und bei der Ähnlichkeitssuche in großen Datenbanken bietet sich das Potenzial der Bibliothek besonders an. Ein weiterer Aspekt, der die Attraktivität von Hsdlib erhöht, ist die Unterstützung verschiedener Distanzen und Ähnlichkeiten. Die euklidische Distanz gilt als Standard in vielen Anwendungsfällen, etwa bei klassischen Clustering-Algorithmen und k-NN-Suchen.
Daneben sind die Manhattan- und Hamming-Distanzen besonders bei diskreten oder binären Daten nützlich, da sie andere Eigenschaften messen. Die Möglichkeit, aus verschiedenen Ähnlichkeitsmaßen zu wählen, erlaubt eine flexible Anpassung an unterschiedliche Problemstellungen. So kann beispielsweise die Jaccard-Ähnlichkeit in Informationen mit Mengenbezug angewandt werden, während der Kosinus-Ähnlichkeitswert oft im Text- oder Vektorraumanalysen verwendet wird. Zusammenfassend stellt Hsdlib eine wichtige Erweiterung der Entwicklerwerkzeuge dar – insbesondere für jene, die auf Performance und Flexibilität bei der Vektorverarbeitung angewiesen sind. Durch die Kombination aus schlanker C-Implementierung, umfassender SIMD-Unterstützung und vielseitigen Metriken ist Hsdlib prädestiniert dafür, in vielen Bereichen der datengetriebenen Forschung und Praxis eine Schlüsselrolle einzunehmen.
Die Zukunft der Vektorberechnung wird zunehmend von effizienter Hardwarebeschleunigung geprägt sein. Bibliotheken wie Hsdlib zeigen, wie tiefgehendes technisches Know-how und moderne Prozessorfunktionen genutzt werden können, um bestehende Grenzen der Datenanalyse zu überwinden. Entwickler, die auf Geschwindigkeit und Genauigkeit angewiesen sind, finden mit Hsdlib ein wertvolles Werkzeug, das auf den neuesten Stand der Technik setzt und sowohl auf Desktops als auch auf mobilen Plattformen performante Lösungen ermöglicht. Wer sich näher mit der Bibliothek beschäftigen möchte, kann Hsdlib kostenfrei über GitHub herunterladen und ausprobieren. Die aktive Community sorgt dafür, dass die Bibliothek kontinuierlich weiterentwickelt wird und neue Prozessortypen und Algorithmusoptimierungen in Zukunft hinzukommen.
In einer Zeit, in der Daten in nie dagewesenem Ausmaß anfallen und die Nachfrage nach Echtzeitanalysen wächst, bietet Hsdlib eine smarte, schnelle und flexible Lösung für eine der wichtigsten Herausforderungen moderner Datenverarbeitung – die effiziente Berechnung von Vektorähnlichkeiten.