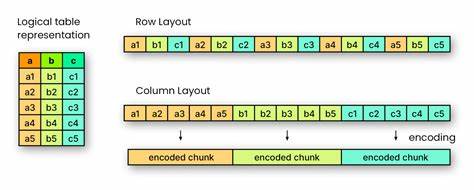
Die digitale Ära bringt stetig wachsende Datenmengen mit sich, die effizient gespeichert, verwaltet und analysiert werden müssen. In diesem Kontext spielt das Datenformat Apache Parquet eine zentrale Rolle, vor allem im Bereich der spaltenorientierten Datenverarbeitung. Um die Bedeutung von Parquet zu verstehen, ist es notwendig, zunächst den Unterschied zwischen zeilenorientierten und spaltenorientierten Datenformaten zu beleuchten. Zeilenorientierte Formate, wie beispielsweise CSV oder JSON, speichern die Daten sequenziell pro Datensatz. Das bedeutet, sämtliche Informationen eines Datensatzes – beispielsweise Name, Preis, Zustand und Menge eines Artikels – werden direkt nacheinander abgelegt.
Diese Struktur erleichtert das Lesen und Schreiben vollständiger Datensätze und ist deshalb besonders für Anwendungen im Bereich der Transaktionsverarbeitung (OLTP) geeignet. Ein wesentlicher Vorteil zeilenorientierter Formate liegt darin, dass sie vergleichsweise leicht verständlich sind und sich direkt auf die Originaldatensätze beziehen. Somit sind sie gut geeignet, wenn häufig auf vollständige Datensätze zugegriffen wird oder diese regelmäßig verändert werden. Allerdings zeigt sich bei Analyseaufgaben eine Schwäche: Wird nur ein einzelnes Feld aus vielen Datensätzen benötigt – beispielsweise die Gesamtanzahl aller vorhandenen Artikel – müssen dennoch sämtliche Datensätze gelesen werden. Dies führt zu einer hohen Rechen- und Speicherbelastung und kann die Performance stark beeinträchtigen.
Vor diesem Hintergrund kommen spaltenorientierte Datenformate ins Spiel. Parquet ist ein Beispiel für ein solches Format und wurde speziell für analytische Anwendungsfälle (Online Analytical Processing, OLAP) entwickelt, bei denen häufig nur bestimmte Felder aus großen Datenbeständen ausgewertet werden. Im Gegensatz zum zeilenorientierten Ansatz werden beim spaltenorientierten Format alle Werte einer Spalte zusammengefasst gespeichert. So sind beispielsweise sämtliche Preise oder Mengen eines Datensatzes fortlaufend abgespeichert. Dies ermöglicht sehr effiziente Leseoperationen, wenn nur wenige Spalten benötigt werden – der Zugriff erfolgt gezielt und ohne das Auslesen unnötiger Daten.
Anders formuliert: Analysen, die zum Beispiel die Summe aller Mengen ermitteln sollen, können in Parquet deutlich schneller und ressourcenschonender durchgeführt werden als mit einem zeilenorientierten Format. Neben Performancevorteilen bietet die Spaltenspeicherung auch bessere Kompressionsmöglichkeiten, da ähnliche Daten oft in einer Spalte gebündelt werden. Dies reduziert nicht nur den Speicherbedarf, sondern kann auch die Ein- und Ausgabezeit beim Lesen oder Schreiben der Daten verbessern. Daher ist Parquet unter Anbietern großer Datenplattformen und in der maschinellen Lern-Community sehr beliebt. So verwendet beispielsweise HuggingFace, eine prominente Plattform für datengesteuerte KI- und ML-Modelle, Parquet als Standardformat für ihre umfangreichen Datensätze.
Die Speicherung von Daten in spaltenorientierter Form ist allerdings nicht ohne Herausforderungen. Der Kern der Komplexität entsteht vor allem dann, wenn Datensätze optionale Felder oder verschachtelte Strukturen enthalten. In der Realität sind Daten oft heterogen: Einige Felder sind nur bei bestimmten Datensätzen vorhanden, andere können mehrfach vorliegen oder verschachtelte Unterfelder enthalten. Typische zeilenorientierte Formate sind relativ unproblematisch bei solchen Szenarien, da alle Informationen eines Datensatzes zusammen gespeichert werden und somit leicht abrufbar sind. Für Parquet und seine spaltenorientierte Speicherung wird dieses Problem dadurch gelöst, dass zusätzliche Metadaten – sogenannte Wiederholungs- und Definitionslevel – generiert und mitgespeichert werden.
Diese erlauben es, wiederkehrende und optionale Werte korrekt zu rekonstruieren und die Beziehungen zwischen den verschachtelten Feldern aufrechtzuerhalten. Insbesondere wenn Daten erweiterte Strukturen wie Listen oder verschachtelte Objekte enthalten, wird diese Technik notwendig, um den ursprünglichen Datensatz vollständig und fehlerfrei wiederherzustellen. Die Implementierung dieser Technologie ist jedoch komplex und stellt hohe Anforderungen an Datenbanken und Importwerkzeuge, die Parquet-Dateien verarbeiten möchten. Datenbanksysteme mit einer zeilenorientierten Speicherbasis, wie zum Beispiel Dolt – eine SQL-Datenbank mit einzigartigen Git-ähnlichen Versionskontrollfunktionen – stoßen beim Import von Parquet an technische Grenzen. Die Spaltendaten müssen zur Rekonstruktion vollständig im Speicher zusammengeführt werden, was den Importprozess langsamer und ressourcenintensiver macht als der Umgang mit zeilenorientierten Formaten.
Zudem sind unterschiedliche Parquet-Varianten mit mehreren Schachtelungsebenen oder komplexen Verschachtelungen nicht uneingeschränkt kompatibel. Nichtsdestotrotz sind Entwickler bestrebt, die Unterstützung und Kompatibilität schrittweise zu erweitern. Dabei stehen die Bedürfnisse der Nutzer im Mittelpunkt, denn die Vielfalt an Datenstrukturen im Parquet-Format ist breit gefächert. Eine vollständige Abdeckung aller Sonderfälle erfordert intensive Entwicklungsarbeit und ist angesichts der Komplexität des Formats ein langfristiges Projekt. Für viele typische Anwendungsfälle, vor allem solche mit weniger komplexen Strukturen und unkomplizierter Anwenderanforderung, lässt sich Parquet bereits verlässlich einbinden.
Von einem größeren Blickwinkel betrachtet, ist Parquet Teil einer weitreichenden Entwicklung in der Datenarchitektur. Moderne datengetriebene Unternehmen und Forschungseinrichtungen setzen zunehmend auf spaltenorientierte Speicherung und verteilte Analysesysteme, um den Anforderungen der Big Data Ära gerecht zu werden. Parquet hat sich hierbei als Industriestandard etabliert, der nicht nur hohe Leistung und Effizienz bietet, sondern auch eine breite Integration in Data Warehouses, Data Lakes und Analytics-Tools findet. Weiterhin sind die Vorteile von Parquet nicht nur technischer Natur. Die strukturierte Trennung von Daten und Metadaten sowie die Möglichkeit, mittels Kompression und verschiedenen Kodierungsverfahren Speicherplatz massiv zu sparen, machen Parquet auch ökonomisch attraktiv.
In einer Zeit, in der Rechenleistung und Speicherbudget oft kostspielige Ressourcen darstellen, sorgt Parquet für deutliche Kosteneinsparungen. Mit Blick auf die Zukunft ist zu erwarten, dass Parquet und spaltenorientierte Formate weiter an Bedeutung gewinnen. Insbesondere die stetige Weiterentwicklung im Bereich maschinelles Lernen, KI und datengetriebene Entscheidungsfindung erfordert schnelle, effiziente und flexible Datenquellen. Parquet passt aufgrund seiner Spezifikationen und der Unterstützung verschachtelter Datenstrukturen sehr gut zu diesen Anforderungen. Die Communityentwicklung und der offene Charakter des Formats fördern zudem kontinuierliche Verbesserungen und neue Features.
Abschließend lässt sich sagen, dass Parquet und die Spaltenspeicherung ein zentrales Element moderner Dateninfrastruktur darstellen. Während traditionelle zeilenorientierte Speicherformate weiterhin in bestimmten Szenarien ihre Berechtigung haben, eröffnet das Verständnis der Vor- und Nachteile von spaltenorientierten Formaten neue Möglichkeiten der Datenanalyse und -nutzung. Für Unternehmen und Entwickler empfiehlt es sich, das Potenzial von Parquet speziell im Bereich der analytischen Verarbeitung zu nutzen, um datenbasierte Geschäftsprozesse effizienter und skalierbarer zu gestalten. Die Kombination aus leistungsfähigen Tools, wachsender Communityunterstützung und adaptiver Entwicklung sorgt dafür, dass Parquet langfristig ein fester Bestandteil in der Datenwelt bleiben wird.