Mit der Veröffentlichung von Kubernetes 1.33, der sogenannten "Octarine"-Version, setzt das populäre Container-Orchestrierungssystem erneut neue Maßstäbe hinsichtlich Funktionalität und Bedienkomfort. Der Name "Octarine", inspiriert von einem magischen Farbton aus Terry Pratchetts Discworld-Romanen, symbolisiert nicht nur die besondere technische Tiefe der Neuerungen, sondern auch das Zusammenspiel vielfältiger Features, die erst beim genauen Hinsehen ihre volle Wirkung entfalten. Das Highlight der Version 1.33 liegt vor allem in der Verbesserung von Netzwerkmanagement, Ressourcenzuweisung, Speicherhandling und Skalierungsmechanismen, die zusammen helfen, Cloud-native Umgebungen ressourceneffizienter und stabiler zu gestalten.
Im Folgenden werden die bedeutendsten Neuerungen und deren Nutzen ausführlich vorgestellt. Ein Schwerpunkt liegt darauf, wie diese Features sowohl in großen multinationalen Clustern als auch bei Edge-Computing-Anwendungen zum Tragen kommen können. Besonders spannend sind die Funktionen, die bisherige Einschränkungen bei der IP-Adressverwaltung und beim Skalieren von Anwendungen lösen und damit den Alltag von Administratoren und Entwicklern deutlich erleichtern. Ein bahnbrechendes Merkmal, das nun in den stabilen Status übergeht, ist die dynamische Erweiterung mehrerer Service CIDRs. Bisher stellte das Management der IP-Adressräume für Services in einem Kubernetes-Cluster eine große Herausforderung dar, denn ist der Pool der verfügbaren Service IPs erschöpft, war eine oft komplexe Migration oder Clusterneuerstellung nötig.
Mit Kubernetes 1.33 wird es möglich, zusätzliche Service CIDRs hinzuzufügen, ohne den laufenden Cluster dahingehend zu beeinflussen. Clusterbetreiber können so ihre Service-IP-Pools flexibel erweitern und weitere Dienste reibungslos integrieren, ohne Downtime oder umfassende Umplanungen in Kauf nehmen zu müssen. Dieses Feature wurde bereits erfolgreich in Google Kubernetes Engine (GKE) produktiv eingesetzt, was seine Reife und Stabilität eindrucksvoll beweist. Die Implementierung erlaubt es, Service IPs intelligent aus mehreren CIDR-Blöcken zu beziehen, was vor allem in größeren oder multi-tenant Umgebungen erhebliche Vorteile bringt.
Technisch geschieht dies über die Definition von eigenen ServiceCIDR-Ressourcen, in denen die neuen Adressbereiche hinterlegt werden. Dieses elegant gelöste Hot-Add von IP-Addressen erinnert an die Funktionsweise von dynamischer Kapazitätserweiterung in Storage- oder Rechensystemen – ein Meilenstein für die tägliche Clusterverwaltung und Skalierung. Auch die Art und Weise, wie Traffic im Cluster verteilt wird, erhält mit der Einführung des trafficDistribution-Feldes direkt in den Service-Spezifikationen eine dringend benötigte Verbesserung. Lange Zeit war es schwierig, ohne tiefgehende Manuelle Konfigurationen zu steuern, wie eingehender Traffic auf verschiedene Endpunkte verteilt wird. Speziell das Thema Latenz und Kosten durch zonenübergreifenden Datenverkehr führte immer wieder zu Performance-Problemen und unnötigen Ausgaben.
Die neue Option "PreferClose" ermöglicht es, das Traffic-Routing so zu steuern, dass Verbindungen bevorzugt zu Endpunkten in der gleichen Verfügbarkeitszone oder Topologie geleitet werden. Das Ergebnis ist eine deutlich niedrigere Latenz, weil Kommunikationswege kürzer werden, und zugleich eine spürbare Reduktion der Netzwerkkosten durch geringeren zonenübergreifenden Datenverkehr. Diese intelligente Verkehrssteuerung erfordert lediglich die Nutzung von kube-proxy im IPVS-Modus oder Services, die Topology-Hints unterstützen – was bereits in den meisten Managed Kubernetes Umgebungen der Fall ist. Voraussetzung ist weiterhin, dass auf den Nodes geeignete Topology-Labels gepflegt werden, um den Ortsbezug sicherzustellen. Die neue Methode vereinfacht das Routing erheblich und macht bisher aufwändige Techniken wie eigene Endpoint-Controller, ExternalTrafficPolicy-Anpassungen oder der Einsatz komplexer Service-Meshes temporär überflüssig.
Damit senkt Kubernetes die Einstiegshürde für fortgeschrittenes Netzwerkmanagement massiv und bietet gleichzeitig bessere Performance out-of-the-box. Neben Netzwerk-Features ist im Bereich Storage die Stabilisierung von Volume Populators ein weiterer wichtiger Fortschritt. Das Konzept hinter Volume Populators löst ein häufig bestehendes Problem von Unternehmensanwendern: Wie können PersistentVolumes von vornherein mit vorbefüllten Daten versehen werden? Bisher mussten aufwändige Workarounds, wie manuelle Kopien oder klonbasierte Workflows, genutzt werden, was oft fehleranfällig ist und das Deployment verzögert. Kubernetes 1.33 erlaubt nun offiziell, Datenquellen in Form spezieller CRDs (Custom Resource Definitions) als Vorlagen für PVCs zu verwenden.
Die VolSync-Komponente ist ein prominentes Beispiel dafür, wie ein Controller automatisch Daten aus einem ReplicationDestination-Objekt auf ein neues Volume überträgt. Dadurch wird ein PVC erst dann als gebunden (bound) markiert, wenn das Volume komplett mit den referenzierten Daten gefüllt ist. Anwendungen können somit sicher starten, ohne auf manuelle Schritte warten zu müssen. Das Zusammenspiel von CSI-Treibern, Volumen-Populatorcontrollern und Kubernetes API erfolgt dabei nahtlos und basiert auf der bekannten PVC-Ressource – eine smarte Erweiterung bestehender Mechanismen. Die Einführung dieser Funktion stellt insbesondere für die Entwicklung und den Betrieb von Demo-Umgebungen, Standby-Setups oder genau kontrollierten Datenständen einen echten Gewinn dar.
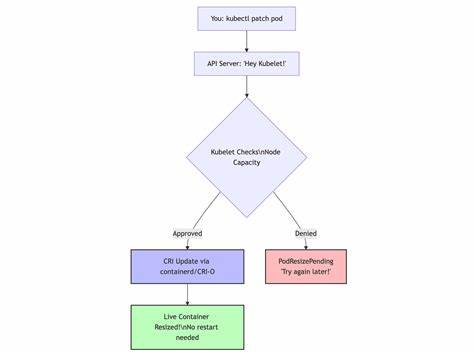
Um die Funktion nutzen zu können, muss lediglich die Feature Gate „AnyVolumeDataSource“ aktiviert werden und die passenden Controller und CRDs installiert sein. So profitieren sowohl Entwickler als auch Cluster-Administratoren von einem optimierten Speicher-Handling. Ein absoluter Game-Changer im Bereich der Ressourcenverwaltung ist das nun im Beta-Status verfügbare In-Place Pod Vertical Scaling. Die Fähigkeit, Ressourcenanforderungen und Limits von laufenden Pods live anzupassen, ohne diese neu starten zu müssen, revolutioniert den Umgang mit dynamischen Workloads. Bisher mussten Änderungen an Ressourcenprofilen mit einem Podneustart verbunden sein, was das Risiko von Ausfallzeiten, Scheduling-Aufwänden und einer erhöhten Komplexität in der Planung bedeutete.
Mit der neuen Funktion kann der Vertical Pod Autoscaler (VPA) unter Verwendung der neuen Update Policy „InPlaceOrRecreate“ versuchen, Ressourcenanpassungen live durchzuführen. Sollte dies nicht möglich sein, erfolgt erst im Bedarfsfall ein Neustart oder eine Eviction. Die Kontrolle der Ressourcenerweiterung läuft dabei über Policies, die steuern, wann ein Restart wirklich notwendig ist, beispielsweise bei CPU oder Memory Änderungen. Das Ergebnis ist eine deutlich effizientere Nutzung der Rechenkapazitäten und eine bessere Anpassung an Lastschwankungen, ohne die Verfügbarkeit zu gefährden. Allerdings gibt es einige wichtige Hinweise: PodDisruptionBudgets werden nicht automatisch berücksichtigt, StatefulSets erfordern besondere Aufmerksamkeit und Integrationen mit Deployment-Systemen wie ArgoCD oder Flux sind zu prüfen, um unerwünschte Änderungen zu verhindern.
Dennoch ebnet dieses Feature den Weg für fein granulare Ressourcenzuweisungen in Echtzeit und harmoniert ideal mit intelligenten Auto-Scaler-Anwendungen und Cluster-Provisionern wie Karpenter. Im Bereich Sicherheit und Authentifizierung kann mit dem Alpha-Feature "Service Account Token for Image Pulls" ein weiterer, bedeutender Schritt in Richtung automatisierter, sicherer Workload-Identitäten beobachtet werden. Ziel ist es, die bisher weit verbreitete Nutzung von statischen Image Pull Secrets durch ein Token-basiertes System abzulösen, das Service Accounts verwendet, um Images authentifiziert und dynamisch zu laden. Hierbei integriert sich der Kubelet Credential Provider mit einem innovativen Token-Flow, der kurzlebige, auf den Pod zugeschnittene Token an externe Systeme weiterleiten kann, die wiederum temporäre Zugriffsdaten für Container-Registries bereitstellen. Dieses Vorgehen passt zum generellen Trend in der Cloud-Native-Welt, statischen Credentials den Kampf anzusagen und stattdessen auf ein sicheres, identitätsbasiertes, kurzlebiges Modell zu setzen.
Transparenz und Komfort für Entwickler steigen dadurch enorm, denn Image-Pulls finden künftig ohne manuelle Handhabe von Secrets statt. Die praktische Umsetzung erfordert eine passende Credential Provider Plugin-Implementierung, die zum Zeitpunkt der Veröffentlichung noch nicht offiziell verfügbar ist, stellt aber den Ausgangspunkt für zukünftige Verbesserungen in der Container-Sicherheitsinfrastruktur dar. Auch die Horizontal Pod Autoscaler (HPA) bekommen mit einem neuen Alpha-Feature eine willkommen Anpassungsmöglichkeit. Bislang war die Toleranzschwelle, die bestimmt, ab wann Hoch- und Runterskalierungen erfolgen, global eingestellt und betrug etwa 10 Prozent. In der Praxis führte das bei wenig kritischen Workloads häufig zu verzögerten Skalierungen, während hochkritische Anwendungen oft eine präzisere Reaktion benötigten.
Mit der Einführung konfigurierbarer Toleranzen pro HPA kann jetzt das Skalierungsverhalten individueller auf die jeweiligen Bedürfnisse abgestimmt werden. So lassen sich differenzierte Werte für Skalierungsaktionen nach oben und unten definieren, um beispielsweise schnelle Skalierungen bei Lastspitzen und langsameres Skalieren bei Abfall der Nachfrage zu erreichen. Das sorgt für besser ausbalancierte Ressourcenplanung, Schutz vor unnötigem Flapping und eine insgesamt gesteigerte Stabilität großer Cluster-Anwendungen. Die Konfiguration erfolgt über ein neues Feld in der Skalierungs-Definition, unterstützt unterschiedliche Metriktypen und erfordert die Aktivierung der entsprechenden Feature Gates. In Summe zeigt die Kubernetes 1.
33 Version, wie die Orchestrierungstechnologie sich vom rein statischen Infrastruktur-Tool hin zu einem intelligenten, anwendungsorientierten System entwickelt, das immer flexibler und selbstoptimierender ist. Die Kombination aus dynamischer IP-Verwaltung, intelligenter Traffic-Steuerung, vereinfachtem Speicher-Handling und adaptiven Skalierungsmechanismen repräsentiert eine für Administratoren wie Entwickler willkommene Erleichterung. Der bisher oft notwendige Mehraufwand für manuelle Konfiguration weicht modernen, automatisierbaren Prozessen, die nachhaltig helfen, Cloud-native Systeme stabiler, kosteneffizienter und wartungsfreundlicher zu betreiben. Darüber hinaus dürften Tools wie mirrord, die es erlauben, lokale Prozesse transparent in einem Live-Kubernetes-Kontext auszuführen, die Akzeptanz und Erkundung solcher Features weiter beschleunigen. Sie bieten eine einfache Möglichkeit, neue Versionen und Funktionen gefahrlos zu testen und Entwicklungs- sowie Debugging-Zyklen enger zu gestalten.
Wer Kubernetes 1.33 zu nutzen beginnt, entdeckt schnell, dass die echten Highlights nicht nur in einzelnen Features liegen, sondern in der Art und Weise, wie diese zusammenspielen, um moderne Cloud-native Anwendungslandschaften agiler und zuverlässiger zu machen. So wie das magische "Octarine" die Sichtweise von Hexen und Zauberern in Terry Pratchetts Geschichten erweitert hat, bringt Kubernetes 1.33 systemische Erweiterungen, die sich in der Praxis zwar subtil auswirken, aber langfristig einen großen Unterschied machen. Gerade in einer Zeit, in der Orchestrierung und Infrastruktur immer näher an das Anwendungsgeschehen heranrücken, sind diese neuen Möglichkeiten eine willkommene Bereicherung.
Anwender können damit heute schon die Weichen für die zunehmend komplexen, verteilten und dynamischen Systeme von morgen stellen. Die Zukunft der Container-Orchestrierung ist dynamisch, sicher und smart – mit Kubernetes 1.33 sind wir einen großen Schritt weiter auf diesem aufregenden Weg.