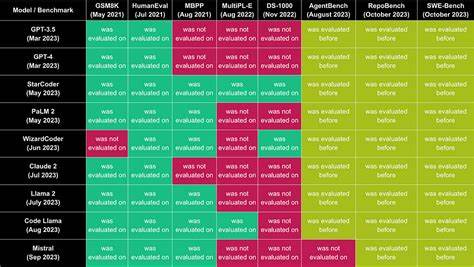
Die rasante Entwicklung großer Sprachmodelle (Large Language Models, LLMs) hat die Welt der Künstlichen Intelligenz (KI) revolutioniert. Mit immer leistungsfähigeren Modellen steht die Frage im Mittelpunkt, wie diese präzise bewertet und verglichen werden können, um die besten Lösungen für praktische Anwendungen zu identifizieren. Hier kommt das LLM Meta-Leaderboard ins Spiel, das die Leistung führender Modelle auf Basis einer Vielzahl von Benchmarks miteinander vergleicht. Das Meta-Leaderboard bietet eine aggregierte Übersicht, die über einzelne Testkategorien hinausgeht und stattdessen eine ganzheitliche Bewertung der Modelle ermöglicht. Die Grundlage hierfür bilden im Durchschnitt die 28 besten Benchmarks, die verschiedene Facetten und Herausforderungen der Sprachmodellierung abdecken.
Die Bedeutung eines solchen Meta-Leaderboards liegt auf der Hand: Es ist nicht nur ein Referenzrahmen für Entwickler, Forscher und Unternehmen, sondern auch ein Indikator für die allgemeine Leistungsfähigkeit von LLMs in unterschiedlichen Anwendungsszenarien. Anders als einzelne Benchmarks, die sich oft auf spezifische Aufgaben wie Textverständnis, Fragebeantwortung oder maschinelles Übersetzen konzentrieren, berücksichtigt das Meta-Leaderboard eine breite Palette von Testaufgaben, um ein umfassenderes Bild zu zeichnen. Dadurch wird sichergestellt, dass die Bewertung vielseitig und fair erfolgt, ohne durch einzelne Spezialbereiche verzerrt zu werden. Bei der Auswahl der 28 besten Benchmarks wurde besonders auf die Relevanz und Aktualität der Tests geachtet. Diese Benchmarks setzen sich aus renommierten Datensätzen und Herausforderungen zusammen, die die neuesten Fortschritte und Grenzen der KI abbilden.
Sie variieren von komplexen NLU-Aufgaben (Natural Language Understanding) über generative Aufgaben bis hin zu spezialisierten Domänen wie juristischem Textverständnis oder wissenschaftlichen Frage-Antwort-Systemen. Die Vielfalt dieser Benchmarks ist entscheidend, da sie sicherstellen soll, dass das Meta-Leaderboard möglichst repräsentativ für das breite Spektrum an Einsatzmöglichkeiten von Sprachmodellen bleibt. Die Aggregation der Ergebnisse aus den 28 Benchmarks erfolgt nach einem klar definierten Verfahren, das Verzerrungen minimiert und die Vergleichbarkeit der Modelle garantiert. Jedes Sprachmodell wird auf den einzelnen Benchmarks getestet, und die Ergebnisse werden normiert, um unterschiedliche Skalen und Schwierigkeitsgrade zu harmonisieren. Anschließend erfolgt eine gewichtete Mittelung, die Aufmerksamkeit auf die Bedeutung und den Schwierigkeitsgrad der einzelnen Benchmarks legt.
Dadurch entsteht eine Metrik, die sowohl die Tiefe als auch die Breite der Modellkompetenz abbildet. Die Bedeutung dieser umfassenden Bewertung zeigt sich nicht nur in der reinen Rangfolge der Modelle. Sie liefert auch wichtige Hinweise für die Weiterentwicklung der KI-Technologie. Entwickler können Schwächen in bestimmten Aufgabenbereichen erkennen und gezielt daran arbeiten, während Unternehmen besser einschätzen können, welche Modelle für ihre spezifischen Anwendungsfälle am besten geeignet sind. So ermöglicht das Meta-Leaderboard eine datengestützte Entscheidungsfindung, die den Innovationsprozess beschleunigt und Investitionen zielgerichteter macht.
Darüber hinaus beleuchtet das Meta-Leaderboard die Dynamik des Wettbewerbs in der Forschungsgemeinschaft. Es fördert Transparenz und Vergleichbarkeit, was insbesondere in einem schnelllebigen Feld wie der KI enorm wichtig ist. Offene Benchmarks und Rankings motivieren Forscher dazu, ihre Modelle kontinuierlich zu verbessern und neue Ansätze zu erproben. Dieser Wettbewerb trägt dazu bei, den Fortschritt zu beschleunigen und Grenzen in der Sprachmodellierung immer weiter zu verschieben. Ein weiterer Vorteil des Meta-Leaderboards liegt in der Möglichkeit, auch neue Modelle oder Innovationen schnell und umfassend einzuschätzen.
Statt isolierte Tests abschließen zu müssen, kann die Performance über die verschiedenen Benchmarks hinweg gleichzeitig analysiert werden. Dies ist besonders wichtig angesichts der Vielfalt der Modelle, die heute auf dem Markt verfügbar sind – von generativen Großmodellen über spezialisierte Systeme bis hin zu kleineren, effizienten Varianten. Allerdings gibt es auch Herausforderungen bei der Umsetzung eines solchen Meta-Leaderboards. Die Auswahl der Benchmarks muss ständig überprüft und angepasst werden, um auf neue Anforderungen und Technologien zu reagieren. Zudem muss die Metrik transparent und nachvollziehbar gestaltet sein, um Vertrauen bei Anwendern und Entwicklern zu schaffen.