In der heutigen digitalen Ära, in der Datenmenge und -komplexität exponentiell wachsen, hat sich die verteilte Datenverarbeitung zu einem unverzichtbaren Bestandteil moderner IT-Infrastrukturen entwickelt. Unternehmen aller Größenordnungen suchen nach effektiven Methoden, um große Datenmengen schnell, zuverlässig und skalierbar zu analysieren und daraus wertvolle Erkenntnisse zu gewinnen. Die moderne verteilte Datenverarbeitung vereint eine Vielzahl von Technologien, Frameworks und Architekturen, die gemeinsam eine robuste Plattform bilden, um den Ansprüchen heutiger Datenanwendungen gerecht zu werden. Grundsätzlich zielt die verteilte Datenverarbeitung darauf ab, Rechenaufgaben und Datenanalyseprozesse auf mehrere Rechner oder Knoten zu verteilen, um parallele Verarbeitung und somit schnellere Ergebnisse zu ermöglichen. Dies ist besonders wichtig im Zeitalter von Big Data, in dem massive Datenströme aus verschiedenen Quellen wie IoT-Geräten, sozialen Medien, Geschäftssystemen und mehr verarbeitet werden müssen.
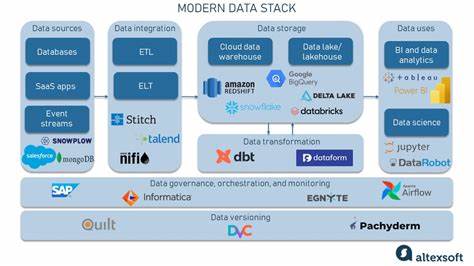
Die Herausforderung liegt dabei nicht nur in der Skalierbarkeit, sondern auch in der Gewährleistung von Ausfallsicherheit, Konsistenz und niedriger Latenz. Zu den zentralen Komponenten des modernen verteilten Datenverarbeitungs-Stacks zählen verteilte Dateisysteme oder Storage-Lösungen, die als Fundament für die Speicherung großer Datenmengen dienen. Technologien wie Hadoop Distributed File System (HDFS) haben lange Zeit eine zentrale Rolle gespielt, dennoch bieten mittlerweile neue Cloud-native Speicherlösungen wie Amazon S3 oder Google Cloud Storage eine flexible und kosteneffiziente Alternative. Diese Speicherlösungen ermöglichen es Anwendungen, Daten in beliebiger Größe zu speichern und schnell darauf zuzugreifen, ohne sich um die zugrunde liegende Infrastruktur kümmern zu müssen. Auf der Verarbeitungsebene dominieren Frameworks wie Apache Spark und Apache Flink das Geschehen.
Spark hat sich als eines der vielseitigsten Tools etabliert, da es sowohl Batch-Verarbeitung als auch Echtzeit-Streaming unterstützt und eine breite Palette von APIs für verschiedene Programmiersprachen bietet. Flink wiederum glänzt durch seine Fähigkeit, komplexe Streaming-Datenströme mit niedriger Latenz und hoher Genauigkeit zu verarbeiten, was es gerade in Anwendungsfällen mit strengen Echtzeitanforderungen unverzichtbar macht. Neben der reinen Datenverarbeitung haben sich auch Messaging- und Streaming-Plattformen als wesentliche Bausteine etabliert. Apache Kafka ist hierbei ein besonders prominentes Beispiel. Als verteilte Streaming-Plattform ermöglicht Kafka das Handling riesiger Datenströme mit hoher Fehlertoleranz und Skalierbarkeit.
Unternehmen nutzen Kafka häufig als zentrales Nervensystem für ihre Datenpipelines, um Daten in Echtzeit zwischen verschiedenen Komponenten auszutauschen und zu verarbeiten. Containerisierung und Orchestrierung sind ein weiterer bedeutender Teil des modernen Stacks. Mit Technologien wie Docker und Kubernetes können verteilte Datenverarbeitungsanwendungen in isolierten Umgebungen betrieben und auf Clustern skaliert werden. Kubernetes bietet außerdem automatisierte Verwaltung, Self-Healing und einfache Skalierung, was für den Betrieb von komplexen Big-Data-Anwendungen entscheidend ist. Die Möglichkeit, Ressourcen effizient zu planen und Workloads flexibel zu verteilen, ermöglicht es Teams, ihre Infrastruktur optimal auszunutzen.
Auf Cloud-Plattformen wie AWS, Google Cloud oder Microsoft Azure sind viele dieser Technologien als verwaltete Dienste verfügbar, was den Einstieg erleichtert und den Betrieb vereinfacht. Dieser Cloud-native Ansatz bietet zudem Vorteile wie automatische Skalierung, hohe Verfügbarkeit und integrierte Sicherheitsmechanismen. Dienste wie AWS EMR für Spark, Google Cloud Dataflow für Flink-basierte Verarbeitungen oder Azure Event Hubs für Streaming erleichtern es Unternehmen, ihre Dateninfrastruktur flexibel und kosteneffizient zu gestalten. Auch Datenbanken und spezialisierte Speicherlösungen sind Teil des Ökosystems. NoSQL-Datenbanken wie Apache Cassandra oder MongoDB unterstützen verteilte Speicherung und bieten niedrige Latenzen für transaktionale und analytische Workloads.
Zeitreihendatenbanken wie InfluxDB oder Prometheus sind besonders geeignet, um zeitbasierte Daten schnell zu speichern und auszuwerten, was für Monitoring- und IoT-Anwendungen essentiell ist. Ein immer wichtiger werdender Aspekt in der verteilten Datenverarbeitung ist die Datenqualität und Governance. Tools und Frameworks unterstützen dabei, Datenkonsistenz sicherzustellen, Metadaten zu verwalten und Compliance-Anforderungen zu erfüllen. Data Catalogs und Governance-Lösungen helfen Organisationen dabei, ihre Datenbestände besser zu verstehen, transparente Datenpipelines zu erzeugen und regulatorischen Vorgaben gerecht zu werden. Nicht zuletzt verändert die zunehmende Bedeutung von Künstlicher Intelligenz und Machine Learning die Anforderungen an den Datenverarbeitungsstack.