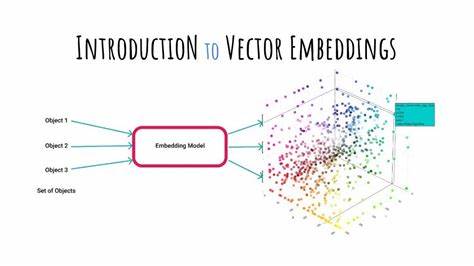
Künstliche Intelligenz (KI) prägt heute immer stärker unseren Alltag und nimmt in den unterschiedlichsten Bereichen eine bedeutende Rolle ein – von Suchmaschinen über Chatbots bis hin zu Übersetzungsdiensten. Doch das Herzstück vieler moderner KI-Systeme bleibt für viele eine abstrakte黑Box. Ein Schlüssel zum Verständnis moderner KI liegt jedoch in einem simplen, doch mächtigen Konzept: Embeddings. Diese sind, vereinfacht gesagt, die Art und Weise, wie Computer Bedeutung als Zahlen darstellen, um mit ihr rechnen und arbeiten zu können. Embeddings ermöglichen es Maschinen, die tieferen Zusammenhänge innerhalb von Informationen zu erfassen, ohne den überwältigenden Aufwand expliziter Programmierung oder komplexer Regeln.
Dabei ist erstaunlich, dass man Embeddings auch ohne tiefgreifende mathematische Vorkenntnisse verstehen kann – eine Vorstellung, die wir im Folgenden vertiefen wollen. Ein intuitiver Einstieg für alle, die sich für moderne KI interessieren und wissen wollen, wie Maschinen tatsächlich „bedeutungsvoll denken“. Stellen wir uns einen einfachen Fall vor, der den Kern des Begriffs Embedding erhellen kann: die Klassifizierung von Hunden anhand ihrer Eigenschaften wie Größe und Intelligenz. Hier kann man jedem Hund zwei Zahlen zuordnen – etwa eine Größe von 1 bis 5 und eine Intelligenzbewertung von ebenfalls 1 bis 5. Jedes Tier wird in einem zweidimensionalen Raum durch einen Punkt dargestellt, dessen Koordinaten diese Werte sind.
Die Entfernung zwischen zwei Punkten zeigt an, wie ähnlich sich diese Hunde bezüglich ihrer Merkmale sind. So ließe sich berechnen, dass ein großer, intelligenter Great Dane näher an einem Beagle oder einem Border Collie liegt als an einem kleinen, weniger intelligenten Shih Tzu. Dieser einfache Vektorraum ist ein sehr frühes Beispiel für Embeddings: Datenpunkte werden durch Zahlen in einem Raum repräsentiert, anhand dessen man ihre Ähnlichkeit bestimmen kann. Dies funktioniert nicht nur in zwei Dimensionen, sondern kann beliebig viele Attribute umfassen, wodurch komplexe Objekte mit vielen Eigenschaften abgebildet werden können. Wenden wir dieses Konzept auf Texte an, wird es schon deutlich spannender und herausfordernder.
Bücher beispielsweise können anhand der Häufigkeit ihrer Wörter als Vektoren dargestellt werden. Hierbei wird jedes Buch mit einer sehr langen Liste von Zahlen beschrieben, wobei jede Zahl die Anzahl der Vorkommen eines bestimmten Wortes angibt. Dies nennt man den „Bag of Words“-Ansatz. Ein Nachteil hierbei ist jedoch, dass diese Vektoren sehr hochdimensional sind und nicht unbedingt die Bedeutung der Wörter oder der Texte widerspiegeln. So wird beispielsweise die Bedeutung des Wortes „bark“ (englisch für „Bellen“ oder „Baumrinde“) nicht erkannt.
Die Bücher werden nur anhand reiner Wortzahlen sortiert, ohne zu erfassen, was die Wörter bedeuten oder in welchem Zusammenhang sie stehen. Um diese Herausforderung anzugehen, entwickelte sich die Methode TF-IDF, die häufige, wenig aussagekräftige Wörter gewichtet und seltenere, wichtigere Wörter hervorhebt. Dadurch verbessert sich die Differenzierung zwischen Texten, denn „stellvertretende“ Wörter wie „a“ oder „the“ werden nicht übermäßig berücksichtigt. Doch auch damit sind die Grenzen erreicht: Das “Bag of Words”-Modell ignoriert weiterhin wichtige Aspekte wie die Reihenfolge der Wörter und die Beziehungen zwischen ihnen sowie die Tatsache, dass verschiedene Wörter mit ähnlicher Bedeutung thematisch eng zusammenhängen. Wie lassen sich diese Probleme lösen? Die Antwort lautet Embeddings, die von Maschinen mit Hilfe von neuronalen Netzwerken gelernt werden, anstatt manuell festgelegt zu sein.
Die Methode „Word2Vec“ war ein Durchbruch auf diesem Gebiet. Dabei werden Wörter durch dichte, niedrigdimensionale Vektoren dargestellt, die Bedeutung und Kontext in sich tragen und so sehr viel mehr als nur einfache Häufigkeiten ausdrücken. Der Clou: Wörter, die oft in ähnlichen Kontexten vorkommen, erhalten ähnlich aussehende Vektoren. „Puppy“, „Dog“ und „Pooch“ zum Beispiel landen nahe beieinander im Raum der Bedeutung. Dies lässt sich mit dem Gedanken erklären „Ein Wort ist bekannt durch seine Umgebung“ – je ähnlicher der Kontext, desto ähnlicher die Vektoren.
Word2Vec reduziert darüber hinaus die hohe Dimensionalität der Wortvektoren von zehntausenden auf wenige hundert Werte – was Arbeitsspeicher spart und Berechnungen deutlich beschleunigt. Ein weiterer verblüffender Effekt ist, dass die Vektoren auch komplexe semantische Beziehungen abbilden können. Ein oft zitiertes Beispiel ist, dass „King“ minus „Man“ plus „Woman“ den Vektor für „Queen“ ergibt. Solche mathematischen Operationen zeigen, dass die Netzwerke nicht nur Wörter lernen, sondern auch abstrakte Bedeutungen und Beziehungen darin verankern. Die Transformation von einzelnen Wörtervektoren zu Satz- oder Absatz-Embeddings erfolgt häufig durch Mittelung oder komplexere Kombinationen.
Doch diese einfachen Mittel führen dazu, dass Reihenfolge und Syntax verloren gehen. Um dieses Problem zu beheben setzen moderne Ansätze auf neuronale Netzwerke, die Sequenzen verstehen können – sogenannte Recurrent Neural Networks (RNNs), Long Short-Term Memory (LSTM) oder Gated Recurrent Units (GRUs). Sie verarbeiten Text in der Reihenfolge der Wörter, wodurch der Kontext bewahrt und die Reihenfolge beachtet wird. Allerdings leiden auch diese Verfahren unter dem Problem, dass Informationen früherer Wörter im Verlauf abnehmen. Ein bahnbrechender Schritt erfolgte mit der Erfindung der Transformer-Modelle, die mit Hilfe von Aufmerksamkeit („Attention“) arbeiten.
Diese Technologie bewirkt, dass jeder Teil eines Textes alle anderen Teile simultan in Betracht zieht und so wichtige Zusammenhänge nicht verloren gehen. Der Fokus liegt dabei auf den relevanten Teilen, die das Verständnis des Textes ausmachen. Transformer-Modelle sind heute die Grundlage großer Sprachmodelle wie GPT von OpenAI, aber eben auch jener Embeddings, die wir für vielfältige KI-Anwendungen nutzen. Ein weiterer Aspekt ist das Arbeiten mit Token anstelle ganzer Wörter. Tokens sind kleine Stücke von Wörtern oder Buchstabenfolgen, die vom Modell während des Trainings automatisch bestimmt werden.
Dadurch kann das Modell Wörter erkennen, die es vorher nie gesehen hat, und sogar mit Tippfehlern umgehen. Tokenisierung hilft also, mit der enormen Vielfalt der Sprache umzugehen. Die praktische Relevanz von Embeddings zeigt sich unter anderem in der automatischen Klassifikation von Texten wie Kundenrezensionen, wo sie helfen, Emotionen und Stimmungen zuverlässig einzuschätzen, obwohl die Ausdrucksweise sehr vielfältig sein kann. Sie erlauben es, Texte mit ähnlicher Bedeutung autonom zu gruppieren, indem sie deren Vektoren im Raum vergleichen. Ein besonders spannendes Anwendungsfeld sind Vektor-Datenbanken, die darauf optimiert sind, ähnliche Vektoren schnell zu finden.
So gelingt es, auf usergenerierte Anfragen in Echtzeit passende Informationen aus riesigen Datenmengen abzurufen – die Grundlage für Systeme wie die Retrieval-Augmented Generation (RAG). Bei RAG werden relevante Textbestandteile mittels Embeddings gefunden und dem Sprachmodell bei einer Anfrage bereitgestellt, um präzise und aktuelle Antworten zu geben. Auf diese Weise kombiniert man das breite Wissen von Sprachmodellen mit konkretem, aktuellem Wissen ohne deren Halluzinationen. Abschließend lässt sich sagen, dass Embeddings essenziell sind, um die Bedeutung von Texten rechnerisch greifbar zu machen und verdeckte Zusammenhänge abzubilden. Sie ermöglichen die Interpretation großer Datenmengen durch maschinelles Lernen und sind integraler Bestandteil moderner KI-Systeme.