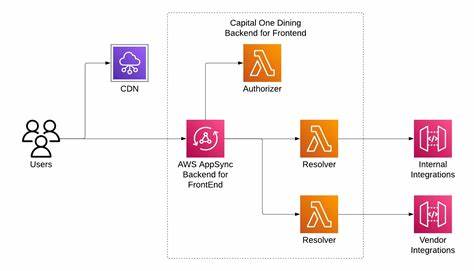
Im modernen Softwareentwicklungsumfeld gewinnt die nahtlose Verbindung zwischen Frontend und Backend immer mehr an Bedeutung. Insbesondere bei der Entwicklung von komplexen Applikationen mit vielfältigen Datenquellen entstehen Herausforderungen bezüglich Datenabruf, Datenaggregation und Performance. Klassisch wurden RESTful APIs eingesetzt, in den letzten Jahren hat GraphQL als flexible Abfragesprache großen Zuspruch gefunden. Dennoch zeigt sich, dass GraphQL nicht in allen Szenarien die beste Lösung darstellt. Hier tritt das Resolver Pattern als eine überzeugende Alternative auf den Plan, speziell im Zusammenhang mit Backend-for-Frontend (BFF)-Architekturen.
Das Resolver Pattern baut auf dem Konzept auf, bestehende REST-APIs durch erweiterbare Resolver und Post-Processing-Methoden zu ergänzen. Anstatt dem Frontend die Verantwortung zur freien Abfrage der Datenstrukturen auferlegen zu müssen, transformiert das Resolver Pattern die Datenserverlogik hin zu maßgeschneiderten, seitenorientierten RPC-ähnlichen Schnittstellen. Der Fokus liegt dabei auf der Verwendung starker Datentypen und Klassen, beispielsweise unter Nutzung von Pydantic, um strukturierte Datentypen stark typisiert bereitzustellen und gleichzeitig eine flexible Verknüpfung und Weiterverarbeitung zu ermöglichen. Einer der größten Vorteile des Resolver Patterns liegt in der besseren Handhabung assoziierter Daten und der Möglichkeit, nachgelagerte Post-Processing-Berechnungen direkt in den jeweiligen Datenklassen zu implementieren. So können Berechnungen wie Fortschrittsindikatoren, zusammengesetzte Namen oder aggregierte Statistiken bereits im Backend aufbereitet werden, bevor die Daten an den Client übermittelt werden.
Dadurch wird der Frontend-Code deutlich schlanker, und unnötige Mehrfachdatenabrufe werden vermieden. Im Vergleich zu GraphQL, das durch flexible, von Clients definierte Queries punktet, bietet das Resolver Pattern bewusst weniger Flexibilität in den Abfragen, gewinnt jedoch durch Klarheit und feste Strukturen im API-Design an Entwicklerfreundlichkeit. In internen Frontend-Backend-Integrationen, wie sie typischerweise bei BFF-Architekturen vorkommen, ist der Bedarf nach vollständig dynamischen Queries oft geringer, wodurch das Resolver Pattern hier seine vollen Stärken ausspielen kann. Ein weiteres Alleinstellungsmerkmal des Resolver Patterns ist die Unterstützung von Self-Referential-Types, also Datenstrukturen wie Baumhierarchien, die sich selbst referenzieren. Während GraphQL hier oftmals tief verschachtelte und komplexe Abfragen erfordert, übernimmt das Resolver Pattern die Tiefe der Datenstrukturen serverseitig vollständig.
Dadurch entfallen klientenseitige Ungewissheiten über die Abfragetiefe, was die Entwicklung erheblich erleichtert. Die Art der Parameterübergabe zeigt ebenfalls Unterschiede. GraphQL verwaltet Parameter zentralisiert und passt sie an die jeweiligen Query-Positionen an, was einerseits Flexibilität schafft, andererseits aber zu komplexem Management führen kann. Das Resolver Pattern hingegen gestattet die Bereitstellung globaler Kontextvariablen, die während des gesamten Resolution-Prozesses verfügbar sind. Dadurch bleibt die Parameterlogik übersichtlich und gleichzeitig leistungsfähig, um Filter und spezifische Datenzugriffe zu realisieren.
Ein nicht zu unterschätzender Vorteil des Resolver Patterns liegt in seiner Kompatibilität mit bestehenden RESTful APIs und etablierten Webframeworks wie FastAPI. Die nahtlose Integration und Erweiterbarkeit erlauben es, ohne große Architekturänderungen neue Funktionen und Views zu ergänzen. Entwickler können mithilfe von Resolvern sukzessive weitere Aggregationsschichten und Post-Processing-Schritte hinzufügen, ohne bestehende Schnittstellen zu beeinträchtigen. Aus Sicht der Frontend-Entwicklung ist der Weg über das Resolver Pattern besonders attraktiv, da mit der OpenAPI-Spezifikation automatisiert SDKs und Typdefinitionen generiert werden können. Solche automatisch erstellten Clients erleichtern die fehlerfreie Integration und verbessern die Entwicklungsgeschwindigkeit.
Im Gegensatz dazu ist GraphQL zwar auch in der Lage, Typen zu generieren, dennoch erfordert dieser Prozess in der Praxis oft zusätzliche Tools und Anpassungen, da die Typinformation eng an die dynamischen Querystruktur gebunden ist. Besonders hervorzuheben ist die Post-Processing-Fähigkeit auf jeder einzelnen Knotenebene im Resolver Pattern. Während GraphQL traditionell nur eine Top-Down-Verarbeitung zulässt, mit begrenzten oder gar keinen Möglichkeiten zur nachträglichen Datenmanipulation auf Knotenebene, ermöglicht das Resolver Pattern eine granulare Bearbeitung und Erweiterung der Datenstrukturen. So lassen sich beispielsweise an jeder Datenebene aufwendige Berechnungen, Umformungen oder Filterungen durchführen, was eine erhebliche Steigerung der Wartbarkeit und Flexibilität bedeutet. Ein praxisrelevantes Beispiel ist die Berechnung des Fertigstellungsprozentsatzes bei Aufgaben in einem Sprint.
Über das Resolver Pattern kann diese Information elegant in einer Post-Processing-Methode auf Story-Ebene aggregiert werden, basierend auf den jeweiligen Task-Daten. Dieses Vorgehen verbessert nicht nur die Übersicht, sondern reduziert auch die Übertragung unnötiger Daten zum Client. Technisch zeichnet sich das Resolver Pattern durch einen schlanken Stack aus. Die Nutzung von Pydantic zur Modellierung der Daten, FastAPI als Webframework und pydantic-resolve für das Resolver-Konzept sorgt für eine gut wartbare Pipeline ohne die Komplexität zusätzlicher Abfragesprachen. Dies ist besonders in Teams von Vorteil, die von der erhöhten Flexibilität von GraphQL profitieren möchten, ohne dessen Komplexität vollständig zu übernehmen.
Nicht zuletzt zeigen Performance-Benchmarks, dass das Resolver Pattern in vielen Fällen sogar schneller ist als GraphQL-Lösungen, da durch die feste Struktur geringere Parsing- und Aufbereitungszeiten entstehen. Die geringere Laufzeitkomplexität und die Möglichkeit zur besseren Caching-Strategien tragen weiter zur Effizienz bei. Die Architekturvorteile schlagen sich auch in der evolutionären Wartbarkeit nieder. GraphQL-Schemas können schwer zu verändern sein, wenn unbekannt ist, wie sie in verschiedenen Queries genutzt werden. Das Resolver Pattern mit seiner klaren Trennung zwischen stabilen Basismodellen und erweiterbaren View-Modellen erlaubt es hingegen, neue Datenmodelle und Funktionen schrittweise einzuführen, ohne Legacy-Code zu brechen oder bestehende Konsumenten zu beeinträchtigen.
Die Typisierung durch Pydantic sorgt zudem für eine verbesserte Entwicklererfahrung, da bereits während der Entwicklung Fehler frühzeitig erkannt werden können und klare Kontrakte definiert sind. Diese sind insbesondere bei großen Teams oder in unternehmensweiten APIs essentiell, um Kommunikationsfehler zu verhindern. Zusammenfassend lässt sich sagen, dass das Resolver Pattern eine hochgradig geeignete Alternative zu GraphQL für klassische BFF- und interne API-Integrationsszenarien darstellt. Seine Stärken liegen in der klaren, wartbaren Architektur, leistungsfähigen Post-Processing-Funktionalitäten, der einfachen Integration in bestehende REST-Frameworks und der effizienten Erzeugung von Frontend-SDKs. Dabei verzichtet es zugunsten von Qualität und Performance auf die vollkommene Query-Flexibilität von GraphQL, adressiert damit aber gezielt die Bedürfnisse interner Frontends.
Unternehmen und Entwickler, die stabile und leicht erweiterbare API-Schnittstellen benötigen und dabei besondere Anforderungen an Datenaggregation und Nachverarbeitung haben, sollten das Resolver Pattern als Alternative auf jeden Fall in Betracht ziehen. Die Zukunft der Frontend-Backend-Kommunikation im BFF-Kontext könnte so effizienter, skalierbarer und wartungsfreundlicher gestaltet werden.