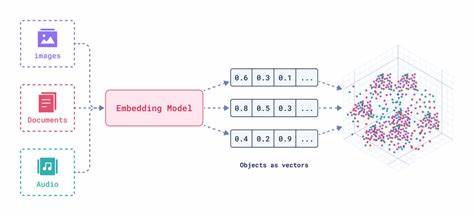
In der digitalen Ära, in der immense Mengen an Informationen täglich erzeugt werden, ist die Herausforderung zur effizienten Verarbeitung und Vernetzung technischer Dokumentation bedeutender denn je. Während große Aufmerksamkeit auf KI-gestützte Textgeneratoren wie GPT, LLaMa oder Claude gerichtet wird, bleiben Embeddings als Grundlage vieler moderner Sprachmodelle oft unterschätzt. Doch gerade sie bergen ein enormes Potenzial, um die Arbeit technischer Redakteure nicht nur zu ergänzen, sondern grundlegend zu verbessern. Embeddings sind numerische Repräsentationen von Texten in Form von hochdimensionalen Vektoren. Vereinfacht gesagt, verwandeln sie beliebige Textstücke, egal ob einzelne Worte, Absätze oder ganze Dokumente, in eine Zahlenreihe, die deren semantischen Inhalt kodiert.
Trotz der Komplexität steckt hinter diesem Verfahren ein einfacher Zweck: Texte so abzubilden, dass ihre Bedeutung mathematisch vergleichbar wird. Somit lassen sich Bedeutungsähnlichkeiten zwischen Dokumenten feststellen – ein Aspekt, der bisherige Methoden der Inhaltsanalyse und Vernetzung weit übertrifft. Technische Dokumentation lebt vom präzisen und schnellen Zugriff auf relevante Informationen. Embeddings ermöglichen es, Bezüge innerhalb umfangreicher Dokumentenmengen herzustellen, unabhängig von deren Format oder Struktur. Beispielhaft kann eine Suchanfrage nicht nur exakte Wörter finden, sondern verstehen, welche Texte thematisch verwandt sind, selbst wenn sie andere Begriffe verwenden.
Dies fördert nicht nur die Benutzererfahrung, sondern erhöht auch die Qualität der Dokumentation durch verbesserte Vollständigkeit und Aktualität. Der Kern des Embeddings-Konzepts liegt in der Repräsentation von Texten als Punkte in einem sogenannten latenten, mehrdimensionalen Raum. Hier steht jede Dimension für einen bestimmten semantischen Aspekt, dessen genaue Bedeutung oft nicht explizit bekannt ist. In der Praxis arbeiten moderne Modelle mit Hunderten bis zu Tausenden solcher Dimensionen, sodass die darin enthaltenen Informationen extrem differenziert und detailliert sind. Wenn zwei Texte in diesem Raum nahe beieinander liegen, gilt ihre Bedeutung als sehr ähnlich.
Das macht Embeddings besonders nützlich für Anwendungsfälle wie das automatische Clustern von Dokumenten, die thematische Navigation oder die automatische Verlinkung zusammenhängender Seiten. Ein weiterer spannender Aspekt ist die Möglichkeit, durch mathematische Operationen zwischen diesen Vektoren neue Bedeutungsbeziehungen zu erkennen. Ein berühmtes Beispiel ist die sogenannte Word2vec-Formel, die zeigt, wie Konzepte wie Geschlechterbezüge im semantischen Raum abgebildet werden können. Für technische Redakteure heißt das konkret, dass in Zukunft Suchfunktionen und Empfehlungssysteme auf Dokumentationswebsites deutlich intelligenter und leistungsfähiger gestaltet werden können. Statt starrer Schlagwortlisten bieten embedding-basierte Systeme eine semantische Suche, die auch ähnliche oder verwandte Themen erkennt und vorschlägt.
Dies erhöht nicht nur die Zugänglichkeit von Wissen, sondern steigert auch die Nutzerzufriedenheit. Technisch gesehen sind Embeddings durch Cloud-Dienste und spezialisierte APIs heute leicht zugänglich. Anbieter wie Google mit ihrem Text-Embedding-004-Modell oder Voyage AI mit voyage-3 liefern fertige Lösungen, mit denen Entwickler und technische Redakteure schnell experimentieren und ihre Dokumentationsprojekte bereichern können. Dabei variieren die Modelle im Umfang der Eingabe, von wenigen Hundert bis zu mehreren Zehntausend Tokens, sodass selbst umfangreiche Dokumentenseiten in einem einzigen Embedding abgebildet werden können. Der Einsatz dieser Technologie ist weder teuer noch besonders rechenintensiv im Vergleich zur Textgenerierung durch große Sprachmodelle.
Einmal trainiert, benötigt die Erzeugung von Embeddings nur verhältnismäßig wenig Rechenleistung, was auch unter ökologischen Gesichtspunkten ein Vorteil ist. Dennoch bleibt der Trainingsaufwand ein Faktor, da die Modelle auf umfangreichen Textkorpora basieren, die mit hohem Energieaufwand verarbeitet wurden. Eine praktische Umsetzung findet sich beispielsweise in der Erweiterung von Sphinx, einem beliebten Tool zur Erstellung technischer Dokumentation. Mit einer einfachen API-Integration lassen sich für jede Dokumentationsseite Embeddings erzeugen, die anschließend in einer lokalen Datenbank gespeichert und für Ähnlichkeitsvergleiche genutzt werden können. Über lineare Algebra und Kosinus-Ähnlichkeit kann ermittelt werden, welche Dokumente thematisch miteinander verwandt sind, wodurch intelligente Empfehlungen und Verlinkungen generiert werden.
Die Ergebnisse solcher Anwendungen zeigen, dass Embeddings in der Praxis zuverlässig verwandte Inhalte erkennen und somit die Nutzerführung verbessern. Selbst bei umfangreichen und komplexen Dokumentationssystemen lassen sich so relevante Querverweise automatisiert pflegen, was die Wartbarkeit und Aktualität von Dokumenten erheblich erleichtert. Neben der Dokumentation eröffnen Embeddings vielfältige Anwendungsmöglichkeiten. Sie spielen eine Schlüsselrolle im Bereich der semantischen Suche, Chatbots, Übersetzungssysteme und sogar in der Analyse von Bildern und Videos in multimodalen Modellen. Die Zukunft der technischen Kommunikation wird daher maßgeblich von der Weiterentwicklung und Integration dieser Technologie geprägt sein.
Nicht zuletzt stellt sich die Frage, wie Communities und Unternehmen in Zukunft mit Embeddings umgehen wollen. Eine Vision ist, dass alle öffentlich zugänglichen Dokumentationen die dazugehörigen Embeddings frei bereitstellen, sodass Entwickler eigenständig innovative Dienstleistungen und Schnittstellen darauf aufbauen können. Dies könnte die Art und Weise, wie Wissen erschlossen und genutzt wird, radikal verändern. Abschließend lässt sich festhalten, dass Embeddings für technische Redakteure und die gesamte Dokumentationsbranche ein unterschätztes Werkzeug darstellen, das enormes Potenzial bietet. Durch die Fähigkeit, Texte in einem mathematisch interpretierbaren semantischen Raum abzubilden, wird der Umgang mit großen Dokumentenmengen effizienter, intelligenter und benutzerfreundlicher.
Während die Faszination für KI-Textgeneratoren ungebrochen ist, sollte der Blick auch auf diese essenzielle Technologie gerichtet werden, die im Hintergrund die Grundlage vieler Innovationen bildet und noch lange nicht ausgeschöpft ist.



![Solving Scala's Build Problem with the Mill Build Tool [video]](/images/A7FF83C3-5FD6-4D3E-BB45-4ECB3768C3B7)